
新HPCの歩み(第192回)-2002年(h)-
|
ISC2002で発表されたTop500では地球シミュレータが堂々1位を占めた。2位はASCI Whiteであった。Dongarraはグリッド環境での数値ライブラリについて論じ、Donna CrawfortはLLNLの50年の歴史を語った。日本電気のMasao Fukumaは地球シミュレータのハードとアーキテクチャについて講演した。 |
ISC2002
1) はじめに
前年からISC (International Supercomputing Conference)と名前を変えたHans Meuer主催の会議は17回目の今年、2002年6月19日(水)~22日(土)にライン川の支流ネッカー川沿いのHeidelberg Kongresshausで昨年に続き開催された。筆者は初めてこのシリーズに参加した。古めかしい建物で大会議室も一つしかなく、2階の廊下を展示に使っていた。参加者は367人、展示は25件である。SCとは違い、すべて招待講演で、single trackであった。
 |
|
筆者が参加した理由の一つは地球シミュレータがTop500のトップを取りそうだったからである。渡辺貞はじめ多くの日本電気関係者や佐藤哲也センター長も出席していた。会期中に佐藤センター長と「哲学者の道Philosophenweg」を歩きながら、グリッドが地球シミュレータの敵ではなく、相互に協力し合えるものであることを力説したが、ご理解いただけたかどうか。写真は向かって左から渡辺貞氏、筆者、佐藤哲也氏。
会期中6月18日、街中でトルコ人(ドイツには多い)が自動車に箱乗りして騒いでいた。何かと思ったら、日韓開催のFIFAワールドカップの決勝トーナメント1回戦(宮城スタジアム)で、トルコが日本を打ち破ったとのことであった。会議のイベントとしてネッカー川のディナー・クルーズがあった(後述)。
主要なプログラムは以下の通り(HPCwire 2002/2/8)。残念ながらほとんど記憶にない。
|
木曜基調講演: Indexing the Web: A Challenge for Supercomputing |
Monika Henzinger, Director of Research, Google Inc. |
|
Presentation of the 19th TOP500 Supercomputer List |
Hans Werner Meuer, Jack Dongarra, Erich Strohmaier |
|
Genetic Engineering - the Utopian Idea of Perfect Human Beings |
Jens Reich, Max- Delbrück Center of Molecular Medicine, Berlin |
|
Panel Discussion : “Innovative HPC–Applications: Challenge for Software?” |
Chair:Wolfgamg Nagel, TU Dresden Panelists: Arndt Bode (TU München), Frank Götz (Mermaid Pharmaceuticals), Christoph Gümbel (Porsche), Monika Henzinger (Google), Helmut Merke (KarstadtQuelle), Rick Stevens (Univ of Chicago) |
|
Facing Petaflops Computing – Device Technology and Applications |
Masao Fukuma, NEC Tokyo, and Rick Stevens, University of Chicago |
|
Grid Computing: Status in Europe and in USA / Numerical Libraries and the Grid |
Wolfgang Gentzsch, Sun Microsystems Ian Foster, University of Chicago, Domenico Laforenza, CNUCE, Jack Dongarra, University of Tennessee |
|
HPC Manufacturers: 16 Short Product and Development Presentations |
|
|
