
HPCの歩み50年記事一覧

スパコンリスト日本

記事寄稿について

インテル、GPUのミスを認め、新たなスーパーコンピューティングチップのロードマップを公開
Agam Shah オリジナル記事

インテルは、CPUとGPUを1つのチップに統合するという野心的な計画を突然撤回した後、スーパーコンピューティングチップのロードマップに加えた大幅な変更について、ようやく具体的な詳細を説明した。
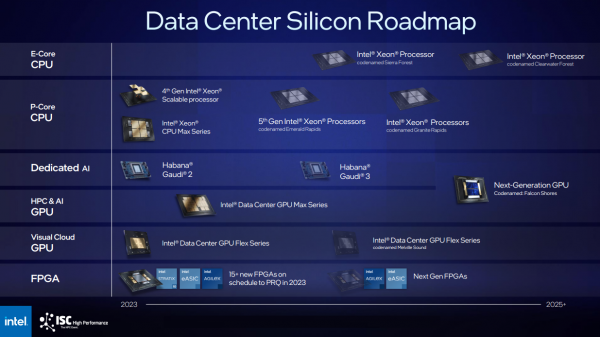
このチップメーカーは、当初XPU(CPUとGPUを統合したもの)になるとされていたFalcon Shoresと呼ばれる次期チップの詳細を公開した。
 |
|
| 軌道修正の結果、Falcon Shoresの当初の計画は保留された。 | |
「CPUとGPUをXPUに統合することに関する私の事前の後押し、強調は時期尚早でした。その理由は、わずか1年前にも思っていたよりも、はるかにダイナミックな市場にいると感じているからです」と、インテルのコーポレートバイスプレジデント兼スーパーコンピューティンググループジェネラルマネージャーのジェフ・マクベイ氏は、プレスブリーフィングで述べている。
新しいFalcon Shoresチップは、ハイパフォーマンスコンピューティングとAIの両方をターゲットにした次世代ディスクリートGPUだ。Gaudi ファミリーの AI プロセッサ(Falcon Shores がリリースされる頃にはバージョン 3 になっている)を搭載し、標準的な Ethernet スイッチング、HBM3 メモリ、IO at scale も搭載している。
「これは、CPUとGPUの比率と同様に、Falcon Shores GPUを他のCPUと結びつけるためのベンダーを超えた柔軟性を提供する一方で、非常に共通のGPUベースのプログラミングインターフェースとCPUとGPUからのCXLを超えた共有を提供し、これらのコードに対する生産性と性能を向上させます」とマクベイ氏は語っている。
Ponte Vecchioのコードネームで呼ばれていたMaxシリーズGPUの後継となるFalcon Shores GPUは、2025年に登場することになった。インテルは3月、Ponte Vecchioの後継として期待されていたRialto Bridgeというコードネームのスーパーコンピュータ用GPUを廃止した。
マクベイ氏は、XPU戦略を追求するにはコンピューティング環境が熟していなかったと述べ、生成系AIモデルや大規模言語モデルに関するイノベーション(そのほとんどは商用分野から生まれたもの)が、次世代スーパーコンピューティングチップの構築方法に関するインテルの考え方を変える引き金になったと付け加えた。
 |
生成AIとLLMは科学的コンピューティングに広く採用され、CPUとGPUを切り離すことで、多様なワークロードを持つ顧客により多くの選択肢を提供する。
「ワークロードが急速に変化するダイナミックな市場では、CPUとGPUの比率を固定化することは避けたいものです。ベンダーや、x86やArmといった使用されるアーキテクチャを固定化することも避けたいのです」 とマクベイ氏は語る。
CPUとGPUの統合は、コスト削減と省電力につながるが、サプライヤーや構成に縛られることになる。しかし、新しいFalcon Shoresではそれが変わるとマクベイ氏は言う。「我々は、現在の市場がどのような状況にあるのか再評価され、統合する時期ではないと感じるだけです」と付け加えた。
