
HPCの歩み50年(第203回)-2011年(o)-
HPC Challengeでは、Class 1のすべてにおいて約束通り京コンピュータが第1位を受賞した。Gordon Bell賞では、理研、筑波大、東大、富士通連合軍による“First-principles calculations of electron states of a silicon nanowire with 100,000 atoms on the K computer” がthe Sustained Performance Prizeを受賞した。
SC2011(続き)
8) 基調講演(Jen-Hsun Huang)
15日(火)の基調講演はNVIDIA創立者・社長・CEOのJen-Hsun Huang(黄仁勳)氏の”Exascale — An Innovator’s Dilemma” であった。昨年の基調講演のChristensenの講演を意識していたようである。Christensenの言うdisruptive technologyはまさにexascaleに当てはまる、と指摘した。
スーパーコンピュータは今や不可欠のツールである。計算速度の歴史を見てみよう。驚くほどの発展である。Cray YMPは1988年に初めてGFlopsを実現した[筆者注:ベンチマークで世界初のGFlopsは、NEC SX-2がLivermore LoopのNo.7で1042.3 MFlopsを出した(1987)のが最初であろう]。T3E/1200は1998年に0.8 TFlopsを、XT5 (Jaguar)は2009年に1.8 PlopsFを実現した。
4年毎に半導体のサイズは半分になり、同じパワーで8倍の性能が出る。ワット当たりの性能は年毎に1.68倍である。これまでDennard氏の提唱したスケーリングに従ってきたが、これには終わりが見えている。今後パワー当たりの性能向上は年に1.19程度にまで鈍るであろう。20MWに制限すると、2019年には70 PFlops 、2022年にも100 PFlopsしか出来ず、1 EFlopsは2035年になってしまう。
CPUは高速化しているが複雑化している。それはsingle thread performanceに最適化しているからである。演算の50倍のエネルギーを演算のスケジュールに、20倍のエネルギーをデータ移動に使っている。従って、演算には数%のエネルギーしか使っていない。
超効率的なプロセッサが必要である。それは多くの単一なプロセッサの集まりであり、局所性を重視し、single thread performanceは悪化する。
“Innovator’s Dilemma”によれば、顧客や投資家に注目されないと企業は成り立たないし、小さな市場では大きな会社の成長を支えられない、と書かれている。NVIDIAのGPUはゲーム用のグラフィックスというロー・エンドから始めた。これこそ破壊的イノベーションだ。一つは2~300ドルだが、年に2億売れている。もうけは少ないが数が多い。GPUは表現の幅を広げた。すべてのゲームは違うし、より高度なものを求めるようになる。20年間最大のグラフィックの会社であった。
IEEE 754の32ビット表現を採用した。これによりGPU computingは新しい市場となった。長崎大学の浜田氏の(扇風機で冷やしている)コンピュータはまさに破壊的技術である。かれはGordon Bell賞を取った。かれはIBMの顧客には絶対ならない。
今やCUDAが動くGPUは3.5億個以上出ている。中国科学院はH1N1インフルエンザウィルスを解析するのに2000個のGPUを使った。今回NVIDIAはOpenACCを発表した。これは並列プログラミングのためのオープンな規格で、directiveを書くだけでGPU上で並列化できる。魚の一生[?]の計算が2日で65倍になったとか、星と銀河が5日で5.6倍になったとかいくつかの例を出していた。
Exascaleへの路には20 MWの壁がある。2019年までに20 MWでExascaleができれば、2035年には100 EFlopsが実現する。
クリステンセン流に言えば、GPUはすでにクロスオーバーを越え、新しい市場のイノベーションに到達したのだ。巨大な市場がGPUをサポートしている。モバイルは10億台、ワークステーションは500万台である。2019年には5 WでTFlopsが可能になる。
ここで怪獣の映画を上映した。音響もすごかった。
TFlopsはASCI Redで実現したが、2019年には100W で出来るようになる。リアルタイムの動画のためにはTFlopsが必要である。
ここでAssasin’s Creedという中世物の映画を上映。
別の人が出て来て、どう絵を作るかを実演した。
“One Disruption Enables Another” ということが重要である。”From Supercomputer to Superphones.”
