
新HPCの歩み(第257回)-2007年(j)-
|
牧本次生は、これまでComputer, Communication, Consumerとして別々の産業が興ってきたが、いまやそれがDigital Consumer Productsに収束しつつある状況を指摘した。石川裕は、OSやミドルウェアの問題とともに、いわゆるT2K計画についても述べた。 |
ISC2007(続き)
9) Thomas Sterling “Multicore—the Next “Moore’s Law”
28日にTom Sterlingが再び登場し、マルチコアに絞って論じた。以下その抜粋である。
|
2007年はマルチコアの元年と言われるであろう。これまでのマイクロプロセッサの時代は、マルチコア/ヘテロの時代に移りつつある。 (1) マルチコアとは何か マルチコアの動機は4つある: (a)拡大したサイズと密度を活用するために (b)チップあたりの機能ユニット(空間的効率)を増加するために (c)演算あたりのエネルギー消費を制限するために (d)プロセッサの複雑さの増加を制約するために マルチコアから来るチャレンジがある。 (a)多重スレッド並列性の有効利用を前提としている。並列計算モデルや並列プログラミングモデルが必要。 (b)メモリ・ウォールを悪化させる。メモリバンド幅、レイテンシ、L3キャッシュのフラグメンテーション (c)ピンがネックになる。ピン数の増加もピン当たりのバンド幅もあまり改善されていない。 (d)プロセッサ間を有効に調整するメカニズム(同期、排他制御、コンテキスト切り替え)の必要性。 ヘテロなマルチコアのアーキテクチャ(違うタイプのプロセッサの結合)もある。各々は異なる動作モードに最適化されている。そのため、n個のプロセッサを組み合わせたとき、n倍以上の性能向上がある。 従来もGPUやネットワーク制御装置などのコプロセッサがあったが、専用目的の要素を一般的なアプリに応用する努力が行われている。 他方、特定の目的のために設計されたアクセラレータがあり、複数の計算のクラスのある種のクリティカルな側面を加速する。IBM CellやClearSpeedのSIMD型アレープロセッサなどである。 (2) HPCのマルチコア利用者の直面する根本的諸問題 (a) マルチコアは今後10年のMooreの法則の進歩を架橋できるか? (b) ピンやキャッシュは、今後のマルチコアの有効性の弱点とならないか? (c) 何かの革新的なアルゴリズムのテクニックがこの好機を逃さず、マルチコアのチャレンジに答えうるか? (d) プログラミングモデルやそれをサポートするシステムソフトウェアが、マルチコア構造のユニークな性質や特質を活用するように変わっていくだろうか? (3) メニーコア 一つのコアを単純化し、チップ上に多数搭載したものを特にmanycoreと言う。メニーコアは今に始まったわけではない。1993年にはIBMのPeter KoggeによりExecubeが作られた。これは一種のPIMであった。おそらく最初のマルチコアであろう。 (4) 最近のマルチコア・メニーコア IBM BlueGene/Lのノード、AMD Opteron、Intel Xeon Clovertown、Sun UltraSPARC Niagara、Sun UltraSPARC Niagara II、Cell Broadband Engine、IBM Cyclops-64 Multi-core Chip、Intel Tera-scale Processor、ClearSpeed CSX600 アクセラレータなどを挙げ、基本パラメータを詳しく述べた。IBM Cyclops-64 Multi-core Chipは知らなかったが、75プロセッサからなり、組み込みDRAMや通信装置がチップ上にある。プロセッサはPIM型のデザインで3-operand load-store ISAを持つ。命令型は60。 (5) マルチコアは、次の10年のMooreの法則の進展を架橋できるか まず、空間的スケーリングへの制約がある。チップ内、コア間の通信(コア数の1乗以上で増加)、各コアのコンテキスト状態を記憶するオンチップメモリ、レイテンシ隠蔽のための資源(クロック周波数、チップ上レイテンシとともに増加)、チップのI/Oピンのための面積、キャッシュサイズ、共有キャッシュのポートなどである。 すでに8コアのチップまである。もし毎年2倍になるとすると、2012年には128コアが出現。 問題はキャッシュコヒーレントにできるかということである、たぶんできるだろうが、他のキャッシュにアクセスすることになり、高価。たとえば、core 1からのデータ要求がL1キャッシュミスを引き起こしたとすると、要求はL2キャッシュに送られる。