
HPCの歩み50年記事一覧

スパコンリスト日本

記事寄稿について

インテル、新しいノード名を発表:Sapphire Rapidsは「Intel 7」CPUに
Tiffany Trader

プロセスノードの技術は他社に比べて約1世代遅れているのに、古い命名規則のために2ノード遅れているように見える場合、優れたチップメーカーはどうすればよいのだろうか?インテルは、リーダーシップを発揮する半導体製造分野における自社の位置づけをよりよく反映させるために、ノードの呼び方を変更することにした。
インテルは、7月26日の午後に生中継された「Intel Accelerated」ウェブキャストにおいて、新しいノードの呼称を明らかにし、プロセスとパッケージングのロードマップの変更を紹介した。2月にインテル社に入社して以来、2回目となるこのような大規模なイベントで、CEOのPat Gelsingerは、同社の「IDM 2.0戦略」、すなわち2024年までに競合他社とのプロセスパリティを達成し、2025年にはリーダーシップをとるという大胆な多面的計画について、多くの詳細を説明した。
「インテルは、業界の他の企業と同様に、プロセスノードについての考え方を進化させる必要があると認識しています。最近では、我々を含む業界全体で使用されている様々な名称や番号のスキームは、もはや特定の測定値を意味するものではなく、電力、効率、性能の最適なバランスを達成する方法の全貌を語るものではありません。」と述べている。
新しい命名方法は、10nm SuperFinの次のノードから始まる。このノードは、(モバイルチップ)Tiger Lakeや、次期Xe-HPC製品であるPonte Vecchioを含むXe GPU製品に使用されている。その次のノードは、これまで10nm Enhanced SuperFinと呼ばれていたが(10nm+++や10nm++とも呼ばれている)、今後は “Intel 7 “と呼ばれることになる。
技術開発担当上級副社長兼ゼネラルマネージャーのAnn Kelleherは、「『インテル7』では、10nm SuperFinに比べてワット当たりの性能が約10~15%向上すると予想しています。トランジスタレベルの最適化を進めてノードを進化させていくと、これは1ノード分の性能向上に相当します。そのため、このノードが提供する競争力のあるパフォーマンスをお客様に理解していただくためには、”Intel 7”という名称が適切であると考えています。」と述べている。
 |
“Intel 7”は、まずクライアント側のAlder Lakeが2021年に出荷開始され、サーバ製品のSapphire Rapidsは2022年の第1四半期に生産が開始されるとKelleherは述べている。
