
HPCの歩み50年記事一覧

スパコンリスト日本

記事寄稿について

2022年のエクサスケールに向けたアルゴンヌの取り組み
Tiffany Trader

パンデミックの影響で開催が危ぶまれていたHPC User Forumにおいて、アルゴンヌ国立研究所が2022年のエクサスケール・クラスのスーパーコンピュータ「Aurora」の導入に向けて準備を進めていることが明らかになった。
エクサスケール・コンピューティング・プロジェクト・ディレクターであるDoug Kotheは、アルゴンヌ、オークリッジ、NERSCの「初期のエクサスケール・ハードウェア」の一部をレビューし、アルゴンヌ国立研究所のプロジェクト・ディレクター兼オペレーション担当副ディレクターのTi Leggettは、先月発表され、現在研究所に設置されている「Polaris」システムについて説明した。
 |
|
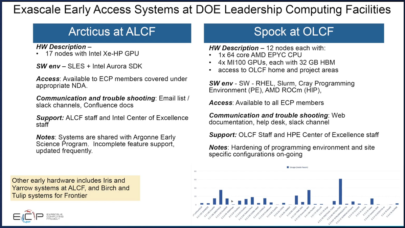
「Arcticus」は、昨年秋にアルゴンヌ国立研究所に納入された、Intel Xe-HP GPUノードを搭載したアルゴンヌ・リーダーシップ・コンピューティング・ファシリティ(ALCF)のアーリーアクセスマシンの名称である。この17ノードのシステムは、将来(2022年)のスーパーコンピュータ「Aurora」の過渡的な開発マシンとしての役割を果たしており、システムの計算バックボーンとなる次期GPU「Intel Xe-HPC」(「Ponte Vecchio」)の代役を務めている。ALFCの初期のハードウェアには、他にも「Iris」や「Yarrow」といったシステムや、「Crux」と呼ばれる1ラックのCray EXテストベッドがある。
一方、オークリッジ・リーダーシップ・コンピューティング・ファシリティ(OLCF)では、今年登場する異機種混合のHPE-AMD「Frontier」エクサスケール・スーパーコンピュータに向けて、「Spock」が研究者をサポートしている。「Spock」は、12ノードのHPE Apollo 6500 Gen10 Plusシステムで、各ノードに64コアのAMD Epyc Rome CPU1基とMI100 GPU4基を搭載している。
Kotheは、「アプリケーションとソフトウェアの両方のチームが、経験を積んでいます。驚くことではありませんが、彼らは問題点や必要な機能、修正すべきバグを発見しています。我々のベンダー(今回はインテル、HPE、AMD)間での多くのやりとりがありました。」と述べている。