もしこの要求がcore 2のL1データキャッシュの修正されたラインにぶつかるとすると、ある種の内部的条件によってはcore 1に誤ったデータを返すことになる。64 coresでこれが起こったらどうなるか。1024なら? 128個の、並行しているが異なるメモリ参照のメモリレイテンシを、プリフェッチにより隠蔽できるか? マルチコアプロセッサ上のMPIも問題である。 (6) マルチコアに対応するための従来の戦略 これまでの法則として、L2/L3 cache sizeの増大、チップのI/Oバンド幅の増加、”weaver”(機織り?)チップによりメモリバンド幅を集約、Job stream parallelismの活用など。 (7) 並列処理の「黙示録の四騎士」
[新約聖書黙示録6章1-8節では、小羊(キリスト)が第一の封印を解くと白い馬が、第二の封印を解くと真っ赤な馬が、第三の封印を解くと真っ黒な馬が、第四の封印を解くと蒼白い馬が現れる。4匹の馬は、戦争、内乱、死と飢餓、悪疫などを象徴する。図はスライドからで、Viktor Mikhailovich Vasnetsovの作。この4匹の馬の象徴は旧約聖書ゼカリヤ書6章の借用である。ここでは、4匹の馬は、「オーバーヘッド」「レイテンシ」「衝突」「スターべーション」であろう。] (a) オーバーヘッドの説明 (b) レイテンシの説明 (c) 衝突の説明 (d) スターべーションの説明 (8) マルチコアに対する従来の改良的アプローチの限界 (a) チップ上のSMPだけではない (b) 時間的局所性に非常に敏感である (c) ALUを貴重な資源であるかのごとく強調している (d) エネルギー利用の有効性は低い (e) なぜ効率が低いかの本質的な問題に対応していない (f) メモリ・ウォールはますます悪くなる。 (9) 私[Tom]の見解と偏見 (a) マルチコアは、Mooreの法則が成り立たせるための現状のアーキテクチャ的な戦略である (b) マルチコアは80年代後半のSMP技術の単純な復活ではない (c) マルチコアチップはクラスタに用いられるであろう (d) 並列計算標準ソフトウェアの移植は、うまくいかない (10) システムソフトウェアへの重荷 (a) マルチコアチップは種々の実装が実現するであろう (b) プログラム開発者に、特定のマルチコア・プラットフォーム向きにプログラムを開発することを奨励したくない (c) コンパイラやシステムソフトウェアは、抽象的なプログラミングモデルを特定のプラットフォームに翻訳するものでなければならない。 (11) バンド幅の管理 (a) マルチコアは計算のパワーを急速に増大させる (b) マルチコアは共有キャッシュが特徴となるであろう (c) バンド幅の有効利用へのチャレンジ (d) アーキテクチャの補助なしで (12) 疑問 (a) 特定の計算でミスの衝突が最小化できるように、データを正確にぺージ内に配置することができるか? (b) 複数のコアが互いに干渉しないように計算を同期できるか? (c) このような問題を解決するような新たな特徴を付加するようベンダを説得できるか? (13) マルチコアへの二つの戦略 (a) 構造 (b) 実行モデル (14) マルチコアとメモリの融合 (a) ダイをコアで埋めてしまうと、外部メモリとのバンド幅のためにダイ面積を必要とする。 (b) 「メモリ中での処理」局所バンド幅は十分。 (c) Xcaliber Systemの例 (15) Multicore ParalleX Model (a) 局所性のドメイン (b) 分散共有メモリ (c) Split-phase transactions (d) メッセージ駆動計算 (e) マルチスレッド (f) 局所的(ライトウェイトの)制御オブジェクト(?) (g) アドレス変換を組み込んだメタデータ (h) Failure-oriented with micro-checkpointing (i) 動的最適化 このモデルは4匹の馬「オーバーヘッド」「レイテンシ」「衝突」「スターべーション」を解決する。 (16) 結論と私見 (a) Multicore/Manycore/Myriacoreは技術の進歩であり、アーキテクチャの進歩ではない。 — 目的とする最適化機能を考え直さなければならない:ALU利用率、メモリバランス – チップへのバンド幅:チップ間の直接光接続 – 軽いコアアーキテクチャを考え直せ (b) 英雄的なアプリのプログラマにとって、近未来は過去10年と同様であろう — 苦痛、不安、辞任 — 勝利の高揚もあれば絶望の時もある (c) アーキテクチャの構造と固有のセマンティックスの本格的な再考(ハードウェアサポートの仕組み) — 時間的局所性プログラム属性に基づく処理の二つの型(PIM+データフローストリーミング) — 大域的なネーム空間における軽い同期を持つ、拡張されたアクティブ・メッセージ駆動のマルチスレッド実行 (d) 新世代の実行モデルとプログラミング環境に導かれて |

