
HPCの歩み50年記事一覧

スパコンリスト日本

記事寄稿について

夏休みの読書:「ハイパフォーマンス・コンピューティングは変曲点」
John Russell

先日開催された第11回国際シンポジウム「Highly Efficient Accelerators and Reconfigurable Technologies(HEART)」において、Leibniz Supercomputing Center(ミュンヘン)のMartin Schulzを中心とする研究者グループは、「ポジションペーパー」を発表し、ハイパフォーマンス・コンピューティング(HPC)のアーキテクチャの状況が激変していると主張した。
「将来のアーキテクチャは、幅広いワークロードを可能にするさまざまな特殊アーキテクチャを、厳しいエネルギー制限のもとで提供しなければならないでしょう。」と述べている。これらのアーキテクチャでは、すでにモバイルシステムや組み込みシステムで見られるように、各ノード内に統合されなければならず、データがノード間で移動したり、さらには、加速器の種類を切り替える際にシステムモジュール間で移動したりすることを避けることができる。
HPCが変化していることにはほとんど異論はなく、著者であるMartin Schulz、Dieter Kranzlmüller、Laura Brandon Schulz、Carsten Trinitis、Josef Weidendorferは、多くの身近な圧力(Dennardスケーリングの終了、Moore’s Lawの衰退など)を認めた上で、HPCアーキテクチャの未来に向けた4つの指針を提案している。
- エネルギー消費は、もはや単なるコスト要因ではなく、施設の実現可能性を左右する厳しい制約となっている。
- 周波数が停滞しているにもかかわらず、限られたエネルギーバンド内でさらに性能を向上させるには、特殊化が鍵となる。
- エネルギー予算の大部分はデータの移動に費やされており、将来のアーキテクチャはこのようなデータの移動を最小限に抑えるように設計されなければならない。
- 大規模なコンピューティングセンターでは、差別化されつつあるワークロードに対して最適なコンピューティングリソースを提供する必要がある。
今回発表された論文「On the Inevitability of Integrated HPC Systems and How they will Change HPC System Operations」では、4つの分野のそれぞれについて掘り下げている。統合型ヘテロジニアスシステムは、「システム全体のアーキテクチャをほぼ同一のノードのホモジニアスな集合体として維持しながら、複数の特殊なアーキテクチャを単一のノードに統合する有望な選択肢です。これにより、アプリケーションは、エネルギーコストとパフォーマンスのオーバーヘッドを最小限に抑えながら、アクセラレータモジュールを細かいスケールで素早く切り替えることができ、真のヘテロジニアスアプリケーションを実現することができます。」と述べている。
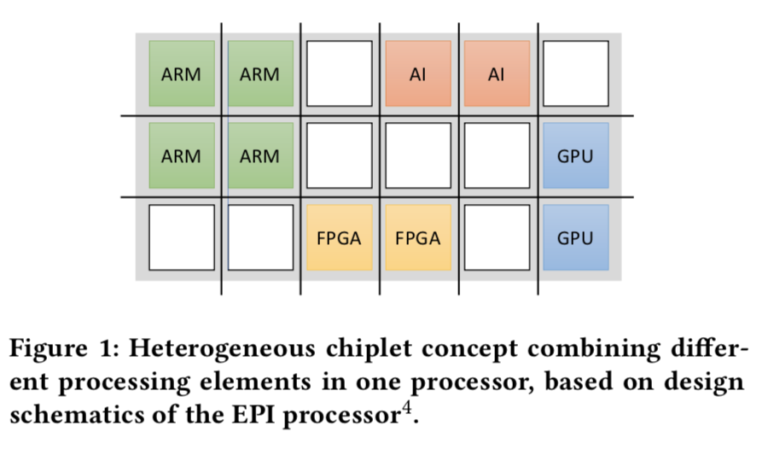
このような統合された異種性を実現するための核となるのが、チップレットの使用である。
「1つまたは2つの特化した処理要素を持つ単純な統合システム(例えば、GPUを使用したり、GPUとテンソルユニットを使用したり)は、すでに多くのシステムで使用されています。ExaNoDeのような研究プロジェクトでは、現在、統合化を検討しており、有望な結果が得られています。また、いくつかの商用チップメーカーが、この方向に向かっていると噂されています。」と研究者たちは書いている。「現在、最も注目されているのは、European Processor Initiative(EPI)が、ARMコアとさまざまなアクセラレータモジュールを組み合わせたカスタマイズ可能なチップデザインを検討していることです(図1)。さらに、いくつかのグループは、GPUとFPGAをノード内に搭載したクラスタを実験しています。このクラスタは、適切なアーキテクチャーを対象とした代替ワークロード用、または両方のアーキテクチャーにマッピングされたアルゴリズムを用いて大規模な並列問題を解決するためのものです。将来のシステムでは、これをさらに推し進めて、より緊密な統合とアーキテクチャの多様化を目指し、より異質で柔軟な使い方ができるシステムを実現することになるでしょう。」と述べている。
 |