なお、電子ニュースの「SC11 – NVIDIAが基調講演で語ったスパコンの概念と未来展望」や「20メガワットエクサスケールは破壊的イノベーションで実現する」をご覧ください。
9) HPC Challenge Awards
15日12:15からのBirds of a Feather sessionの一つとして、The 2011 HPC Challenge Awardsが発表された。これはClass 1とClass 2の二つのクラスがある。Class 1では、多くの問題のベスト性能を競う。カテゴリとしては、
a) HPL (High Performance Linpack)
b) Global-Random-Access
c) EP-STREAM-Triad per system
d) Global-FFT
Class 2では上記4つを含むHPC Challenge Benchmarkのプログラムの4つ以上を最もエレガントに実装したチームを表彰する。採点基準は「技術点」(性能)と「芸術点」(エレガンス、明晰さ、サイズ)がそれぞれ50%である。
Class 1の上位受賞は次の通り。
|
Global HPL |
Performance (TFLOP/s) |
System |
Institutional Facility |
|
1st place |
2,118 |
K computer |
RIKEN |
|
1st runner up |
1,533 |
Cray XT5 |
ORNL |
|
2nd runner up |
736 |
Cray XT5 |
UTK |
|
Global RandomAccess |
Performance (GUPS) |
System |
Institutional Facility |
|
1st place |
121 |
K computer |
RIKEN |
|
1st runner up |
117 |
IBM BG/P |
LLNL |
|
2nd runner up |
103 |
IBM BG/P |
ANL |
|
EP STREAM (Triad) per system |
Performance (TB/s) |
System |
Institutional Facility |
|
1st place |
812 |
K computer |
RIKEN |
|
1st runner up |
398 |
Cray XT5 |
ORNL |
|
2nd runner up |
267 |
IBM BG/P |
LLNL |
|
Global FFT |
Performance (TFLOP/s) |
System |
Institutional Facility |
|
1st place |
34.7 |
K computer |
RIKEN |
|
1st runner up |
11.9 |
NEC SX-9 |
JAMSTEC |
|
2nd runner up |
10.7 |
Cray XT5 |
ORNL |
今回、Class 1のすべてにおいて約束通り京コンピュータが第1位を受賞した。なおG-FFTでは地球シミュレータが2位を獲得している。
Class 2の結果は以下の通り。
|
Award |
Recipient |
Affiliation |
Language |
|
Most Elegant Language $1000 |
Sung-Eun Choi
|
Cray |
Chapel |
|
Most Elegant Language Honoable Mention |
Laksono Adhianto
|
Rice University |
Coarray Fortran 2.0 |
|
Best Performance $1000 |
Laxmikant V. Kale |
UIUC |
Charm++ |
|
Best Performance Honorable Mention |
Laksono Adhianto
|
Rice niversity |
Coarray Fortran 2.0 |
10) Gordon Bell賞
今年は5件の論文がGordon Bello賞のfinalistsに選ばれた。15日と16日に講演が行われた。
|
“First-principles calculations of electron states of a silicon nanowire with 100,000 atoms on the K computer” Yukihiro Hasegawa, Junichi Iwata, Miwako Tsuji, Daisuke Takahashi, Atsushi Oshiyama, Kazuo Minami, Taisuke Boku, Fumiyoshi Shoji, Atsuya Uno, Motoyoshi Kurokawa, Hikaru Inoue, Ikuo Miyoshi, Mitsuo Yokokawa (理研、筑波大、東大、富士通) |
|