10) 牧本次生 “Impact of Chip Innovations Driving the Computing Power”
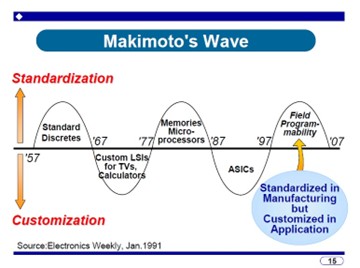
牧本次生(まきもと・つぎお)氏といえば日本の半導体業界の顔ともいえる存在で、1991年に,半導体産業には「標準品化」を重視視する時期と「カスタム化(専用化)」を追い求める時期が10年の周期で繰り返すとの知見を披露,この説は「牧本ウエーブ」として知られている。
その「牧本ウェーブ」の考察に基づき、コンシューマ電子機器のディジタル化はますます進行し、市場の収束をもたらすこと、チップの技術革新により、価値指数は今後の10年に1000倍に増大すること、将来のアーキテクチャにとって、プログラム可能性と再構成可能性はキーであると述べ、ロボットは新しい機会を開くであろうと期待を述べた。
|
これまでComputer, Communication, Consumerとして別々の産業が興ってきたが、いまやそれがDigital Consumer Productsに収束しつつある。PCは年々減少しているが、TVやDVDやDSC(Digital Still Camera)は急激に増大している。IBMは1981年にPCビジネスを始めたが、売り上げは頭打ちになり、2005年にはPCビジネスを中国のLenovoに売却した。
このようにコンピュータ産業の様相はどんどん変化している。AppleのiPodは可搬型音楽プレーヤの新しいトレンドを切り開いた。Microsoftはゲームビジネスを始めた。Dellはフラットパネルテレビを始めた。IBMはゲームチップを3つのメジャーな会社に提供している。 カメラもアナログからディジタルに転換した。日本では東京、大阪、名古屋で地デジが始まった。2011年には1億台のテレビがディジタルに置き換えられる。これは200兆円の経済効果がある。 このようにエレクトロニックスは波状的に変化している(図はスライドから)。1970年頃からanalogue wave が始まったが、1990年頃には第一のディジタルの波であるPCがこれを追い抜いた。しかし、第二のディジタルの波があり、2000年ころにはディジタルな家庭機器やネットワークがこれを追い抜きつつある。 チップの技術革新には独自のメカニズムがある。まず、技術革新は不連続だということである。1947年にBell研でトランジスタが発明されたが、1958年のKilbyや1959年のNoyceによってICが発明された。そして、1971年にはIntelによってマイクロプロセッサが発明された。そして、技術革新は指数的であるということである。1965年のMooreの法則がそれを示している。そして、私[牧本]が1991年に提唱したように、技術革新は周期的である。 これらの変化はPS-2のチップの1999年から2004年までの変化をみるとよく分かる。1999年にはEmotion Engineが240mm2で、Graphic Synthesizerが279mm2で2つのチップからできていたが、2004年には両者が86mm2の一つのチップに載ってしまった。SoC (System on Chip) のインパクトは大きい。前はボードに5個のチップでできていたものが、今や一つのチップにすべて収まっている。しかも性能は4倍である。しかし反面、開発のコストは急激に増大している。 私は1991年に半導体の動向が10年ごとに交代していることを見いだし、牧本ウェーブと呼ばれるようになった。1957年から1967年までは標準化のフェーズであったが、1967年から1977年頃まではテレビや電卓のためにカスタム化の時代となった。1977年からの10年は、メモリやマイクロプロセッサの標準化の時代になった。1987年からの10年はASICが盛んになり、再びカスタム化の時代になった。1997年から2007年はField Programmabilityが重要視され、再び標準化が優勢となった。この時代は、製造としては標準化されているが、応用ではカスタム化されているという特徴がある。今後どういう時代になるであろうか。 では、なぜField Programmabilityが重要なのだろうか。それは、従来の製品が3年から5年の寿命を持っていたのに、新しいディジタルなコンシューマ機器は寿命が1年前後と短く、Field ProgrammabilityはMUSTである。