このような統合的なアプローチには課題がないわけではない。「1つのアプリケーションをシステム全体で実行することは容易ですが、同じ種類のノードがどこでも利用できるため、1つのアプリケーションがすべての特化した計算要素を同時に使用することはなく、処理要素が空回りすることになります。したがって、最適なアクセラレータの組み合わせを選択することは、調達時の重要な設計基準となります。これは、コンピュータセンターとそのユーザ、そしてシステムベンダーの共同設計によってのみ達成されます。さらに、実行時には、それぞれの計算機資源を動的にスケジュールし、電力を供給することが重要になります。パワーオーバープロビジョニング(動的に選択された加速処理要素のサブセットで到達するTDPと最大ノードパワーを計画すること)を使用すれば、これは容易に実現できますが、システムおよびリソース管理における新しいソフトウェアアプローチが必要です。」と述べている。
彼らは、さまざまなオン・ノード・アクセラレータを活用するためのプログラミング環境と抽象化の必要性を指摘している。「普及のためには、そのようなサポートが容易に利用でき、最良の場合には、1つのプログラミング環境に統一されている必要があります。アーキテクチャに依存しないターゲットコンセプトを持つOpenMPは、これに適しています。AI、ML、HPDAなどで一般的なドメイン固有のフレームワーク(Tensorflow、Pytorch、Sparkなど)は、さらにこの異質性を隠し、統合プラットフォームを幅広いユーザが利用できるようにするのに役立ちます。」
ノード内のデバイスの多様性と、様々なデバイス間で避けられないアイドル時間に対処するために、研究者たちは 「統合システムを完全に活用するための計算およびエネルギーリソースの動的なスケジューリングと結合した新しいレベルの適応性 」の開発を提案している。この適応型管理アプローチの核となるのは、以下の図2に示すようなフィードバックループだという。
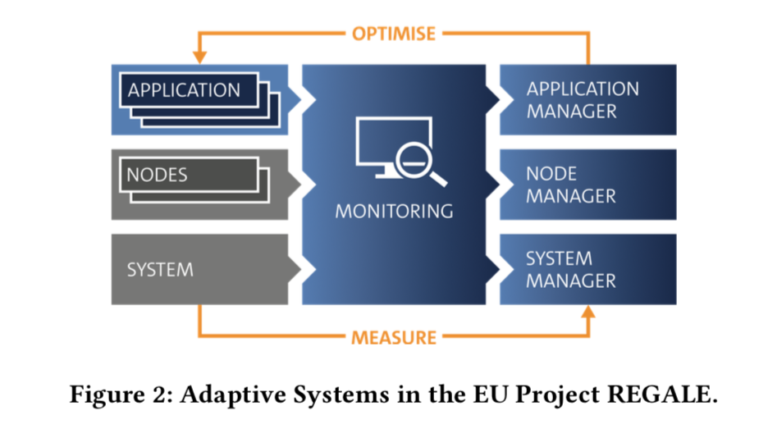 |
この適応型アプローチは、今春発足したEUの研究プロジェクト「REGALE」の一環として研究されている。REGALEは、すべてのシステムレイヤーで測定された情報を使用し、その情報をもとにスタック全体を適応させる。
- アプリケーションレベル:処理要素の数や種類などのアプリケーションリソースを動的に変化させる。
- ノードレベル:DVFSやパワーキャッピング、ノードレベルでのメモリやキャッシュなどの分割による消費電力の変更など、ノードの設定を変更する。
- システムレベル:作業負荷や外部入力(エネルギー価格や供給レベルなど)に基づいてシステムの動作を調整する。
このポジションペーパーはすぐに読めるので、直接読むのが一番だ。インテグレーションのレベルやタイプは異なるかもしれないが、「高価なデータ転送を最小限に抑えて短縮し、ノード内で実行される異なる処理要素間のきめ細かな移行を可能にし、アプリケーションが特定の技術の個々のモジュールやサブクラスタだけでなく、マシン全体をスケールアウト実験に利用できるようにするためには、このような統合はノード上、さらにはオンチップでなければならない。」と研究者らは結論として主張している。
このようなアプローチがあって初めて、大規模かつ最適なエネルギー効率で、多様なコンピューティングポートフォリオを提供できる大規模計算資源の設計と展開が可能になると、彼らは主張している。時が解決してくれるだろう。
特別イベント

寄稿者
![]() 西克也
西克也
西克也はフェアチャイルド社、クレイ・リサーチ社、ベストシステムズ社など、30年以上に渡ってHPCに関する仕事に従事している。Hpcwire Japanの編集長として記事の作成と翻訳を行っている。
![]() 島田佳代子
島田佳代子
1999年~2007年まで英国在住。2001年よりスポーツ、旅、ビジネス、映画など幅広いジャンルで執筆活動を開始し、Hpcwire Japanでは主に日本のHPC業界が世界に誇る研究者、開発者の方々のインタビューを担当。
![]() 小柳義夫
小柳義夫
小柳義夫氏は40年以上に亘ってHPCに携わってきた研究者であり、日本のHPC業界における生き字引として有名。現在 高度情報科学技術研究機構に所属し、産業界のHPC推進にあたっている。
![]() 小西史一
小西史一
小西史一は、理化学研究所、東京工業大学においてHPCおよびバイオインフォマティクスに関する研究と教育に携わってきた研究者。2012年からフォトグラファーとしての活動を開始し、現在はIT技術・セキュリティのコンサルティング業務に携わっている。