Leggettは、先日発表されたスーパーコンピュータ「Polaris」(ピーク時の倍精度44ペタフロップス)についてさらに詳しく紹介しており、HPE Apolloシステムは、アルゴンヌが現在使用しているメニーコアのIntel Knights Landingプラットフォームである「Theta」から、ヘテロジニアスCPU-GPUベースのHPE XEプラットフォームである「Aurora」への橋渡しとなるだろうと述べている。
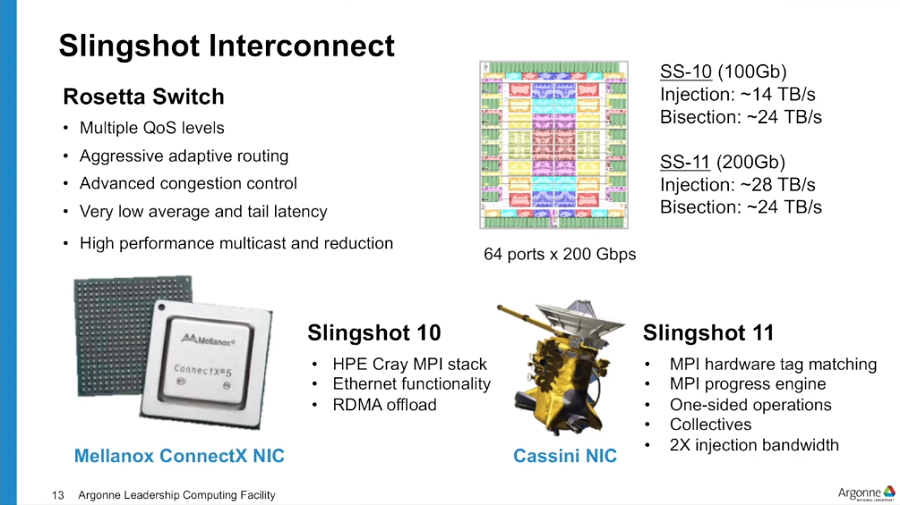
以前にも取り上げたが、アルゴンヌで現在構築中の「Polaris」は、560個のAMD Epyc Rome CPUと2,240個のNvidia A100 GPUを40台のHPE Apollo Gen10ラックに搭載し、HPEのSlingshotネットワーキングで接続している。
「Polaris」は、まずHPE Slingshot 10を使用し、来年にはSlingshot 11へのアップグレードを予定している。Slingshot 11は、100 Gbpsから200 Gbpsへと性能が向上し、「Aurora」が採用する技術と同じものだ。「Slingshot 11は、MPIに最適化されたコレクティブや最適化機能も強化されています。」とLeggettは述べている。
 |
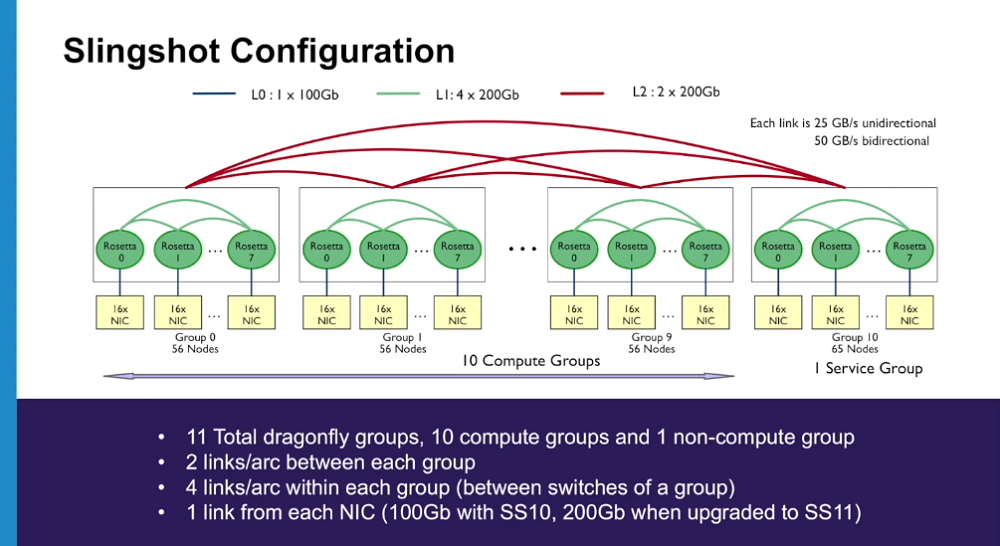
「Polaris」のSlingshotネットワーキングは、11のローカルDragonflyグループに編成され、そのうち10本は演算用、11本目は非演算用ノードをに接続されるとLeggettは言う。各コンピュートグループには4つのラックがあり、各ラックには7つのApolloシャーシがあり、シャーシごとに2つのノードがある。合計すると、各ローカルグループには56台のノードがあり、Dragonflyのトポロジーで接続されている。 11番目のグループには管理ノードとゲートウェイノードがあり、後者はLustreファイルシステム(GrandとEagle)への接続を提供する。
 |
最後にLeggettは、「Polaris」が「Aurora」への道筋を提供する方法を、以下の図にまとめて短い講演を終えた。
 |
「太字になっているのは、Auroraで使用される技術に直接関連するものです。」とLeggett。「太字のものはすべてAuroraに採用される技術に直結しています。マルチGPU環境は、特に太字ではありませんが、非常によく似たプラットフォームです。2022年のエクサスケールに向けて、ユーザのスケールアップを支援する上で、非常に適したリソースになると思います。」と述べている。