FPGAは、医療画像処理、HPC、データ解析など広い範囲に応用されている。 私(牧本)が提示するウェーブの周期は振り子に例えられる。標準化に振れているとき、それを推し進めているのは新しいデバイスや新しいアーキテクチャである。逆にカスタム化の方向に押しているのは、差別化、高性能化、省電力化である。カスタム化の方に振れているとき、それをカスタム化の方向に押しているのは、デザイン・オートメーションとデザイン方法論である。逆に、標準化の方向に押しているのは、市場に出るまでの時間の短縮化、開発費用、運転の効率化である。 さて、この周期を振り子にすると、どのくらいの長さが必要だろうか。勿論、重力加速度は地上と同じとして。答は8.6光年である。[牧本氏はこのジョークが好きらしい。] さて、コンピュータ革命の歴史を見てみよう。1950年前後最初にコンピュータができた頃は国に1つもあればよい、と思われた。1960年代になってIBM360が出現し会社に1台ということになった。1970年代にはVAX-11が出現して部門に一台となった。1980年代にはPCの出現により一人に1台となり、その後はどこでもコンピュータということになった。初期のUNIVAC-1と現在の携帯用PCとを比較すると、性能は2万倍になったのに、価格は1000分の一、大きさも電力も10万分の一である。 電気機器の価値指数を (知性) ——————————- (サイズ)×(費用)×(消費電力) で表すと、1940年代から現在まで1018増加している。これは10年に1000倍である。 Cray-1は1976年Cray Research Inc.によって発売されたが、160 MFlopsという(当時としては)とてつもない性能を持っていた。これは、4ゲートのNANDのICを使って組み立てたもので、値段は$6M、重量は5.5 tonsであった。このCray-1の性能は今のiPodと同程度であった。 地球シミュレータは2002年に開発され、40 TFlopsのピーク性能を持っていたが、その1チップベクトルプロセッサは、一昔前の大きな筐体の性能に匹敵している。 それでは今後どうなるであろうか。CELLプロセッサはIBMと東芝とソニーとの共同開発であり、9コアのmulticore chipであり、256 GFlopsの性能を持っている。単精度ではあるが、地球シミュレータの32プロセッサ分に相当する。いつか、卓上の地球シミュレータが出現するであろうか。 将来のインテグレーション密度はどんどん上昇する。2018年にはチップ上に5B transistorsが乗るであろう。しかし、チップの技術はどんどん多様化するである。たとえば、光学センサ、慣性力センサ、外力センサ、表示デバイス、アクチュエータ、RFデバイスなど。特にロボットの知能の進歩は著しい。ロボカップの目標は2050年までに人間とサッカーのできるロボットを開発することである。 まとめると、 ●コンシューマ電子機器のディジタル化はますます進行し、市場の収束をもたらす。 ●チップの技術革新により、価値指数は今後の10年に1000倍に増大する。 ●将来のアーキテクチャにとって、プログラム可能性と再構成可能性はキーである。 ●ロボットは新しい機会を開くであろう。 |
11) John Gustafson “Using Accelerators to Escape the Shackles of 20th Century Software”
Exhibitor Forumでは出展企業が30分ずつ講演したが、 ClearSpeed CTOのJohn Gustafsonの講演が印象に残った。
|
これまでは、Flopsとかストレージとかが主要なコストであったが、今では、プログラマや消費電力やバンド幅である。レガシーコードではなくとも古いアルゴリズムを動かす必要がある。猛烈なトランジスタ数を使いこなす方法論として、 — まずベクトル、次にスレッドを加える。 — 電力予算に対する高い絶対性能を考えると、プログラマが高い効率を実現する圧力が減る。 — 不均一なスレッドに対するロバストな可視化ツールが必要。 20世紀からの3つの足かせ。 — 浮動小数演算、特に64ビット演算は高価なので、演算数をできるだけ少なくするアルゴリズムを使うべきである。 — メモリは高価であり、システムのコストの大部分を占めるので、バイト数が最も少なくなるようにプログラムしなければならない。 — 並列処理は多くのイベントを制御しなくてはならないので困難である。従ってアルゴリズムは逐次処理で表現すべきである。 この足かせは今でもシステムを使う時に影響している。しかし、われわれは意識的にこのような考え方から脱却しなければならない。 