次にロードマップにある”Intel4”は、2022年後半に生産を開始し、2023年に製品の出荷を開始する予定だという。”Intel4”の製品には、クライアント向けのMeteor Lakeとデータセンター向けのGranite Rapidsがある。これは、従来7nmと呼ばれていたノードだ。インテルによると、Meteor Lakeのクライアント向けコンピュートタイルを前四半期(2021年第2四半期)にテープ化したという。
Kelleherは、「実際のウェハを超えて、性能と欠陥密度の期待値に対して、我々が期待しているところにいます。」と語った。「実際、当社の欠陥密度の傾向は、当社の製品コミットメントを満たすための正しい道筋にあります。」と述べている。
“Intel 4”は、極端紫外線リソグラフィ(EUV)を広く使用する最初のインテル・ノードである。
新しいロードマップの次は、2023年後半にデビューする予定の”Intel 3”だ。”Intel 3”は、電力と面積の改善により、”Intel 4”に比べて1ワットあたりのトランジスタ性能が約18%向上するという。Kelleherは、初期のモデリングとテストチップのデータを引用して、標準的なフルノードの改善よりも高いレベルの改善であると指摘した。
改良点としては、高密度で高性能なライブラリの追加、FinFETトランジスタを最適化するための固有駆動電流の増加、ビア抵抗を低減した最適なインターコネクトメタルスタック、”Intel 4”と比較したEUVの使用増加などが挙げられる。
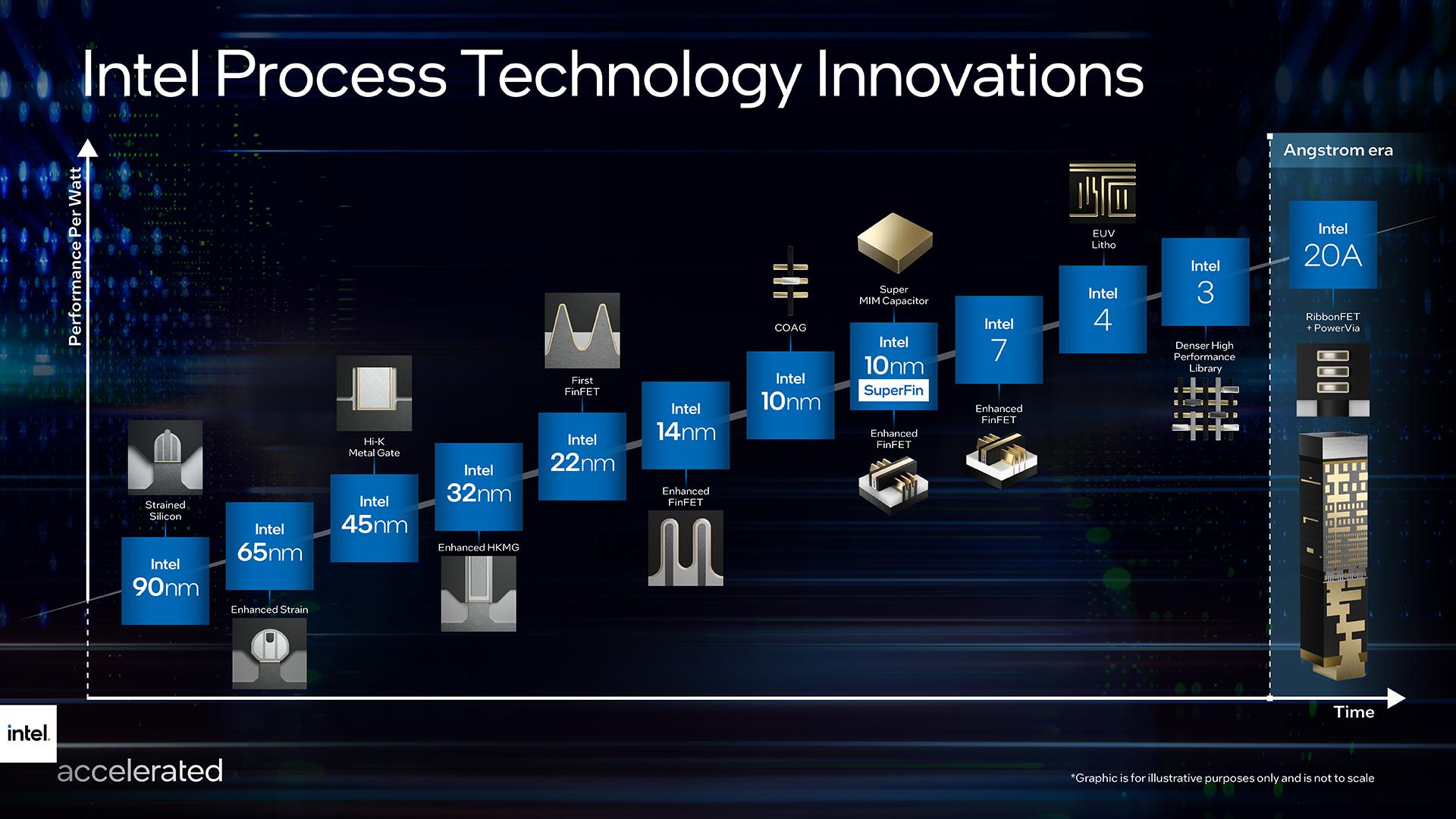 |
“オングストローム時代 “でさらに名前が変わる
ロードマップ上のサプライズは”Intel 20A”で、Aは “オングストローム “を意味する。これは、Gelsingerの言葉を借りれば、”デバイスや材料を原子レベルで作り上げる新しい時代、すなわち半導体のオングストローム時代を想起させる”ことを意図している。1オングストロームは0.1ナノメートルに相当するが、インテルのブランディング用語では、オングストロームは単一の指標ではなく、前世代と比較した「束ねられた」性能指標を表している。
2024年に発売が予定されている”Intel 20A”は、RibbonFETと呼ばれる新しいトランジスタ・ゲート・アラウンド・アーキテクチャと、PowerViaと呼ばれる裏面電源供給メカニズムの2つの新技術を採用している。
 |
|
| RibbonFETは、インテルにとって10年以上ぶりとなる新しいトランジスタ・アーキテクチャだ。説明ビデオはこちら。 | |