“Atomistic Nanoelectronic Device Engineering with sustained Performance up o 1.44 Pflops” Mathiew Luisier, Timothy B, Boykin, Gerhard Klimeck, Wolfgang Fichtner (Purdue University, University of Alabama in Huntsville, ETH Zurich) |
|
“Peta-scale Phase-Field Simulation for Dendritic Solidification on the TSUBAME 2.0 Supercomputer” Takashi Shimokawabe, Takayuki Aoki, Tomohiro Takaki, Akinori Yamanaka, Akira Nukada, Toshio Endo, Naoya Maruyama, Satoshi Matsuoka(東工大、京都工芸繊維大学) |
|
“Petaflop Biofluidics Simulations On A Two Million-Core System” Massimo Bernaschi, Mauro Bisson, Toshio Endo, Massimiliano Fatica, Satoshi Matsuoka, Simone Melchionna, Sauro Succi(Consiglio Nazionale delle Ricerche, Harvard University, 東工大、NVIDIA) |
|
“A New Computational Pardigm in Multiscale Simulations: Application to Brain Blood Flow” Leopold Grinberg, Vitali Morozov, Dimitry Fedosov, Joseph Insley, Michael Papka, Kalyan Kumaran, George Karnidakis (Brouwn University, ANL, Forschungszentrum Juelich) |
審査の結果、理研他の「京」による”First-principle calculations ..”がthe Sustained Performance Prizeを受賞。東工大他の「Tsubame 2.0」による”Peta-scale Phase-Field Simulation ..”がthe Scalability/Time to Solution Prizeを受賞した。また異例ではあるが、レベルの高さにより、他の3件すべてに、honorable mentions賞を授与した。そのうちの1つも東工大が関係している。
11) Blue Waters Panel
15日(火)午後15:30~17:00には、実質上BlueWatersに関するパネルがあった。正式なタイトルは、Holistic Co-Design Approach using Application Performance Modeling and Simulation for System Design, Evaluation, and Optimizationである。座長のIrene Qualters (NSF、元Cray社) はNSFにおけるこのプロジェクトの責任者である。パネリストは、
William Kramer – National Center for Supercomputing Applications
Torsten Hoefler – National Center for Supercomputing Applications
Adolfy Hoisie – Pacific Northwest National Laboratory
Laxmikant Kale – University of Illinois at Urbana-Champaign
Allan Snavely – University of California, San Diego
Marc Snir – University of Illinois at Urbana-Champaign
の6人である。
UIUCのBlueWatersプロジェクトは、8月6日にIBM社が撤退し、その後Cray社が担当することになったが、全体論的(“holistic”にはいい訳語がない)なアプローチを強調していた。要はLinpackなどに拘泥しないということであろうか。このパネルのアブストラクトは、