21世紀の真実は、トランジスタはゴミのように安いということである。 — 浮動小数演算は実行時間や費用の小さな部分であり、データのフェッチやストアの時間に隠れている。 — メモリはバイトあたり非常に安いので、ギガバイトを遊ばせても気にする必要はない。 — 単一スレッドはデータ並列性を簡単に表現することができる。ヘテロな並列スレッドは、もし完全な可視化ツールがあれば、使いこなすことができる。 古いアルゴリズムをうまく行かせるには、まず線形解法を考えよう。疎行列の疎度がある程度以上なら、密行列の解法を使った方が、演算量は多いが時間は短くなる。 — 最近のIEEE Computerの論文によると、4000×4000行列で非ゼロ率2%の方程式にFPGAを使うことにより、時間を67.3秒から33.8秒に短縮できた。 — しかし、密行列の解法を使えば3秒以下である。メモリは128MB必要だが、今なら$10だ。 — 1970年代のアルゴリズムの新版を作るのに何百時間も使って10倍のスローダウンを実現している。こういう間違ったことすべては無駄だ。 — 対称行列用のコードを作っても演算量やメモリは高々2倍しか得しない。しかし実行時間は増大し、プログラマの努力は大変だ。 ではFFT はどうか。FFTはO(n2)の演算量をO(n log n) まで減少させた。 — 大きなradixを使ったFFTは、演算量は多いが時間は短い。 — このことは最初Cray-1でradix-64のFFTで観測された。昔の「遅い」アルゴリズムは今は速い。 — その理由は、物理的なfetch/storeはFFTでも依然n2なので、データ並列性をハードウェアにより活用することは、演算量を減らすより遙かに重要である。 超省電力のアプローチによってより高いGFLOPSが可能になる。ClearSpeedは32-bitでも64-bitでも最大のGFlops性能を有する。最低の電力は、結局最小の面積に設置できる。 50 GFを実現するのに高い効率が必要でないのは利点。 — 4-core x86なら90%の効率を出さなければならない。 — 将来版の64-bit Cellなら50%の効率が必要。 — 将来版の64-bit GPUなら、10%の効率でよい。 — ClearSpeed boardならわずか6%でよい。 ClearSpeedの省電力性により、プログラマは最適化の必要が減るので使いやすさに通じる。 ClearSpeed CSX600について — 96個のProcessor Elementsのアレイ。64-bit と32-bitの両方。 — 電力効率のため210 MHzという低いクロックレートで動作。 — 論理が47%、メモリが53%。論理の約半分はFPU。すなわちチップの1/4は浮動小数ハードウェアで占める。 — 内部バンド幅は約1 TB/s(Tier 0のことか?) — 1.28億トランジスタ — 消費電力は10W。しかし、DGEMMの実行速度は33 GF。 高いバンド幅は、ベクトル的な(SIMD的な)並列性から来ている。 — Tier 0: PEの演算回路(0.5 GF)からレジスタメモリ(128B)へ。load 2本、store 1本。 — Tier 1: レジスタメモリからPoly Memory (6 KB)へ(以上はPE毎)。 — Tier 2: Poly Memoryから2バンクメモリ(CSX DRAM 0.5 GB)へ。 — Tier 3: バンクメモリからホストのDRAMへ 数学関数(sqrt, exp, sinなど)はTier 1で計算されるので速い。ヘテロなマルチコアシステムを使いこなすには、 — OS, アプリ、コード、ツール、ホストの言語などはできる限り変更しない。 — 特別なマルチコアCPU向きの新しいツールは、可能な限り知っていると思われるものを。 — それらを、すべてのリソースのシステム全体の性能を表示できる可視化ソフトと統合せよ。 — まずデータ並列を使い尽くせ。それからスレッドの管理を。 プログラマに必要なレベルは、 — 命令レベル並列性:自動的(何の苦労も要らない) — データ並列性:ハードウェアのベクトル長がアルゴリズムのベクトル長を越えない限り簡単に表現できる。ただ、”plural” 変数を定義せよ。ちょっとした通信の管理は必要だが。 — スレッド並列性:プログラマは、共有/非共有データ、同期、負荷分散、通信バンド幅、レイテンシ、隠蔽などを考える必要がある。 まとめて、 ●演算量とメモリ量という古い足かせは新しいものに置き換えられた、すなわち、プログラミング(の苦労)、バンド幅、消費電力である。 ●ClearSpeedはこの3つの新しいコストを解決する。Advance boardは、複数のスレッドを管理するのではなく、トランジスタをHPCのベクトル並列性に振り向ける。 ●ClearSpeedのより現代的な特徴は、プログラマに、演算量やメモリは浪費しても、より少ない電力とエネルギーでより少ない時間に仕事を終わらせることを勧告する。 ●今後はヘテロなマルチコアの時代が来る。ClearSpeedは優れた可視化ツールにより、この複雑性を使いこなせるようにする。 |
