
Supercomputing Japan Conference
【Supercomputing Japan 2024を振り返る】プログラム 1日目 基調講演 国立情報学研究所 所長/京都大学 特定教授 黒橋禎夫 氏による基調講演―データ基盤から知識基盤へ―
 |
|
2024年3月12日(火)、13日(水)の2日間、都営新宿線・船堀駅前に位置する「タワーホール船堀」において、「最先端シミュレーションとAI これからのスーパーコンピューティング」をテーマに、量子コンピューティングと大規模言語モデルを取り上げたイベント『SupercomputingJAPAN!2024』が開催された。
プログラム1日目は、10時30分からの開会式に続いて国立情報学研究所 所長/京都大学 特定教授である黒橋禎夫 氏による「データ基盤から知識基盤へ」と題した基調講演が行われている。
黒橋氏が所長を務めるNII(国立情報学研究所)は、大学共同利用機関法人 情報システム研究機構の中の1つの研究所である。このNIIは、研究と事業を両輪として情報学による未来価値を創成するというミッションを持っており、情報学という新しい学術分野での「未来価値創成」を使命とする国内唯一の学術総合研究所だ。今回の基調講演では黒橋氏は以下のように語った。
NIIは教職員が7名、事務職員が70名、特任教授が200名、有期雇用職員が300名でスタートした、500名規模の研究機関である。年間予算は130億円程度で運営されているが、そのほとんどは学術情報ネットワークSINETの方針運営等にかかっている。
研究については4つの研究系で構成されている。それは大学で言う専攻に相当するものとなっており、情報学プリンシプル系と、ネットワークやアーキテクチャの研究を行っているアーキテクチャ科学研究系、自然言語処理やコンピューターディジョンなどのコンテンツ科学研究系、人と人間と社会との関係を考える情報社会相関研究系の4つの研究系に分かれており、その他、大学院の教育も行っている。
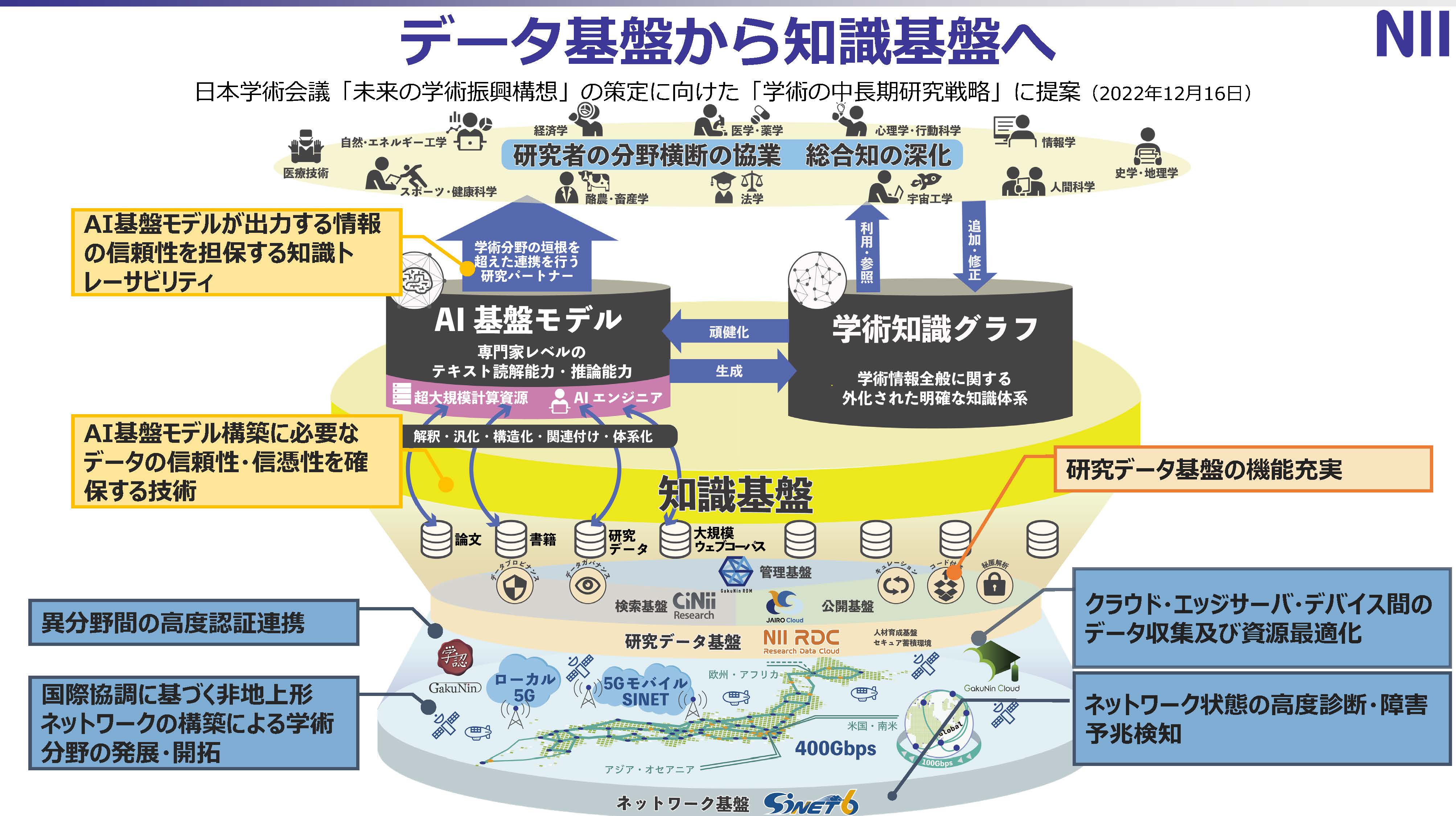
これによって全国の大学や研究機関の研究教育の環境を高度化することを行っており、一番下のレイヤーとしてはネットワークである。その上のレイヤーに研究データ基盤があり、現在様々な新たな機能開発を進めているこれによって、研究のライフサイクル全体を試験することにより、オープンサイエンスにもつながっている。
NII事業の全体像として最下部のレイヤーであるネットワーク基盤は、ストレスなく使えることが重要であるため、2022年4月からSINET6を運用している。このSINET6は、日本全国を400Gbpsの通信回線でメッシュ上にサービスしており、災害等が発生した際、どこかの回線が切断されたとしても、その迂回路ルートをダイナミックに見つけ、大きな途切れなくネットワークを運用できる。また、全世界とも100Gbps以上の通信回線で接続されており随時アップデートを行う他、2年後に向けて、SINET7の設計を進めている。