「将来のペタスケール++システムには、システムとアプリ両方の加速実現の主要な方法として”co-design”を用いることになる。Blue Watersは、アプリとシステムのコデザインの概念を集中的に用いた最初で最大のHPCシステムプロジェクトである。Blue Watersのコデザインの努力の主要な部分は、アプリの再構成とシステムデザインへの全体論的なモデリングとシミュレーションのアプローチである。このパネルはBlue Watersの科学者と開発者とがとった、統合的(“synergetic”にもいい訳がない)なしかも独立なモデリング、シミュレーション、性能予測を提示する。この多面的な努力は、Blue Watersシステムとともにそれを使うアプリの両方の、分析を助けるとともに最適化するであろう。このパネルは、モデリングとシミュレーションの統合的な努力を提示する。このような努力は、システムデザインとアプリの移植にインパクトを与える。ここでの教訓は、ペタスケールを越えるエクサスケールへの努力にも適用できるであろう。」というたいそうなものであった。
まずQualtersが、「このパネルはBlue Waters Projectで議論してきたことを紹介したい。局所性だけを考えればいいわけではない。」というような導入をした。
Snavelyは、”Performance Modeling for Blue Waters”と題して、「性能モデルはアプリに対して予言力を持たなくてはならない。新しいシステムのアクセラレータに適用して性能が予測できなくてはならない。そのためにはシステム性能のレーダーチャートを用いる。項目としては、L1, L2, L3 caches、メインメモリ、on-node latency, on-node bandwidth、off-node latency、off-node bandwidthなど。これを気象や地震などのアプリに適用する。このように、性能モデルの基本的な要素によってシステムとアプリをつなぐ。これが私の所属するPMaC lab.の予測フレームワークである。」と述べた。
Hoisieは、「アプリの振る舞いをカプセル化し、性能と○○を分離する。」と述べ、性能モデルのプロセスフローチャートを示した。「IBMとの共同研究で、PERCSにおけるコデザインは、仮想的なシステムで性能予測を行い、コデザインのツールとしてモデルを用いる。エクサスケールのためのコデザインとしては、モデリングが重要で、消費電力、性能、信頼性が鍵である。
SnirはANLのMathematics and Computer Science Divisionのdirectorを兼務しているようである。かれは、”From Art to Engineering” と題して、「これまで性能予測というと魔法のお告げのように見られていた。つまり、適用可能性が狭く(とくに動的に変化する場合)、プログラマにもシステム・デザイナーにも立ち入り禁止(off limits)であった。戦略的な目標は消費エネルギーである。2%だけが浮動小数演算に使われていて、50%はデータの移動に、50%はアーキテクチャ関係の利便性(キャッシュなど)に使われている。」などと述べた。
Kaleは、「新しいマシン上ではチューニングに時間がかかる。どうしたら性能を予測し、ボトルネックを発見できるか。それには感度解析が重要である。詳しくは私の論文を見てほしいが、Charm++によりBigSimというエミュレータを作った。2万コアのマシンで30万コアのプログラムを予測できる。Petascale++のシステムに対して有効である。」と述べた。
Hoeflerは、”Performance Modeling for the Masses”と題して発題した。「性能モデリングとは何か。簡単な方法論がある。解析的なモデルで測定値を分析することである。例えば、T=a+b*N^3 とか。では、いつ、どこで、そのようなモデルを使うのか。存在するコードに対するわれわれのプロセスには6つのステップ(4つは解析的、2つは経験的)[何のことか不明]がある。Blue Watersのアプリは比較的規則的なものが多い。性能モデルは、アプリの設計者とシステムの設計者の双方の指針になる。」
あまり理解できなかったが、筆者の疑問は、これでアプリとシステムのコデザインになっているのであろうか、ということである。つまり、システムの特徴からアプリを再構成するという方向ばかりで、アプリからシステムの設計を再構成するという方向の議論はあまりなかった。システムはgivenという印象である。Blue Watersの場合、すでにシステムは決まっているのでやむを得ないかもしれないが、これでは双方向のコデザインになっていない、と思われる。「京」や「富岳」で双方向のコデザインができたのは、プロセッサやネットワークを自分たちで設計したからであろう。
この意味で、これまでの日本の先端的HPCマシンはコデザインのコンセプトを守ってきたと思う。典型的なのはGrapeやcp-pacsで、前者は重力多体計算、後者はQCD計算というアプリとアーキテクチャを完全に双方向で設計したと言える。NWTや地球シミュレータでも、流体や気象というアプリからアーキテクチャを考えている。京コンピュータでは、最初の案は「汎用スーパーコンピュータで何でもできる」というような触れ込みであったが、それでは設計ができないと、岩崎先生や筆者などが強硬に主張して、典型的なアプリを(最初約20本、最終的には6本)選び、そのカーネルコードをアーキテクチャやコンパイラとすりあわせたので、ある程度コデザインになったと言える。