このあと、このツールのデモと宣伝を行った。
12) John Shalf
マルチコアの問題点はメモリバンド幅だと言われているが、これは嘘だと常識を覆した。家電などの組み込みプロセッサの方が多くの経験を積んでおり、われわれはそれから学ぶべきだと主張した。フォン・ノイマンのモデルを捨て、トランザクション・メモリという新しいモデルに移るべきことを強調した。
13) Julien Langou
マルチコアの時代に数学ライブラリはいかにあるべきかを述べ、密行列線形代数ライブラリの新しい動向について述べた。
14) 石川裕 “System Software, Operating Systema and Middleware Issues”
29日(金)にはこの講演があった。氏は、ペタフロップスのソフトウェアやミドルウェアについて、階層的資源管理、Jittering、メモリ・アフィニティ、電力管理、フォールト・トレランスとファイルシステム、プログラミング環境の問題を指摘し、T2K連合ではこれをどういう方向性で解決しようとしているか、について述べた。
|
まず SCORE System Softwareの特徴について述べた。続いて、2001年当時世界最速のPC clusterであったRWC SCORE Cluster III (Linpack 618.3 GF)を紹介した。現在のSCOREを使った大きなクラスタとしては、理研のSuper Combined Cluster Systemと筑波大計算科学研究センターのPACS-CSがある。 続いて、東大の情報基盤センターにおけるスーパーコンピュータについての歴史を述べ、現在、18.8 TFlops, 16 TB のHitachi SR11000/J2があるが、2008年に新しいスーパーコンピュータを調達する予定である。これはT2K Opern Supercomputerと呼ばれ、150 TFlops, 30 TBのクラスタを予定している。 T2K Allianceとは、東京大学、筑波大学、京都大学の連合であり、この3大学は、それぞれの大学で調達する次のスーパーコンピュータを共通の仕様で入札を行うことに合意した。性能は、筑波大学が80 TFlops、京都大学が66 TFlopsである。通常のアプリのユーザへのサービス業務に加えて、並列プログラミング環境などの先進的研究プロジェクトで協力を進めることが計画されている。
ペタフロップスコンピュータには、ノード構成、ノード数、主記憶、相互接続ネットワークなどについて、いろいろなタイプがあるが、多くの問題がある。 (1) 階層的資源管理 (2) Jitteringの問題—-我々の対策は、グローバル・クロック・ジェネレータから放送パケットを送出し、すべてのシステムプロセスとアプリのプロセスはそれを用いる。 (3) NUMAの問題–メモリ・アフィニティをどうするか (4) 消費電力の問題–150 TFのコモディティに基づくクラスタでも約1.2 MW ($1M/year) (5) フォールト・トレランスとファイルシステムの問題 (6) プログラミング環境の問題 T2Kのアプローチでは、易しいプログラミングとPCクラスタからペタスケールマシンへのプログラム/性能のポータビリティとが保証される。 T2Kのこのような様々なアプローチは、ペタフロップスマシンにとっても有用であろう。 |
15) Microsoft Saxon Night at Castle Albrechtsberg
6月28日(木)の 木曜日の晩は、この会議のメインスポンサーであるMicrosoft社の提供で、バスで20分ほど走ったところにあるザクセン州の古城でパーティがあった。中世の格好をした人が出迎え、演奏や歌や踊りなどいろいろアトラクションもあった。
16) 閉会
29(金)の昼食で会議は終了した。午後は博物館などを巡り、エルベ川沿いでビールを飲んだりした。夜は、Frauenkircheでベルディのレクイエム(死者のためのミサ曲)を聞いた。テレビ中継が入っていたようである。土日はドレスデン空港が改修工事のため閉鎖になり、空港からLufthanzaのバスでLeibzichまで走って飛行機に乗った。この分のマイルはどうなったのであろうか。
次回は、Renoで開催されたSC07について述べる。
 |