金曜基調講演: High Performance Computing, Computational Grid, and Numerical Libraries |
Jack Dongarra, University of Tennessee, USA |
|
The Grid: Enabling Resource Sharing within Virtual Organizations |
Ian Foster, ANL and U. of Chicago |
|
土曜基調講演: 50 Years of Computing at LLNL as a lens to the future |
Dona Crawford, Lawrence Livermore National Laboratory, USA |
|
Visualization and Supercomputing: From Atoms to Galaxies |
Christian Hege, ZIB & Indeed – Visual Concepts GmbH, Berlin |
|
The most powerful Supercompter Centers in Europe and in the World |
Christian Bischof, TU Aachen Dona Crawford, LLNL Alexander Reinefeld, ZIB Berlin Keiji Tani, Japan Atomic Energy Research Institute, Tokyo |
2) 木曜基調講演(Monika Henzinger, Google)
木曜日(6月20日)の基調講演はGoogleのMonika Henzingerの“Indexing the Web – A Challenge for Supercomputing”であった。従来の情報検索と、Web上の情報検索の違いから始め、Page Rankの定義や安定性について論じ、サーチエンジンのcrawlerやindexerやquery handlerにおける並列性について説明した。
|
Web上のデータは8か月で倍増しており、ユーザは2億人を超える。その80%がサーチエンジンを使っている。では、どのようにユーザが必要な情報を見つけるのか、それは賢いアルゴリズムと並列性である。 従来の情報検索と違うのは、億を超えるユーザ数、関心の多様性、検索語の不完全さ、結果のトップしか見ない人が多いなど。検索語が文書に何回現れるかなどの従来の方法は役立たない。 そこでGoogleは次のような方法を取る。まず、AからBへのリンクは、Aの著者がBを推薦していると仮定する。そこからPage Rankを定める。Page Rankとは、Markov連鎖における滞在確率である。
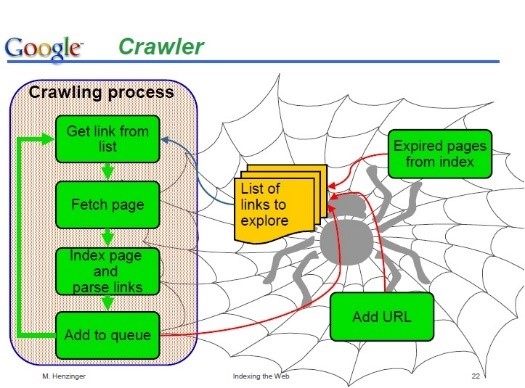
サーチエンジンにはクローラ(スパイダ:右図)と、インデクサと、Query handlerから成るが、それぞれに並列性がある。クローラでは、同じページを何度も見ることのないようにすることが重要である。インデクシングは巨大な並列ソートである。 並列処理の問題は、トラフィックやウェブデータの増大についてスケーラブルかどうか、また、故障をどう回避するかである。スケーラブルにするには、インデックスを多数のマシンに分散することである。検索時にインデックスはread onlyなので、コンシステンシの問題はなく、検索はEP (Embarrassingly Parallel)である。 PCは耐故障性がなく、何千台も並べると不安定なので、複製などソフトでカバーする。 Googleは、様々なAPIを開発したり、声のサーチを始めたり、SOAP interfaceを付けたり、日々発展している。 |
3) 金曜基調講演(Jack Dongarra)
金曜日(6月21日)の基調講演はJack Dongarraの“High Performance Computing, Computational Grid, and Numerical Libraries”であった。HPCwireには事前のインタビューが掲載されている。(HPCwire 2002/5/24)
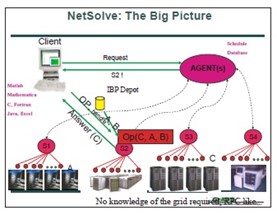