その上のレイヤーになる研究データ基盤は2017年から開発を開始し、2021年から運用フェーズに入っている。この研究データ基盤は大きく3つの機能を持っている。1つがデータ公開基盤であり、JAIRO Cloud(ジャイロクラウド)と呼ぶシステムでにより成果論文や研究データをここにアップロードしている。
機関リポジトリ(研究成果を収集・保存・発信する器)のクラウドサービスであるJAIRO Cloudについては、2023年にようやく全国への展開、新しいシステムへのリプレースが進み、現在、800機関がJAIRO Cloudを利用している。今後、2024年夏をメドに機能拡張や問題のフィックスが完了する予定となっている。
もう1つがデータを検索する基盤として、CiNii Researchがある。これも電子的にさまざまなコンテンツがあるわけであるが、現在それを集約していくということを行っている。
3つ目がデータ管理基盤であるGakuNin(学認) RDMだ。データ収集装置や解析用計算機、東京大学等にあるMDXとも連携して研究者が様々な共同研究におけるデータの管理や共有をスムーズに行えるような環境を作ろうとしている。
このGakuNin RDMは、現在100機関以上の契約がある。東京大学におけるムーンショットの研究等、大規模に使っていくことも始まっており、今後はユーザーの声を聞きながら、この機能の拡張を進めていきたい。
同時に、2022年の夏から文部科学省の予算によってAI等の活用を推進する、研究データエコシステム構築事業もスタートしている。
これは東京大学、大阪大学、名古屋大学、理化学研究所の4つに共同の実施機関となってもらい中核して進めているので、先ほどのような研究データ基盤をよりしっかりと構築して普及させていくということを目的にしているものでシンポジウムなども行っている他、実際に使っていただき、その声を聞きながら、システムを改善していくサイクルを回していく。まさにエコシステムを構築していくところであり、そのためにユースケース創出事業というものを行っている。
これは随時受付をしており、2024年度分も現在募集している。全国的な研究データ基盤を活用して、異なる分野間でのデータ連携をすることを前提としたAIデータ駆動化研究のシールというユースケースの創出を目指した課題を募集。人類社会科学と理系の計算科学等の融合研究から多数提案いただき採択している。