重要なことは、このように特定のアプリと摺り合わせてデザインしたコンピュータは、全部とは言わないまでの、他のいくつかのアプリにもかなりの性能を出せるということである。Grapeは完全な専用だったのでちょっと別であるが。
設計は限られた資源をどこに使うかという選択の問題である。最初から「汎用」スーパーコンピュータを目指すと、「あれも欲しい、これも欲しい」ということになって選択ができなくなる。現在、ポスト京「富岳」の開発においてもコデザインが基本原則として明示されている。
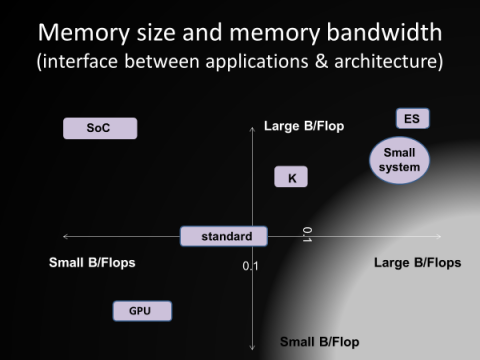
コデザインには、アプリとアーキとをつなぐインタフェースが重要である。cp-pacsではmultというQCDのカーネルを使った(大本は1980年代初めに筆者が書いたサブルーチンである)。カーネルコードが分離できるならばそれは一つの方法である。もう少し一般的には、いくつかの軸で考えることが考えられる。例えば、x軸としては、Flops当たりのメイン・メモリバンド幅(B/Flopと呼ばれる)をとり、y軸としてFlops当たりのメインメモリ量(B/Flopsと呼ばれる)を取り、xy平面で可能なアーキテクチャやアプリを考えることである。
12) Exascale Panel
 |
|
 |
|
 |
|
18日(金)の8:30-10:00に“The View: HPC Edition”というパネルがあった。9月8日にOregon州立大のCherri Pancake教授からメールがあり、これに参加してAsian perspectiveを述べよとの招待であった。なんでも、これは通常のパネルとは違い、ABCテレビの“The View”という番組の真似で、女性たちがco-hosts(共同司会者)となり、いろんな専門家の問題提起を聞きながら、ソファに座って語り合うのだそうである。Wikipedia「ザ・ビュー」によると、1997年から放送している長寿番組である。「わたし、そんなの見たことありません」というと、Cherri女史が「実はわたしも見たことがない」とかずいぶんいい加減である。共同司会者は、
-Cherri M. Pancake (Moderator) – Oregon State University
-Debra Goldfarb – Microsoft Corporation
-Alice Koniges – Lawrence Berkeley National Laboratory
-Candy Culhane – National Security Agency
で、Cherriがモデレータ、他の3人がパネリストとしてプログラムに出ていた。呼ばれた専門家と称する人々は、
-Jean-Yves Berthou (European Exascale Software Initiative)
-Dave Turek (IBM)
-Ryan Waite (Microsoft)
-Matt Fetes (venture capitalist)
と筆者だったらしい。プレゼンは3分程度、長くとも5分以内ということで、3枚のスライドを準備した。実は、6枚ほど用意したのだが、Cherriが減らせ減らせといい、最後は彼女が自分で編集してしまった。2枚目の絵は、横軸が相対メモリ容量、縦軸が相対メモリバンド幅である。この2つの軸で、応用とアーキテクチャを対応付けるという考え方は、ポスト「京」のWGなどで議論されていたものである。当時筆者は、エクサスケールの汎用マシンは困難で、それぞれ特徴のあるマシンを二三台作るべきだと考えていた。
「エクサスケールの予算を獲得するために一番重要なことは何か?」という質問が出たので、2009年の事業仕分けが頭をよぎり、「納税者の理解を得ることです」と答えた。すっかり上がってしまい、他の人が何をしゃべったか、全体の流れがどうだったのか、全然記憶がない。英語はむつかしい。
13) Top500(世界)
11月15日午後5時30分からのBoFでTop500の発表があった。2011年11月のTop500(第38回)の上位20位までを示す。性能の単位はTFlops。前回の順位にカッコがついているのは、システム増強またはチューニングにより性能向上があったことを示す。
|
順位 |
前回 |
設置場所 |
機種名 |
cores |
Rmax |
Rpeak |
|
1 |
(1) |
理研AICS |
「京」コンピュータ |
705024 |
10510 |
11280.4 |
|
2 |
2 |
国家超級計算天津中心 |
Tianhe-1A – NUDT TH MPP, X5670 2.93Ghz 6C, NVIDIA GPU, FT-1000 8C |
186368 |
2566.0 |
4701.0 |
|
3 |
3 |
ORNL |
Jaguar – Cray XT5-HE 6-core 2.6 GHz |
224162 |
1759.0 |
2331.0 |
|
4 |
4 |
国家超級計算深圳中心 |