分散並列処理をheterogeneityで並べると、最右翼はASCIなどの超並列、最左翼はSETI@homeやEntropiaである。Gridとは、分散した制御により、アプリがコンピュータのサイクルを湯水のように使えるシステムである。数値ライブラリもGridに対応する必要がある。我々はGrid上で動くScaLAPACKとPETScの初期版を開発し、その性能モデルを作った。それに基づいてResource selectorを考えている。3つのクラスタにわたるScaLAPACKの性能を測定した。スケジューリングが問題である。3万元の行列までテストを行った。 他方NetSolve(右図)はネットワーク上のソルバで、Gridソルバの一例である。NetSolve AgentとNtSolve Clientから成る。連鎖的に使うには、データのpersistenceが問題である。テネシー大学の例、NPACI Alpha ProjectのMCellなどを紹介した。 |
4) 土曜基調講演(Dona Crawford)
LLNLのDona L. Crawford(LLNL計算担当副所長)は、6月22日(土曜日)、“50 Years of Computing at LLNL as a lens to the future”と題して基調講演を行った。 (HPCwire 2002/7/5)
|
彼女は、LLNLが1952年の設立以来、計算資源の提供と計算諸科学の推進により、社会の諸問題を解決してきたことを強調した。とくに計算によるモデリングが、科学技術の方法論を大きく変えて来たことを指摘した。未来の科学研究は、より複雑で大規模な問題に対応するであろう。現在、テラスケールのシミュレーションは、ほとんどすべてのLLNLのプログラムにおいて決定的な役割を果たしている。今後必要な計算量はますます増大するであろう。創立者のEdward Tellerは実験と計算の結合の重要性を認識していた。
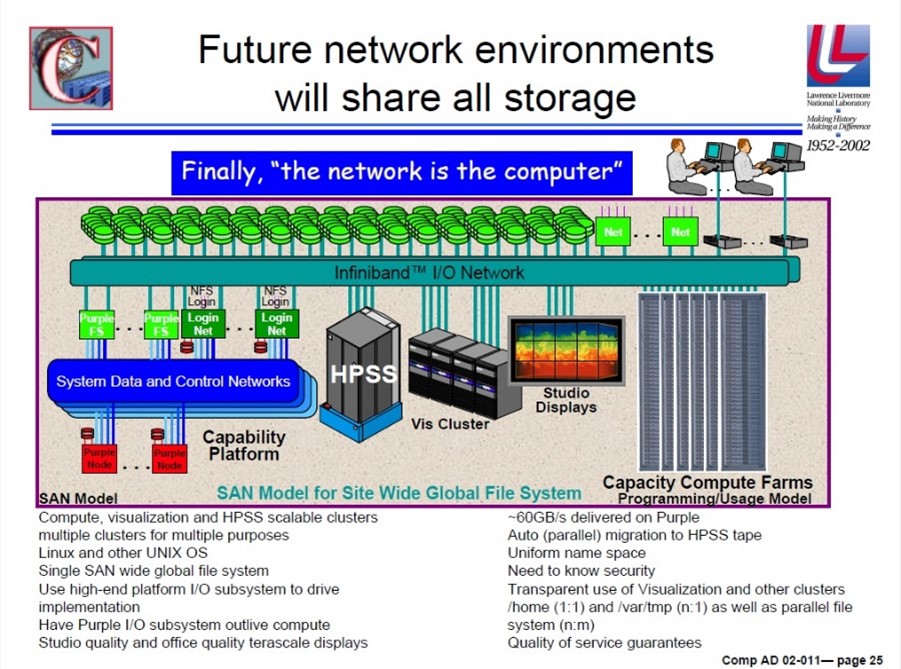
スーパーコンピュータのインフラは、「電力」「メモリサイズ」「バンド幅」「レイテンシ」「I/Oバランス」の間のバランスが重要であるが、Cray 1以来、このバランスは失われた。計算パワーが増大し、答えを得るまでの時間は減る。今後は、ネットワークに基づいた資源共有のアーキテクチャを考えるべきである。将来の予想図を右図に示す。しかし、現在のベンダの提供するツールでは不足である。今後、共同研究やオープンソースによりギャップを埋める必要がある。 他方、プログラム環境(言語、runtime、ツールなど)も変わって来ている。複雑なプログラム環境を開発することはますます困難になっている。生産性と最適化のバランスを取らなければならない。生産性を上げることは急務である。アルゴリズムはアーキテクチャとともに発展しなければならない。特に、スケーラビリティを改良する必要がある。多くの物理問題では、まだスケーラブルなアルゴリズムが存在していない。 さらには、問題の複雑化に伴い、モデル化の方法論を考え直さなければならない。前処理、計算、後処理を会話的に制御するモデリングを期待する。そのためには、human interfaceが重要である。データ量も巨大になるであろう。 シミュレーションには、検証(モデルを正しく計算したか)と、評価(現実世界との対応)が重要である。 |
5) パネルディスカッション
6月20日の午後14:30~16:30に、“Innovative HPC Applications : Challenge for Software?”というパネルディスカッションが行われた。議論の内容は覚えていない。
6) Facing Petaflops Computing – Device Technology and Applications
6月21日(金曜日)に、ペタスケールについて、2つの講演があった。
a) Masao Fukuma (NEC Laboratories, NEC Corporation)
NECのFukumaはDevice Technology for Peta Computingという講演を行った。
|
日本電気は、1996年に世界初のCMOSのベクトル計算機SX-4を開発した。地球シミュレータはその延長上にあり、1チップ上にベクトル演算器を搭載し、8 GFlopsの性能を実現した。半導体の微細化は進んでいるので、30 nmなら1 MWで1 PFlopsを実現できる。問題は、酸化膜の薄さ、リーク、リソグラフィである。そこで、酸化膜もHfO2などが考えられている。配線も問題になる。21世紀には、新しい素材と新しいアーキテクチャや回路が必要である。 |
b) Rick Stevens(ANL and Univ. Chicago)