HPC User Forumでは、IntelのチーフアーキテクトでAuroraのテクニカルリードを務めるRobert Wisniewskiが、「Aurora」の詳細を以下のスライドで紹介した。(なお、ラック数は正確な数ではないとのことです))
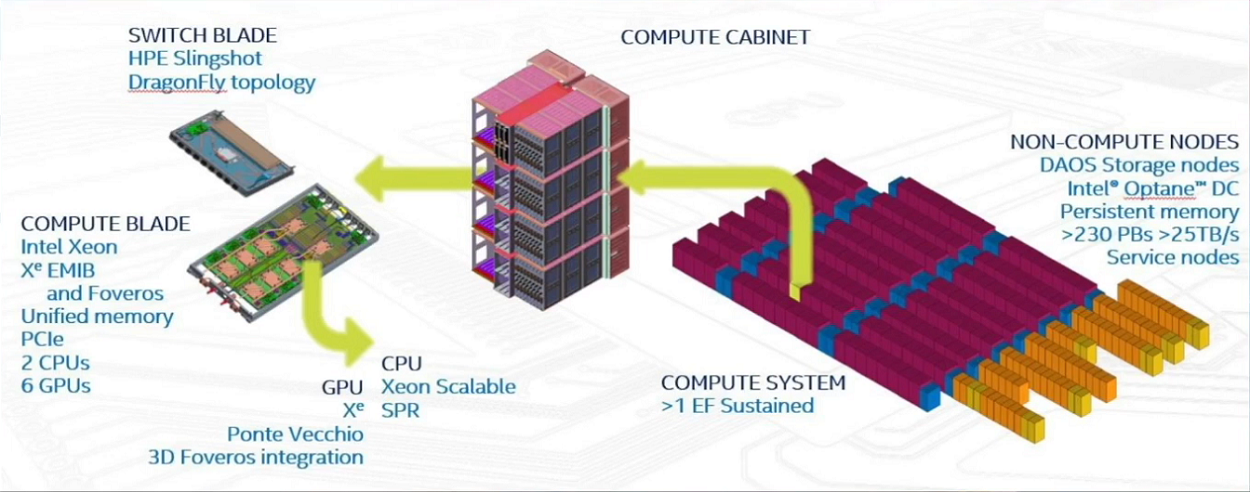 |
| 「Aurora」システムのアーキテクチャ(出典:Intel) |
「Aurora」のコンピュートノードには、IntelのCPU「Sapphire Rapids」(「Intel 7」ノード)とGPU「Xe Ponte Vecchio」が搭載される。TSMC社のN5プロセス技術で製造されたXeコアを搭載したPonte Vecchio GPU A0シリコンは、単精度または倍精度で理論上約45テラフロップスの性能を発揮する(Hot Chipsカンファレンスでは、アーキテクチャレートはFP32とFP64で同じであると述べられた)。
保守的な性能効率を例えば70%とすると、Ponte Vecchio GPUはそれぞれ31.5HPLテラフロップスを提供することになる(!)。しかし、「Aurora」システムの設計仕様では、ノードあたりの性能が130テラフロップス以上となっており、GPUあたりのピークテラフロップスは「たった」21テラフロップス程度となる。これに9,000(+)ノードを掛け合わせると、1.17(+)エクサフロップスとなる。「Aurora」のピーク電力は60MW以下とされており、「Frontier」のスペック上のパワーフットプリントの2倍以上となっている。
特別イベント

寄稿者
![]() 西克也
西克也
西克也はフェアチャイルド社、クレイ・リサーチ社、ベストシステムズ社など、30年以上に渡ってHPCに関する仕事に従事している。Hpcwire Japanの編集長として記事の作成と翻訳を行っている。
![]() 島田佳代子
島田佳代子
1999年~2007年まで英国在住。2001年よりスポーツ、旅、ビジネス、映画など幅広いジャンルで執筆活動を開始し、Hpcwire Japanでは主に日本のHPC業界が世界に誇る研究者、開発者の方々のインタビューを担当。
![]() 小柳義夫
小柳義夫
小柳義夫氏は40年以上に亘ってHPCに携わってきた研究者であり、日本のHPC業界における生き字引として有名。現在 高度情報科学技術研究機構に所属し、産業界のHPC推進にあたっている。
![]() 小西史一
小西史一
小西史一は、理化学研究所、東京工業大学においてHPCおよびバイオインフォマティクスに関する研究と教育に携わってきた研究者。2012年からフォトグラファーとしての活動を開始し、現在はIT技術・セキュリティのコンサルティング業務に携わっている。