
HPCの歩み50年記事一覧

スパコンリスト日本

記事寄稿について

AMDがCUDAの堀を越えるには?
Doug Eadline オリジナル記事はこちら

生成AIについて議論するとき、ほとんどの場合「GPU」という言葉が会話に登場し、話題はしばしばパフォーマンスやアクセスに移る。興味深いことに、”GPU “という言葉は “エヌビディア “製品を意味すると思われている。(余談だが、生成AIで使われている一般的なエヌビディアのハードウェアは、厳密にはグラフィカル・プロセッシング・ユニットではない。SIMDユニットと呼んだ方がいい)
生成AIとGPUがエヌビディアと結びついたのは偶然ではない。エヌビディアは、市場を成長させるためのツールやアプリケーションの必要性を常に認識している。彼らは、エヌビディア・ハードウェア用のソフトウェア・ツール(例えば、CUDA)や最適化されたライブラリ(例えば、cuDNN)を入手するための障壁を非常に低くしている。実際、エヌビディアはハードウェア企業として知られているが、エヌビディアの応用ディープラーニング研究担当副社長であるブライアン・カタンザロ(Bryan Catanzaro)氏は次のように述べている。「多くの人はこのことを知らないが、エヌビディアにはハードウェアエンジニアよりもソフトウェアエンジニアの方が多いのです。」
その結果、エヌビディアはハードウェアの周りに強力なソフトウェアの「堀」を築いた。CUDAはオープンソースではないが、自由に利用でき、エヌビディアの強固な管理下にある。このような状況はエヌビディアに利益をもたらしているが(当然である。 彼らはCUDAに時間と資金を投資したのだから)、代替ハードウェアでHPCや生成AI市場の一部を獲得しようとする企業やユーザーにとっては困難を生み出している。
キャッスル・ファウンデーションの構築
生成AI用に開発された基盤モデルの数は増え続けている。これらの多くは、自由に使用し共有することができるため、「オープンソース」である。(例えば、Meta社のLlama基礎モデルなど)加えて、これらのモデルを作成するには多くのリソース(人とマシンの両方)が必要であり、主に大量のGPUを利用できるハイパースケーラーに限られている(AWS、Microsoft Azure、Google Cloud、Meta Platforms、Apple)。ハイパースケーラーに加えて、他の企業もハードウェアに投資して(つまり大量のGPUを購入して)独自の基盤モデルを作成している。
研究の観点からは、モデルは興味深く、様々なタスクに使用することができる。しかし、期待される用途とさらに多くの生成AIコンピューティングリソースの必要性は2つある;
- ファインチューニング – 基礎となるモデルにドメイン固有のデータを追加し、ユースケースに対応させる。
- 推論 – モデルが微調整されると、使用(質問など)時にリソースが必要になる。
これらのタスクはハイパースケーラーに限定されるものではなく、アクセラレーテッド・コンピューティング、つまりGPUを必要とする。明らかな解決策は、「入手不可能な」エヌビディアGPUをさらに購入することであり、需要が供給をはるかに上回っている今、AMDは準備万端で待機している。公平を期すために、インテルや他の企業もこの市場に売り込む準備をして待っている。重要なのは、ファインチューニングと推論が浸透するにつれ、生成AIはGPU(またはアクセラレータ)の稼働率を圧迫し続けるということだ。
エヌビディアのハードウェアから離れるということは、他のベンダーのGPUやアクセラレータが、多くのモデルやツールを実行するためにCUDAをサポートしなければならないことを示唆している。AMDは、HIP CUDA変換ツールによってこれを可能にした。しかし、最良の結果は、エヌビディアの城を取り巻くネイティブツールを使用することが多いようだ。
PyTorchの跳ね橋
HPC分野では、CUDA対応アプリケーションがGPU加速の世界を支配している。移植コードは、GPUとCUDAを使用することで、しばしば5~6倍のスピードアップを実現できる。(注:すべてのコードがこのスピードアップを実現できるわけではなく、GPUハードウェアを使用できない場合もある) しかし生成AIでは、話はまったく異なる。
当初、TensorFlowはGPUを使ってAIアプリケーションを作成するためのツールとして選ばれていた。TensorFlowはCPUでも動作し、GPU用のCUDAで高速化された。この状況は急速に変化している。
TensorFlowに代わるものとして、ニューラルネットワークベースのディープラーニングモデルを開発・訓練するためのオープンソースの機械学習ライブラリであるPyTorchがある。フェイスブックのAI研究グループが主に開発している。
AssemblyAIのDeveloper Educatorであるライアン・オコナー(Ryan O’Connor)氏による最近のブログポストでは、人気サイトHuggingFace(数行のコードで、学習・調整された最先端のモデルをダウンロードしてアプリケーションパイプラインに組み込むことができる)では、利用可能なモデルの92%がPyTorch専用であると指摘している。
さらに、図1に示すように、機械学習の論文を比較すると、PyTorchに大きな傾向があり、TensorFlowから離れていることがわかる。
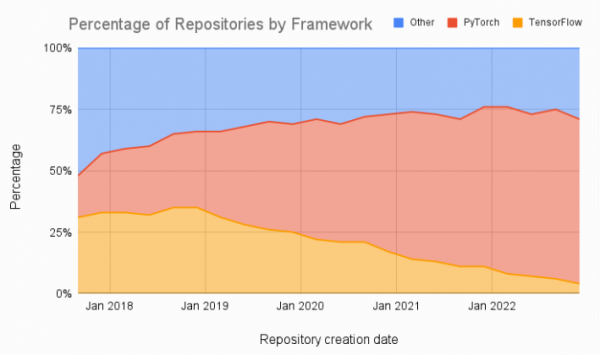 |
| 図1:PyTorch、TensorFlow、または別のフレームワークを経時的に利用する論文の割合(データは四半期ごとに集計、2017年後半から)、出典:assemblyai.com |
もちろん、PyTorchの下にはCUDAへの呼び出しがあるが、PyTorchは基礎となるGPUアーキテクチャからユーザーを隔離しているため、その必要はない。また、AMD GPUプログラミング用のオープンソースソフトウェアスタックであるAMD ROCmを使用するバージョンのPyTorchもある。AMD GPU向けのCUDAの堀を越えるのは、PyTorchを使うのと同じくらい簡単かもしれない。
推論の本能
HPCと生成AIの両方において、共有メモリH100 GPUを搭載したエヌビディアの72コアARMベースGrace-Hopperスーパーチップ(および144コアGrace-Graceバージョン)が大いに期待されている。エヌビディアがこれまでに発表したすべてのベンチマークは、GPUをPCIeバスに接続してアクセスする従来のサーバーよりもはるかに優れた性能を示している。Grace-Hopperは、HPCと生成AIの両方に最適化されたハードウェアである。また、ファインチューニングと推論の両方で幅広く利用されることが期待される。需要は高いと予想される。
AMDは2006年以来、共有メモリCPU-GPU設計を採用してきた(AMDは2006年にグラフィックカード会社ATIを買収)。Fusionブランドとして始まった多くのAMD x86_64プロセッサーは現在、Accelerated Processing Unit(APU)と呼ばれるCPUとGPUを組み合わせたものとして実装されている。
AMDの近日発売予定のInstinct MI300Aプロセッサー(APU)は、Grace-Hopperスーパーチップと競合することになる。また、ローレンス・リバモア国立研究所で間もなく公開されるEl Capitanにも搭載される。統合型MI300Aは、最大24個のZen4コアとCDNA 3 GPUアーキテクチャー、最大192GBのHBM3メモリーを組み合わせ、すべてのCPUコアとGPUコアに均一なアクセスメモリーを提供する。チップ全体のキャッシュ・コヒーレント・メモリにより、CPUとGPU間のデータ移動が削減され、PCIeバスのボトルネックが解消され、性能と電力効率が向上する。
AMDは、来るべき推論市場に向けてInstinct MI300Aの準備を進めている。AMDのCEOであるリサ・スーは、最近のYahoo!Financeの記事で、「我々は、アーキテクチャのいくつかの選択により、推論ソリューションの業界リーダーになると考えている 」と述べている。
AMDをはじめとする多くのハードウェアベンダーにとって、PyTorchは基盤モデル周辺のCUDA堀の跳ね橋を下ろしたことになる。AMDはInstinct MI3000Aバトルワゴンを準備している。生成AI市場におけるハードウェアの戦いは、性能、移植性、可用性によって勝敗が決するだろう。AIの日はまだ浅い。
特別イベント