Nebulae – Dawning TC3600 Blade System, Xeon X5650 6C 2.66GHz, Infiniband QDR, NVIDIA 2050 |
120640 |
1271.0 |
2984.3 |
|
5 |
5 |
東京工業大学 |
TSUBAME 2.0 – HP ProLiant SL390s G7 Xeon 6C X5670, NVIDIA GPU, Linux/Windows |
73278 |
1192.0 |
2287.6 |
|
6 |
6 |
SNL |
Cielo – Cray XE6 8core 2.4 GHz |
142272 |
1110.0 |
1365.8 |
|
7 |
7 |
NASA/Ames |
Pleiades – SGI Altix ICE |
111104 |
1088.0 |
1315.3 |
|
8 |
8 |
NERSC |
Hopper – Cray XE6 12-core 2.1 GHz |
153408 |
1054.0 |
1288.6 |
|
9 |
9 |
CEA(仏) |
Tera-100 – Bull bullx super-node S6010/S6030 |
138368 |
1050.0 |
1254.5 |
|
10 |
10 |
LANL |
Roadrunner-QS22/LS21, Cell 8i 3.2 GHz |
122400 |
1042.0 |
1375.78 |
|
11 |
11 |
NICS, Tennessee |
Kraken Cray XT5-HE – 6-core 2.6 GHz |
11200 |
919.1 |
1173.0 |
|
12 |
- |
Stuttgart大学 |
HERMIT – Cray XE6, Opteron 16C 2.3 GHz |
113472 |
831.4 |
1043.94 |
|
13 |
12 |
FZJ |
JUGENE – Blue Gene/P |
294912 |
825.5 |
1002.7 |
|
14 |
- |
国家超級計算中心済南 |
Sunway Blue Light 16C 0.975 GHz |
137200 |
795.9 |
1070.2 |
|
15 |
- |
LLNL |
Zin – Xeon E5 8C 2.60 GHz |
46208 |
773.3 |
961.1 |
|
16 |
- |
国家超級計算中心湖南 |
Tianhe-1A Hunan Solution, Xeon X5670 6C 2.93 GHz NVIDIA 2050 |
53248 |
771.1 |
1342.8 |
|
17 |
- |
LLNL |
Sequoia – Blue Gene/Q |
65536 |
677.1 |
838.9 |
|
18 |
13 |
Moscow State U. |
Lomonosof – T-Platform |
33072 |
674.1 |
1373.1 |
|
19 |
(24) |
Edinburgh大学 |
HECToR – 565.7Cray XE6, Opteron 16C 2.3 GHz |
716.0 |
660.243 |
829.03 |
|
20 |
- |
NOAA/ORNL |
Gaea C2 – Cray XE6 Opteron 16C 2.3 GHz |
77824 |
565.7 |
715.981 |
Top10では、「京」コンピュータが10 PFlops越えを実現したが、エントリーに変更はなかった。これは、Top500の歴史の中で初めてのことであった。ちなみに、注意深い人は、ラック数が864で、1ラックの計算ノードは96であるから82,944で数が合わないと気づいたかもしれない。実は各ラックには6個のI/Oノードがあり、同じCPUで作られ、相互接続網で接続されている。そこで、I/Oノードも計算にかり出せば864×(96+6)=88,128 となる。これはParagonの昔からしばしば使われている技法である。
新規マシンの最高位は、ドイツStuttgart大学のHERMIT (Cray XE6)の831.4 TflopsでTop500の12位獲得であった。次のTop500で1位となるSequoiaは、部分稼働で17位となっている。
全体の傾向としては、前回250近くあったreplacement rate(新規参入の台数)は195に減少した。ベンダは、台数ベースで、1位がIBM(223台)、2位がHP(140台)であるが、Top50に限ると、1位がCray(17台)、2位がIBM(9台)である。国別では、台数ベースで、1位がアメリカ(53%)、2位が中国(13%)である。
14) Top500(日本)
日本設置のマシンは以下の通り。
|
順位 |
前回 |
設置場所 |
機種 |
コア数 |
Rmax |
Rpeak |
|
1 |
(1) |
理研AICS |
「京」コンピュータ |
705024 |
10510 |
11280.4 |
|
5 |
5 |
東京工業大学 |