スーパーコンピューティング用のCPUとGPUの統合は、近い将来には実現しないが、インテルはこのアイデアをあきらめてはいない。
マクベイ氏は、「適切な時期に、そうするつもりです」と述べ、「環境条件が整えばそうするつもりです。ただ、この次の世代ではそれが正しいとは思っていません」と付け加えた。
また、ディスクリートGPUは、x86以外の異なるCPUでGPUを搭載したシステムを構築する方法について、ベンダーに柔軟性を与えることになる。インテルは、自社の工場でArmベースのチップを生産することにつながる契約を結んだ。
CXL(コンピュート・エクスプレス・リンク)インターコネクトは、GPUやAIチップなどのアクセラレータが大容量のストレージやメモリに簡単にアクセスできるよう、コンポーネントの切り離しを促進し、サーバー設計も変化すると予想される。
「問題は、当社のGPUを他のベンダーのCPUとどのように統合するかという点で、OEMパートナーの肩にかかることが多いということですが、我々は
それが起きることに門戸を開いています。また、PCI ExpressやCXLなどの標準的なインターフェイスを利用することで、非常に効果的にそれを行うことができます」とマクベイ氏は述べた。
しかし、インテルは、今年後半に出荷が予定されているAMDのInstinct MI300からの挑戦に直面しており、ローレンス・リバモア国立研究所にある2エクサフロップス(ピーク)のスーパーコンピュータ、El Capitanを動かす予定だ。現在、Nvidiaは、Google、Facebook、Microsoftが運営するデータセンターで同社のH100 GPUが稼働しており、商用ジェネレーティブAI市場を支配している。
インテルは、NvidiaがCUDAプログラミングフレームワークで採用しているものと同様のGPUプログラミングモデルをFalcon Shoresで利用する。インテルのOneAPIツールキットには、Falcon Shores GPU、Gaudi AIプロセッサ、およびインテルがスーパーコンピューティングチップに搭載するその他のアクセラレータ上で実行できるコンパイラ、ライブラリ、プログラミングツールのファミリがある。
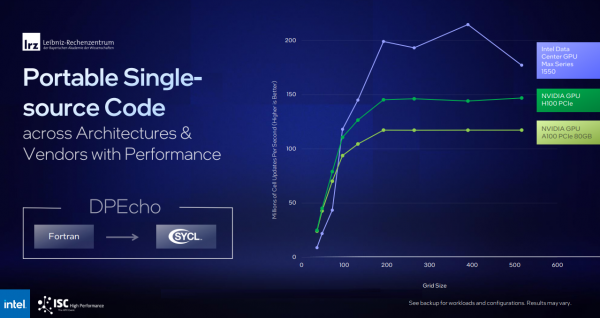
OneAPIのSYCLというツールは、スーパーコンピューティングやAIのアプリケーションを、Intel、Nvidia、AMDのさまざまなハードウェアで動作するようにコンパイルできる。また、Nvidia GPU向けに書かれたアプリケーションを、CUDA固有のコードを削除して再コンパイルすることも可能だ。例えば、LRZはFortranからDPEcho天体物理学コードを移植し、IntelとNvidia GPUの両方で効果的に実行することができた(以下のベンチマーク・スライド)。
 |
インテルは、GPUの軌道修正にとどまらず、その他の開示事項を共有した。
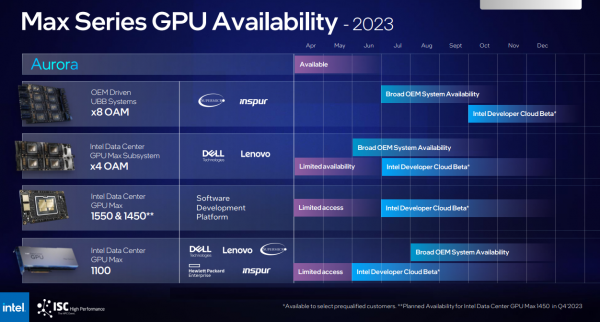
同チップメーカーは、21,248個のCPUノード、63,744個のGPU、10.9PBのDDRメモリ、230PBのストレージを含むAuroraスーパーコンピュータ向けに、HBM搭載Xeon Maxシリーズチップの10,624個以上のコンピュートノードを納入している。
「我々は、完全な最適化、コード上の配信、および受け入れのために行うべき多くの仕事があります。しかし、これは重要な、重要なマイルストーンであり、私たちは…達成できたことを非常に嬉しく思っています」とマクベイ氏は述べた。