ISC 2026
6月 22 - 6月 26
International Conference for High Performance Computing, Networking, Storage & Analysis (SC26)
11月 15 - 11月 20
寄稿者
![]() 西克也
西克也
西克也はフェアチャイルド社、クレイ・リサーチ社、ベストシステムズ社など、30年以上に渡ってHPCに関する仕事に従事している。Hpcwire Japanの編集長として記事の作成と翻訳を行っている。
![]() 島田佳代子
島田佳代子
1999年~2007年まで英国在住。2001年よりスポーツ、旅、ビジネス、映画など幅広いジャンルで執筆活動を開始し、Hpcwire Japanでは主に日本のHPC業界が世界に誇る研究者、開発者の方々のインタビューを担当。
![]() 小柳義夫
小柳義夫
小柳義夫氏は40年以上に亘ってHPCに携わってきた研究者であり、日本のHPC業界における生き字引として有名。現在 高度情報科学技術研究機構に所属し、産業界のHPC推進にあたっている。
![]() 小西史一
小西史一
小西史一は、理化学研究所、東京工業大学においてHPCおよびバイオインフォマティクスに関する研究と教育に携わってきた研究者。2012年からフォトグラファーとしての活動を開始し、現在はIT技術・セキュリティのコンサルティング業務に携わっている。