「RibbonFETは、インテルが開発したゲート・オール・アラウンド型のトランジスタです。この技術は、より小さなフットプリントで複数のフィンと同じ駆動電流を実現しながら、トランジスタのスイッチング速度の高速化を実現します。」とインテルは述べている。
“PowerVia “は、インテル独自の業界初のバックサイド・パワー・デリバリーの実装であり、ウェハの表側での電源配線を不要にすることで、信号伝送を最適化します。」と述べている。
 |
 |
20Aに続き、2025年初頭には、RibbonFETに改良を加えてトランジスタの性能をさらに向上させる”Intel 18A”の開発が予定されていると、インテルのシニア・バイス・プレジデント兼ロジック・テクノロジー開発担当共同ジェネラル・マネージャーのSanjay Natarajanは述べている。
また、インテルは2025年に新しいリソグラフィーの導入を計画している。次世代のEUV装置は、High numerical aperture EUV(High-NA)と呼ばれている。High-NAでは、より高精度のレンズやミラーを統合し、解像度を向上させることで、シリコン上に微細な形状を印刷できるようになるとインテルは述べている。
さらにインテルは、ゲート・オール・アラウンドとバックサイド・パワーの向上も計画している。Kelleherは、この研究開発が「すでに始まっている」と述べ、Intelは2025年以降の将来ノードとして、積層型のNMOSとPMOSを利用することにすでに取り組んでいると語った。
パッケージング – EMIBとFoverosの次は何だ?
また、IDM 2.0戦略の一環として、新たなパッケージングのイノベーションを発表している。チップの開発がタイル状やチップレット状のアプローチに移行する中、すべてのピースを統合したデバイスにするためには、革新的なパッケージングが必要だ。インテルは、EMIB(embedded multi-die interconnect bridge)とFoverosのダイ・スタッキング技術に続いて、第3世代のFoveros製品であるFoveros Omniと新しいコンパニオン・テクノロジーであるFoveros Directを発表する。
Foveros Omniは、Foverosのコンセプトをさらに発展させたもので、複数のベースタイルと複数のトップタイルを、複数のファブノードで統合することができる。インテル社によると、量産開始は2023年を予定している。
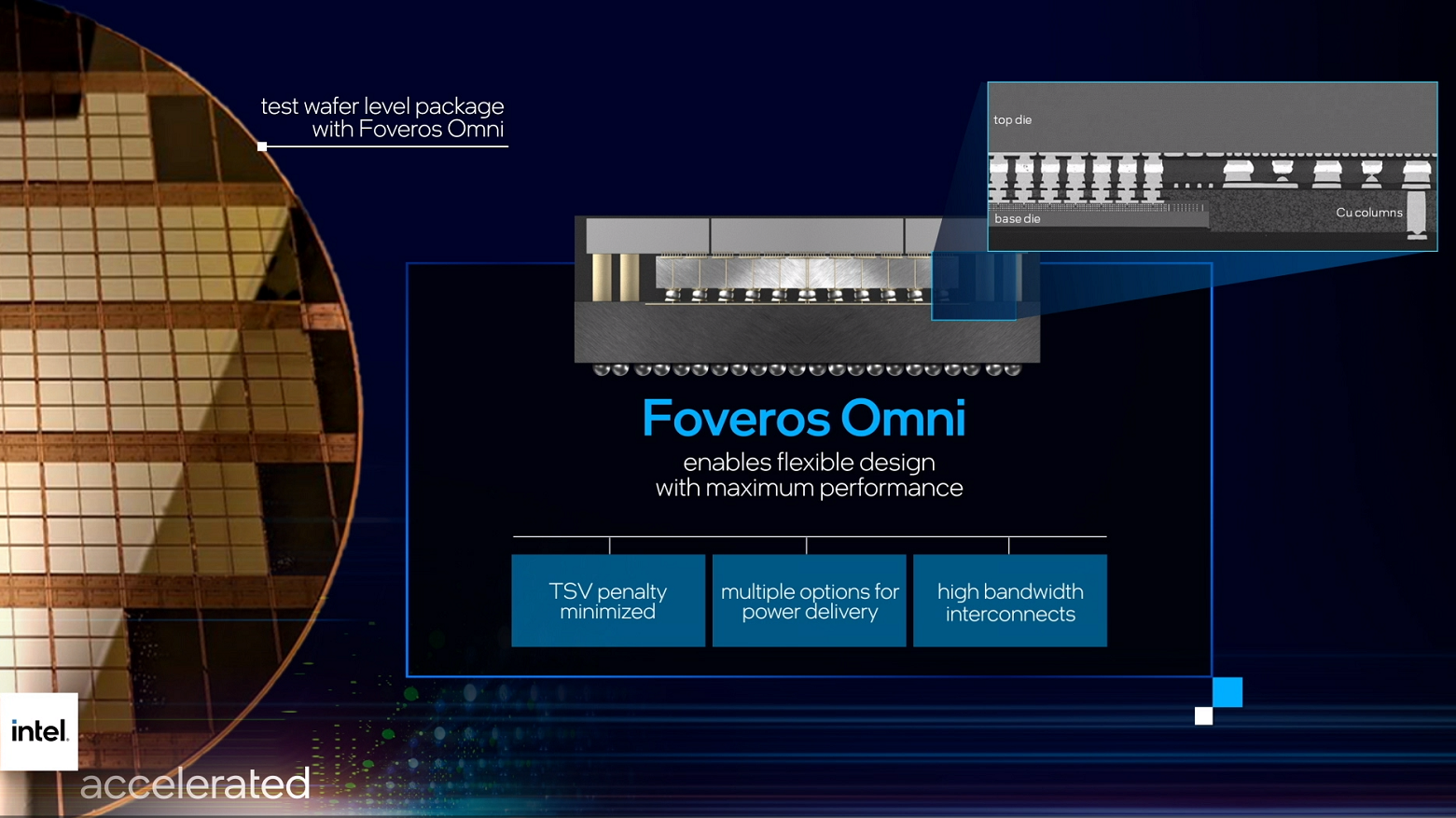 |