2025年度からの新規候補から公的資金で支援を受けた研究に対する論文や、その根拠となるデータを併せて、即時オープンアクセスにしているということが国の方針になっており、NIIで構築しているRPC(リサーチデータクラウド)が、その1つの中核的な基盤と位置づけられている。
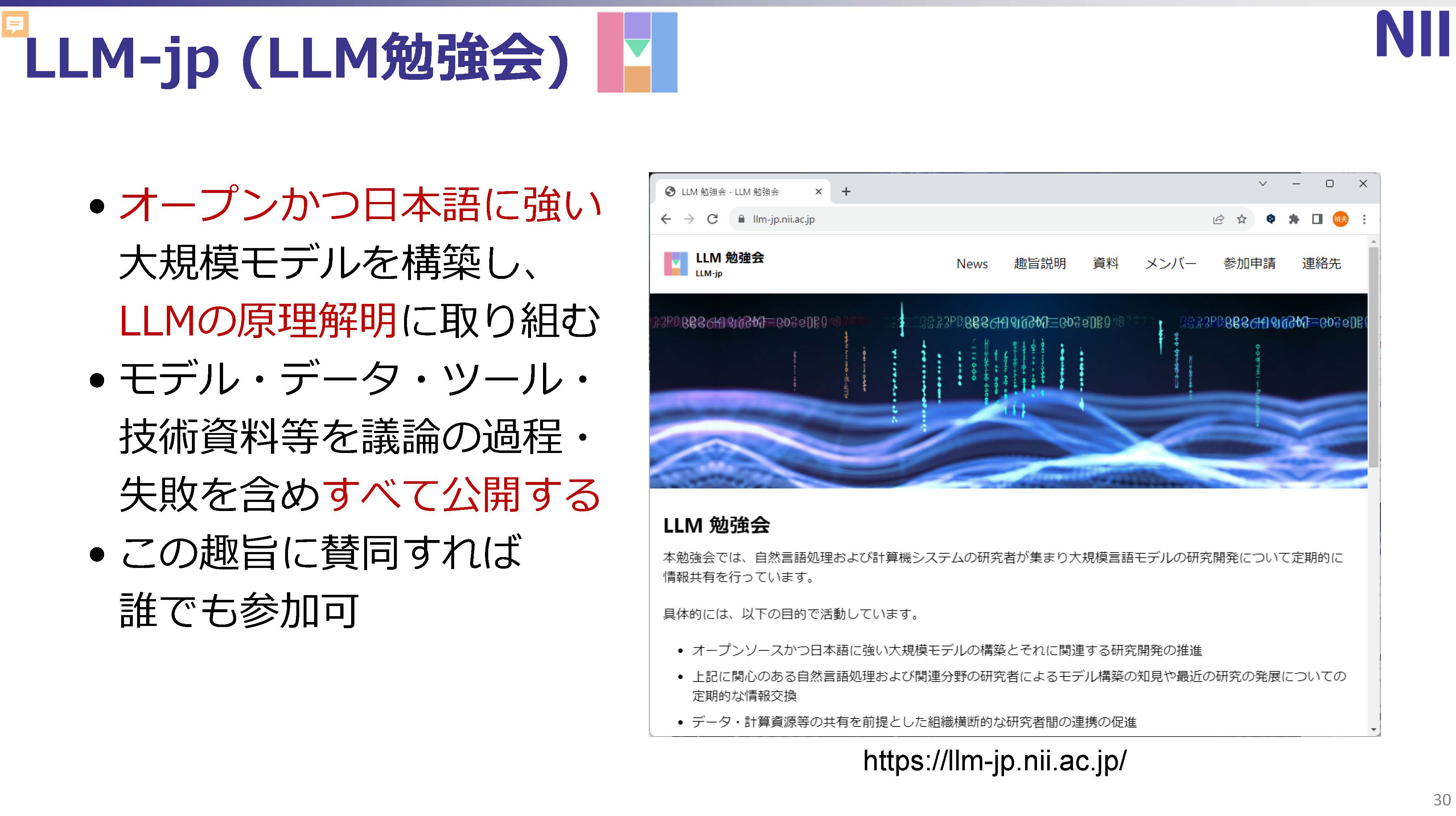
次に、NIIの中核をなす、オープンかつ日本語に強い大規模言語モデル構築とその原理解明に取り組む組織であるLLM-jpについて紹介したい。
 |
 |
ChatGPTの開発で話題になっているOpenAIは2015年に設立された研究所で、マイクロソフトも出資している企業だ。大規模言語モデルであるChatGPTで何をやっているかというと驚くほどシンプルな構造だ。学習用のコーパスが与えられたときに、それを順番に見ていき、その次の単語をコーパスの出現の通りに予測するといった学習をしているのが根本的なところである。
自動翻訳やAI翻訳の前に存在していた機械翻訳には、統計的機械翻訳という時代があり、大規模な元の言語、例えば日本語から英語に訳す場合には対訳のデータを大規模に準備していました。そこで統計的なモデルの研究が進んだわけであるが、ニューラルネットワークは大規模なデータが必要のため、機械翻訳の研究で蓄積された対話コーパスという資産が、今につながる研究になっている。そして、そこにつながる大きな発見として、アノテーションがある。
当初出てきたアノテーションはかなり自然なものである。機械翻訳において目的言語を一単語ずつ生成していくわけであるが、その時に次の単語として何を生成するかを考える際に、原言語のどのあたりに注目すればいいかという、ある種の系統を計算する枠組みがアノテーションと呼ばれるものだったわけだ。
これがその後、大幅に精緻化され、目的言語と原言語の間で大事な部分を探すだけではなく、原言語の中、目的言語の中、それぞれでもアノテーションとして単語間の関係を捉えていく。それをやったものが、トランスフォームと呼ばれるモデルである。
面白いのは、原言語内、目的言語内それぞれでのアノテーションが、ある種この文の理解の状態を作り出しているが、OpenAIはこのデコーダー側、つまり目的言語の単語を一単語ずつ出力していく方法に着目、そのモデルを元のトランスフォーマーモデルから、10倍、100倍と大きくしていったのである。そこで、それをGPTと呼ばれるわけであるが、それが最終的に現在の大規模言語モデルになっていく。
生成AIと呼ばれるのは、このような形で1単語ずつ、翻訳の時に出てくるわけであるが、そういう形で一単語ずつ単語を生成していくことで「生成AI」と呼ばれるわけである。その中で、パラメータを大きくしていくと次の単語の予測がされるのである。これがChatGPT-3.5モデルで、これを対話ではなくデータで学習するのがChatGPT-4というわけだ。