Rickは、Preparing for Petaflopsという講演を行った。
|
1990年代にPetascaleについて多くの議論が行われた。その結論をまとめると: ・多くのアプリケーションはPetaflopsを必要としている。 ・Mooreの法則により、放っておいても2015年ごろにはできるが、2007年ごろに実現するにはどうしたらよいか。 ・いろんなアーキテクチャが提案された、どれが実現しそうかは分からない。 ・106~109程度の並列度が必要になる。 ・このような巨大なシステムを動かすシステムソフトウェアを開発するは困難である。 いろんなアプリの分析がなされたが、結局、演算性能増大に伴い、メモリ総量とメモリバンド幅がどうスケールするかが問題である。 またPetaflopsができたとして、現在のプラットフォームからPetaflopsへ移行するために10年掛かるのではないか。時間を短縮するには、PetaflopsでもMPIを使えるようにするか、新しいプログラミングモデルを開発するか、Petaflopsの小型版を早くユーザに提供するか、などの方策が考えらえる。 一つの方法は低コストで、低消費電力で、高性能な組み込みプロセッサでPetaflopsを作ることである。この利点は小型版を非常に安く提供できることである。 ユーザの準備状況もまちまちで、QCDのようにアグレッシブなユーザもあれば、全然用意の出来ていないグループある。例えば、分子動力学、量子化学、分子生物学、地球物理、気候モデルなどである。 更に第3のユーザとしてhigh-throughput categoryがある(キャパシティコンピューティングのことか)。また第4のカテゴリーとして、exploratory computing categoryがある。これは人間との相互作用で問題解決を行う領域で、可視化、定理の自動証明、データマイニングなどが挙げられる。 Petaflopsは計算科学そのものの領域を広げるであろう。 |
7) Top500(2002年6月、世界)
第19回目のTop500リストはISC2002の開会式(6月20日)の最中に発表された。言うまでもなく横浜の地球シミュレータは35.86 TFlopsでダントツの1位であった。これはNo.2のIBM ASCI White (LLNL)の約5倍である。このように5倍もの性能比で1位に出て来たのはTop500の歴史上初めてであった。地球シミュレータの性能は2位から13位までの12システムの性能合計に匹敵している。
システム数ではHewlett-Packard社が168台で1位、2位がIBM社の164台であった。HP社が1位になったのはCompaqの買収によるところが大きい。Top10でも3位、4位、6位はAlphaServerである。IBM社のp690関係は8位と10位を占めている。12位を含めて相互接続網はColonyである。性能合計ではIBM社が33.3%で1位、2位はHPで22.2%、3位は日本電気で19%である。それ以外の社は8%以下。
Top500の性能合計は222 TFlopsで、前回の134.4 TFlopsから大幅に増えている。最下位(つまりNo. 500)は134.3 GFlopsで、前回の94.3 GFlopsから4割増である。Linpackで1 TFlopsを越えるシステムは23、ピークで1 TFlopsを越えるシステムは70もある。PCクラスタは49システムあり、Intelチップのものが42、AMDチップのものが7ある。Intelベースの内の31システムはIBM社のNetfinityシステムである。これらは産業界が主である。
IBM社のpSeries 690(1.1 GHzまたは1.3 GHzのPOWER4を搭載。32プロセッサまでは共有メモリ)が46件も登場しているが、効率(Rmax/Rpeak)が低いことが話題になった。8位のORNLのマシンでも51%で、特に32位CINECAのマシン(1.3 GHz)では31%である。よく見ると、並んでいるCSC(Finland)の1.1 GHzのマシンとRmaxが同じで、まじめに測定せず下位の数値を借用したものと思われる。1.1 GHzとしても37%弱で低い。ちなみに2002年11月のCINECAのマシンは、Rmax=1384.00 GFlopsで効率は52%となっている。相互接続をGigEtherからColonyに変更したことも大きい。
クラスタとしては、35位にHeidelbergのAMD 1.4GHz+Myrinetというのが1430プロセッサ825 GFlopsでトップ、2位は後述の東京工業大学のPresto-III Athlon 1.6 GHzがその次。他に日本のクラスタはMagiとSCORE-IIIが56位、57位で並んでいる。