TSUBAME 2.0 – HP ProLiant SL390s G7 Xeon 6C X5670, Nvidia GPU, Linux/Windows |
73278 |
1192.0 |
2287.63 |
|
28 |
- |
量子科学技術研究開発機構 |
Helios – Bullx B510, Xeon 8C 2.7 GHz |
20480 |
360.9 |
442.4 |
|
52 |
38 |
日本原子力研究開発機構 |
BX900 Xeon X5570 2.93 GHz, Infiniband QDR |
17072 |
191.4 |
200.08 |
|
72 |
48 |
東大物性研 |
SGI Altix ICE 8400EX Xeon X5570 4-core 2.93 GHz, Infiniband |
15360 |
161.8 |
180.019 |
|
94 |
68 |
JAMSTEC |
Earth Simulator 2 – SX-9/E/1280M160 |
1280 |
122.4 |
131.072 |
|
95 |
- |
北海道大学 |
SR16000 M1/176, POWER7 8C 3.83 GHz |
5504 |
121.6 |
168.9 |
|
101 |
73 |
JAXA |
FX-1 |
12032 |
110.6 |
121.282 |
|
118 |
84 |
東京大学 |
T2K Open Supercomputer (Todai Combined Cluster) |
15104 |
101.7 |
139.0 |
|
125 |
89 |
理研 |
PRIMERGY RX200S5 |
9048 |
97.94 |
106.042 |
|
185 |
118 |
筑波大学 |
T2K Open Supercomputer – Appro Xtreme-X3 Server |
10369 |
77.28 |
95.385 |
|
205 |
(126) |
国立環境研 |
GOSAT Research Computation Facility – Asterism ID318, Intel Xeon E5530, NVIDIA C2050 |
5760 |
75.9 |
177.1 |
|
214 |
127 |
某通信会社 |
HD DL 160 Cluster G6, Xeon X5650 |
13620 |
74.7423 |
144.917 |
|
221 |
131 |
京大基礎物理学研究所 |
Hitachi SR16000 XM1/108 Power7 3.3 GHz, Infiniband |
3456 |
73.35 |
91.2384 |
|
278 |
162 |
某金融機関 |
xSeries x3650M3, IBM |
11640 |
65.6 |
97.8 |
|
280tie |
- |
サービスプロバイダ |
xSeries x3650M3, IBM |
11628 |
65.524 |
123.722 |
|
280tie |
- |
サービスプロバイダ |
xSeries x3650M3, IBM |
11628 |
65.524 |
123.722 |
|
280tie |
- |
サービスプロバイダ |
xSeries x3650M3, IBM |
11628 |
65.524 |
123.722 |
|
292 |
168 |
サービスプロバイダ |
xSeries x3650M2, IBM |
14432 |
64.596 |
130.869 |
|
310 |
- |
某通信会社 |
HP DL160 Xeon 6C 2.40 GHz |
12640 |
62.8 |
121.3 |
|
328 |
(430) |
長崎大学 |
DEGIMA – Intel i5, ATI Radeon |
9900 |
61.4 |
138.9 |
|
340tie |
- |
ITサービスプロバイダ |
HPE Cluster Platform 3000 BL460c |
10752 |
59.6 |
114.4 |
|
340tie |
- |
ITサービスプロバイダ |
HPE Cluster Platform 3000 BL460c |
10752 |
59.6 |
114.4 |
|
367 |
197 |
核融合科学研 |
Plasma Simulator – SR16000 |
4096 |
56.6 |
77.0 |
|
378 |
204 |
サービスプロバイダ |
xSeries x3650M2 Cluster, Xeon QC E55xx 2.26 Ghz, GigE |
11640 |
55.9447 |
105.552 |
|
408tie |
225tie |
サービスプロバイダ |
xSeries x3650M3, IBM |
9732 |
54.8402 |
98.4878 |
|
408tie |
225tie |
サービスプロバイダ |
xSeries x3650M3, IBM |
9732 |
54.8402 |
98.4878 |
|
408tie |