 |
Auroraの配備がすでに延期されているため、このマイルストーンはインテルにとって重要である。2エクサフロップス(ピーク)の閾値を超えると予想されるこのスーパーコンピュータは、今年5月の世界最速スーパーコンピュータリスト「Top500」には入らないだろう。
「私たちは、システム全体を安定させ、ベンチマークだけでなく、実際のワークロードを稼動させることに重点を置いています。11月までに、Top500システムで強力な製品を提供できるようにしたいと考えています」とマクベイ氏は述べた。
最近、デル主催のウェビナーで、リック・スティーブンス氏(アルゴンヌ研究所)は、Frontierが重要な科学ワークロードに年間約7800万時間のクアッドGPUを提供すると話している。
インテル、HPE、アルゴンヌ国立研究所を含む主要なHPCプレーヤーは、AuroraGPTと呼ばれる科学計算用の大規模言語モデルを開発するために手を携えており、これは1兆個のパラメータからなる基礎モデルに基づいて構築されており、GPT-3基礎モデルに基づいて構築されたChatGPTよりも大幅に大きくなっている。
生成系AI技術は、利用可能な科学データとテキスト、コードベースに基づいており、市販の大規模言語モデルのように機能する予定だ。この技術がマルチモーダルであり、生成、画像、動画を生成するのかどうかは明らかではない。もしマルチモーダルであれば、研究者が質問し、AIが回答する、あるいはAIを使って科学的な画像を生成する、といった例が考えられる。
LLMは「科学の進歩のために使用され、その訓練と推論にAuroraを活用することは、システムがどのように展開されるかの重要な部分となる」とマクベイ氏は述べている。
AuroraGPTは、材料、がん、気候科学の研究に利用される可能性がある。基礎となるモデルには、メガトロンとディープスピードのトランスフォーマーが含まれている。
インテルはまた、8個のPonte Vecchio MaxシリーズGPUを搭載したユニバーサルベースボード(UBB)システム(ヘッダー図に示す)を、最初はSupermicroとInspurベースのデザインで提供することを発表した。このサーバはAIをターゲットにしており、マクベイ氏によると、8GPUの構成が好まれるとのことだ。この製品は今年初めに発売され、第3四半期にはより広い範囲で利用できるようになる見込み。
 |
特別イベント

寄稿者
![]() 西克也
西克也
西克也はフェアチャイルド社、クレイ・リサーチ社、ベストシステムズ社など、30年以上に渡ってHPCに関する仕事に従事している。Hpcwire Japanの編集長として記事の作成と翻訳を行っている。
![]() 島田佳代子
島田佳代子
1999年~2007年まで英国在住。2001年よりスポーツ、旅、ビジネス、映画など幅広いジャンルで執筆活動を開始し、Hpcwire Japanでは主に日本のHPC業界が世界に誇る研究者、開発者の方々のインタビューを担当。
![]() 小柳義夫
小柳義夫
小柳義夫氏は40年以上に亘ってHPCに携わってきた研究者であり、日本のHPC業界における生き字引として有名。現在 高度情報科学技術研究機構に所属し、産業界のHPC推進にあたっている。
![]() 小西史一
小西史一
小西史一は、理化学研究所、東京工業大学においてHPCおよびバイオインフォマティクスに関する研究と教育に携わってきた研究者。2012年からフォトグラファーとしての活動を開始し、現在はIT技術・セキュリティのコンサルティング業務に携わっている。