インテル副社長兼アセンブリ・テスト技術開発担当ゼネラルマネージャーのBabak Sabiは、「Foveros Omniは、TSV(Through Silicon Via)とパッケージ用銅カラムを組み合わせて使用することで、高速の信号・電力供給と高密度のダイ・ツー・ダイの相互接続を両立させています。この製品は、初代Foverosを改良したもので、ダイ・ツー・ダイ・インターコネクトが36ミクロンから始まり、25ミクロンのマイクロバンプピッチにまで縮小されています。」と述べている。「これにより、バンプ密度は4倍の1,600IO/mm2となり、一方でFoverosと同等のインターコネクトパワーである0.15ピコジュール/ビットを実現しています。」と述べている。
Foveros Directは、Foveros Omniと補完関係にあり、同じ2023年のタイムフレームで発売される。この技術では、銅と銅を直接接合するソルダーレス方式を採用し、低抵抗の配線を実現している。Foveros Directは、10ミクロン以下のバンプピッチを実現し、3D積層のための配線密度を一桁向上させることができるという。
Sabiは、「1mm2あたり10,000個のIOが可能になることで、これまで実現できなかった機能的なダイ・パーティショニングの新しいコンセプトが生まれます。」と述べている。例えば、オンダイ・ロジック・スタッキングのためのマルチレベル・キャッシュを、非常に低いレイテンシーで、しかも電力ペナルティなしに実現することができる。
 |
|
| 昨年8月のインテル・アーキテクチャー・デイでは、Xe-HPC GPU “Ponte Vecchio “は、ベースタイルに10nm SuperFin、Ramboキャッシュタイルに10nm Enhanced SuperFin(現在は “Intel 7 “と呼ばれている)を使用して製造されると述べていた。インテルは、7nmの遅延を発表して以来、コンピュートタイルのプロセスノードを明らかにしていない。 | |
Sabiは、「我々は、どこまでがウエハで、どこからがパッケージングなのかを曖昧にしています。」と述べている。
Sapphire Rapids(現在は “Intel 7 “製品)は、EMIBを搭載して大量に出荷される最初のIntel Xeonデータセンター製品となる。次の世代のEMIBは、バンプピッチが55ミクロンから45ミクロンになり、続いて第3世代では40ミクロンになる予定だ。インテルのGPU「Ponte Vecchio」は、EMIBと36ミクロンのバンプピッチを実現した第2世代の「Foveros」の両方を採用した初めての製品となる。
Intel Foundry Servicesの新しい顧客: AWSとクアルコム