225tie |
サービスプロバイダ |
xSeries x3650M3, IBM |
9732 |
54.8402 |
98.4878 |
|
414 |
230 |
東大医科研 |
SHIROKANE – SunBlade x6250 |
5760 |
54.21 |
69.12 |
|
493 |
291 |
気象研究所 |
Hitachi SR16000 L2/121 |
3871 |
51.21 |
72.7936 |
28位のマシンは青森県六ケ所村にあるITER(国際熱核融合実験炉)のための計算機で、愛称は「ろくちゃん」。
15) Green500
第9回目となるGreen500も発表された。リストはGreen500のページ上には残っていないが、Wikipediaから10位までを記す。
|
順位 |
Top500 |
MFlops/W |
設置場所 |
マシン |
|
1tie |
64tie |
2026.48 |
IBM Rochester |
Blue Gene/Q |
|
1tie |
64tie |
2026.48 |
IBM T.J. Watson |
Bleu Gene/Q |
|
3 |
29 |
1996.09 |
IBM Rochester |
Blue Gene/Q |
|
4 |
17 |
1988.56 |
LLNL |
Blue Gene/Q |
|
5 |
284 |
1689.86 |
IBM T.J.Watson |
Blue Gene/Q Prototype 1 |
|
6 |
238 |
1378.32 |
長崎大学 |
DEGIMA Cluster (Inttel i5, ATI Radeon) |
|
7 |
114 |
1266.26 |
Barcelona S.C. |
Bull, Bullx B505 (Xeon 6C, NVIDIA 2090) |
|
8 |
102 |
1010.11 |
GENCI |
Bull, Bullx B505 (Xeon E5640) |
|
9 |
21 |
963.7 |
中国科学院 |
Mole-8.5 Cluster (Xeon 4C, NVIDIA 2050) |
|
10 |
5 |
958.35 |
東京工業大学 |
HP Proliant SL390s G7 (Xeon 6C, NVIDIA) |
残念ならが「京」コンピュータ(824.5644 MFlops/W)は10位外になってしまった。なお、IBM Rochesterはミネソタ州にある施設であり、ニューヨーク州のRochesterではない。
16) Graph 500
今回のGraph 500は50件の応募があった。上位10件は以下の通り。
|
No. |
前回 |
Machine |
Installation Site |
Number of nodes |
Number of cores |
Problem scale |
GTEPS |
|
1 |
- |
NNSA/SC (IBM – Blue Gene/Q(Prototype)) |
NNSA and IBM Research, T.J. Watson |
4096 |
65536 |
32 |
253.403 |
|
2 |
2 |
Hopper (Cray – XE6) |
LBL |
1800 |
43200 |
37 |
112.743 |
|
3 |
1 |
Lomonosov (MPP) |
Moscow State University |
4096 |
32768 |
37 |
103.079 |
|
4 |
- |
TSUBAME (NEC/HP) |
GSIC Center, Tokyo Institute of Technology |
1366 |
16392 |
36 |
99.858 |
|
5 |
5 |
Jugene (IBM – Blue Gene/P) |
Forschungszentrum Jülich |
64000 |
37 |
92.3418 |
|
|
6 |
4 |
Intrepid (IBM – Blue Gene/P) |
ANL |
32768 |
131072 |
35 |
78.3832 |
|
7 |
12 |
Endeavor (Westmere – X5670) |
Parallel Computing Lab / Intel Labs |
320 |
3840 |
32 |
56.9083 |
|
8 |
7? |
(IBM – Blue Gene/Q) |
IBM Research, T.J. Watson |
512 |
30 |
55.8346 |
|
|
9 |
3 |
Franklin (Cray – XT4) |
LBL |
4000 |
16000 |
36 |
19.3274 |
|
10 |
6 |
(SGI – Altix ICE8400EX) |
SGI |
256 |
1024 |
31 |
13.9586 |
次回はアメリカ企業の動きの前半。Cray社は初めてGPUを装備したスーパーコンピュータXK6を発表した。
 |