Intelアーキテクチャ以外では、Alpha-basedクラスタが5台、HP AlphaServerが21台で、クラスタの総数は80となった。そのうち14台はself-made(ユーザの自家製)である。Top10のうち8台はアメリカ国内である。(HPCwire 2002/6/21)
Top500の編集者のひとりHans Meuerは、「いわゆるMPPやクラスタでは解けない問題も多い。地球シミュレータのような並列ベクトルスーパーコンピュータは巨大な可能性を秘めている。気候研究だけでなく航空や自動車の設計にも大きな価値がある。」と論評している。
20位までのリストは以下の通り。RmaxとRpeakの単位はTFlops。前回の順位に括弧があるのは、ハードウェア増強やチューニングで性能が向上したことを示す。ASCI Redがまだがんばっている。LRZの性能向上は、SR8000/F1のノード数を112から168に増強したためである(HPCwire 2002/1/18)。
|
順位 |
前回 |
設置場所 |
機種 |
コア数 |
Rmax |
Rpeak |
|
1 |
- |
海洋研究開発機構 |
地球シミュレータ |
5120 |
35.86 |
40.96 |
|
2 |
1 |
LLNL |
ASCI White, POWER3, 375 MHz |
8192 |
7.226 |
12.288 |
|
3 |
(2) |
PSC |
AlphaServer SC45, 1 GHz |
3016 |
4.463 |
6.032 |
|
4 |
- |
CEA (France) |
AlphaServer SC45, 1 GHz |
2560 |
3.980 |
5.120 |
|
5 |
3 |
NERSC |
SP Power3, 375 MHz |
3328 |
3.052 |
4.992 |
|
6 |
(6) |
LANL |
AlphaServer SC45, 1 GHz |
2048 |
2.916 |
4.096 |
|
7 |
4 |
SNL |
ASCI Red |
9632 |
2.379 |
3.207 |
|
8 |
- |
ORNL |
p690 Turbo, 1.3 GHz |
864 |
2.310 |
4.4928 |
|
9 |
5 |
LLNL |
ASCI Blue-Pacific SST |
5808 |
2.144 |
3.8565 |
|
10 |
- |
Army Research Laboratory (USA) |
p690 Turbo, 1.3 GHz
|
768 |
2.050 |
3.9936 |
|
11 |
- |
AWE (UK) |
SP Power3, 375 MHz |
1920 |
1.910 |
2.880 |
|
12 |
- |
IBM/ECMWF |
p690 Turbo, 1.3 GHz |
704 |
1.849 |
3.6608 |
|
13 |
7 |
東京大学 |
SR8000/MPP |
1152 |
1.7091 |
2.074 |
|
14 |
(17) |
Leibniz Rechenzentrum (Germany) |
SR8000-F1 |
168 |
1.653 |
2.016 |
|
15 |
8 |
LANL |
ASCI Blue Mountain |
6144 |
1.608 |
3.072 |
|
16 |
9 |
NAVO DSRC (USA) |
SP Power3, 375 MHz |
1336 |
1.417 |
2.004 |
|
17 |
10 |
ドイツ気象庁 |
SP Power3, 375 MHz |
1280 |
1.293 |
1.920 |
|
18 |
11 |
NCAR |
SP Power3, 375 MHz |
1260 |
1.272 |
1.890 |
|
19 |
12 |
大阪大学 |
SX-5/128M8 |
128 |
1.192 |
1.280 |
|
20 |
- |
Nationl Centers for Enviromental Prediction (USA) |
SP Power3, 375 MHz |
1104 |
1.179 |
1.656 |
8) Top500(2002年6月、日本)