3月にスタートしたインテルのファウンドリーサービス(IFS)事業に、初めて公称された顧客が登場した。AWSとクアルコムだ。AWSは、IFSのパッケージング・ソリューションを使用する最初の顧客であり、クアルコムは将来の20Aプロセス技術のパートナーとなる。「インテルとクアルコムの両社は、モバイルコンピューティングプラットフォームの先進的な開発と、半導体の新時代の到来を強く信じています。」とGelsingerは述べている。
さらにCEOは、インテルはIFSのパイプラインに100以上の顧客を抱えていると付け加えた。「これらの契約は非常に順調に進んでいます。」と述べた。「その中には、今回発表したAWSのようなパッケージング技術のものもあれば、私がモダンノードと呼んでいるIntel 16や16nmプロセスのものもあり、Intel 20AやIntel 18Aにも多くの関心が寄せられています。」と述べた。
将来の顧客の特徴として、Gelsingerは「非常に伝統的な企業もあれば、過去に我々の競争相手と見られていたかもしれないが、今は一緒に仕事をしている……工業や自動車関連の企業もあるし、ファウンドリを活用する機会を必要としている他の半導体企業もあります。」と述べている。
また、Intel InnovatiONは、2021年10月27日~28日にサンフランシスコとオンラインで開催される完全なハイブリッドイベントになることも発表された。詳細は、Intel ONのランディングページでご覧いただけます。
特別イベント

寄稿者
![]() 西克也
西克也
西克也はフェアチャイルド社、クレイ・リサーチ社、ベストシステムズ社など、30年以上に渡ってHPCに関する仕事に従事している。Hpcwire Japanの編集長として記事の作成と翻訳を行っている。
![]() 島田佳代子
島田佳代子
1999年~2007年まで英国在住。2001年よりスポーツ、旅、ビジネス、映画など幅広いジャンルで執筆活動を開始し、Hpcwire Japanでは主に日本のHPC業界が世界に誇る研究者、開発者の方々のインタビューを担当。
![]() 小柳義夫
小柳義夫
小柳義夫氏は40年以上に亘ってHPCに携わってきた研究者であり、日本のHPC業界における生き字引として有名。現在 高度情報科学技術研究機構に所属し、産業界のHPC推進にあたっている。
![]() 小西史一
小西史一
小西史一は、理化学研究所、東京工業大学においてHPCおよびバイオインフォマティクスに関する研究と教育に携わってきた研究者。2012年からフォトグラファーとしての活動を開始し、現在はIT技術・セキュリティのコンサルティング業務に携わっている。