なお、ChatGPT-3.5で使われている日本語コーパスは、全体の0.1%程度。英語コーパスが90%を超えており、日本語はその程度しか入っていない。
逆に、これでそこまで賢いということに驚かされるといえるが、全体の0.1%程度ではやはり日本の様々な活動や文化についての知識は少ないわけであり、日本語の理解力や生成能力も英語に比べれば低いといえる。つまり、このようなシステムがスタンダードになっていくと質問の答えとして日本の活動や文化が埋没してしまうという懸念もある。
また、セキュリティの問題も気になるところであり、さまざまな対策も考えているとはいえ、日本の様々な情報やアセットが外国企業に寡占状態で活用されることも経済安全保障を受けなければというところだ。
このような問題意識を持つことで、言語モデルを実際に作ろうと考えたのであるが、モデルやデータ、ツール、技術仕様、それから機能の確定、失敗等を含めて全て公開することを前提に、「賛同していただければ参加ください」と2023年8月からJHPCをスタートさせた。
計算資源がまだ無かったためにLLM-jpは勉強会という形で自然言語処理の研究者が30名程度でスタートしたのであるが、2023年からmdx(データ活用社会創成プラットフォーム)のサービスがスタートしたところでもあり、NIIと理化学研究所とmdxを運用しているJHPCNの3者で資金を出し合い、mdxの資源を確保して、2023年10月に130億パラメータのモデルを公開した。
2023年11月には産総研(産業技術総合研究所)のABCIにおける新薬プログラムを採択し、ChatGPT3級モデルの学習を体験して様々な問題を明らかにした。
2024年になり、GiNaCという経済産業省が行っている計算支援を支援するプログラムに参加をし、4月から4ヶ月間程度をかけてパラメータで2トリリオントークぐらいの学習しようと準備を進めている。
30名でスタートしたLLM-jpは既に1000名を超える参加者になっている。様々な情報を取得しているのは500名程度、アクティブに発言をしたり、実際のコーディングや作業に参加したりしているのは100名程度の規模となっているがSlackをベースに活発な活動を展開しているのが現状の活動状況だ。
今後、情報活用のメインはデータ基盤から知識基盤へと移っていく。日本語についても良質なデータを増やしていくことで、正確性が高い大規模言語モデルを構築できるだろう。NIIとしても多くの知識や研究者をつないで総合知による価値創出に貢献していきたい。
 |
講演のスライドはこちらからダウンロード可能です。
追記:
Supercomputing Japan 2025は2025年2月3日月曜日~2月4日火曜日の会期でタワーホール船堀で開催いたします。