日本設置のシステムの100位以内は以下の通り。東工大のPresto-IIIは当初137位となっていたが、松岡聡が「716.1 GFlopsで47位のはずだ」と猛抗議をして、47位に訂正された。
つくば地区は、KEKのSR8000が27位、筑波大のVPP5000が45位、上述の2つのクラスタMagiとSCORE-IIIが56位、57位、環境研のSX-6が87位tie、TACCのSR8000が98位、筑波大のCP-PACSが124位である。
|
順位 |
前回 |
設置場所 |
機種 |
コア数 |
Rmax |
Rpeak |
|
1 |
- |
海洋研究開発機構 |
地球シミュレータ |
5120 |
35.86 |
40.96 |
|
13 |
7 |
東京大学 |
SR8000/MPP |
1152 |
1.7091 |
2.074 |
|
19 |
12 |
大阪大学 |
SX-5/128M8 |
128 |
1.192 |
1.280 |
|
25 |
- |
日本電気府中工場 |
SX-6/128M16 |
128 |
0.982 |
1.024 |
|
27 |
19 |
高エネルギー研 |
SR8000-F1 |
100 |
0.917 |
1.200 |
|
30 |
22 |
東京大学 |
SR8000/128 |
128 |
0.873 |
1,024 |
|
41 |
26 |
東北大学金材研 |
SR8000-G1/64 |
64 |
0.7907 |
0.9216 |
|
45 |
28 |
筑波大学 |
VPP5000/80 |
80 |
0.730 |
0.768 |
|
47 |
- |
東京工業大学 |
Presto III Athlon 1.6 GHz |
480 |
0.716 |
1.536 |
|
51 |
32 |
気象庁 |
SR8000-E1/80 |
80 |
0.6913 |
0.768 |
|
56 |
39 |
産総研CBRC |
Magi Cluster PIII, 933 MHz |
1040 |
0.654 |
0.970 |
|
57 |
40 |
新情報(つくば研究所) |
SCore IIIe/PIII, 933 MHz |
1024 |
0.6183 |
0.9554 |
|
62 |
42 |
東京大学物性研 |
SR8000-F1/60 |
60 |
0.577 |
0.720 |
|
65tie |
- |
日本原子力研究所 |
VPP5000/64 |
64 |
0.563 |
0.6144 |
|
65tie |
43 |
九州大学 |
VPP5000/64 |
64 |
0.563 |
0.6144 |
|
87tie |
- |
航空宇宙研究所 |
SX-6/64M8 |
64 |
0.4952 |
0.512 |
|
87tie |
- |
国立環境研 |
SX-6/64M8 |
64 |
0.4952 |
0.512 |
|
91 |
57 |
名古屋大学 |
VPP5000/56 |
56 |
0.492 |
0.5376 |
|
92 |
58 |
京都大学 |
VPP800/63 |
63 |
0.482 |
0.504 |
|
99 |
61 |
産総研TACC |
SR8000/64 |
64 |
0.449 |
0.512 |
この中で、47位の東工大のPresto III、56位の産総研のMagi、新情報のScore IIIeは、自作のクラスタである。また、遙かに下位であるが、東大情報科学教室が教育用のPCを一時的に接続して自作したSun Blade 1000 750MHz Clusterが、コア数196、Rmax=149.2 GFlopsで427位にぎりぎり入っていた。750MHz版のUltraSPARC IIIはプロセッサの不具合のためSoftware Prefetch機能が使えなかったが、今回特別に制限を外して測定したものである。
 |
|
9) レセプション
金曜日(6月21日)の夜には、遊覧船を借り切ってNeckar Riverboat Cruiseがあった。ホスト役は、地球シミュレータでTop500のトップを獲得した日本電気の渡辺貞氏であった。川風に吹かれての生ビールがおいしかった。ネッカー川を静かに上って、また下ってきただけであるが、3時間ほどのクルーズであった(写真は地球シミュレータセンター北脇重宗氏提供)。途中にいくつか閘門(こうもん)があった。もっと上流に航行すると、StuttgartやTübingenに行ける。
次回はBaltimoreで開催されたSC2002の「その一」。地球シミュレータの衝撃をめくって、様々な議論があった。
 |