
HPCの歩み50年記事一覧

スパコンリスト日本

記事寄稿について

NVIDIA HPC WEEK 「スケーラブルかつ高速なデータ駆動型大規模物理シミュレーション」- 東京大学地震研究所 市村強氏
2021年10月25日 エヌビディア合同会社が主催するNVIDIA秋のHPC Weeks 3週目では、GPU Applicationsをテーマとして、産業界で注目されているアプリケーションや、幅広いジャンルにおけるGPUを利用した迫力のある計算成果や手法について、第1部と第2部を通して、実に11セッションもの特徴のある魅力的な事例紹介が行われた。

その中でも、第2部の基調講演として、世界でも類を見ない規模でGPUを使った事例として、これまで3回のゴードン・ベル賞のファイナリストに選出されている事で知られる、東京大学地震研究所計算地球科学研究センター・センター長の市村 強 教授による「スケーラブルかつ高速なデータ駆動型大規模物理シミュレーション」と題された講演が行われた。
そこでは、シミュレーション手法の高度化と、その過程で生まれるデータを対象とした学習により、一次方程式求解の大幅な高速化を実現する事で、かつて無い規模と解像度での物理ベースの大規模シミュレーションのスケーラブルな高速化を実現した事例について解説されたので、ここで紹介したい。
市村教授は、扱われている大規模なシミュレーションについて、前半後半で大きく分けて2つの解説を行った。前半では、首都圏の大規模地震シミュレーションと、そのGPU計算適用にOpenACCを利用した事例と、AIによるデータ駆動型の物理シミュレーションの高度化、特に微分方程式の求解を学習したAIによる事例について等、最新の結果や状況について織り交ぜながら、現在のHPCによる大規模シミュレーションの現状について、詳しく説明があった。
首都圏の大規模地震シミュレーション
まず冒頭で、SC14、SC15において、ゴードン・ベル賞のファイナリストに選出された際の京コンピュータを用いた首都圏の大規模地震シミュレーションを例として、現在手がけている対象の問題について、分かりやすく解説していただいた。
そのなかで、シミュレーションの目的を、一言で言えば、「市民・行政・技術者の共通認識構築のために、起こりうる震災を分かりやすく可視化した震災情報を提供する」ことにつきるとしている。その実現の為に、現在入手可能な詳細な構造物に関する空間情報を取り込み、仮想的な現実に存在する都市を精密に計算機上に構築し、計算された地震動によってこれらを揺らす事で、その都市の震災の様子を観測する事が可能となると、手法の概略を説明する。
そして、この大規模なシミュレーションの結果は、現実の都市に存在する各種構造物の被害状況を予測し、わかりやすく可視化して提供する事になる。さらに、当然なことであるが、シミュレーションとして実行されるため、多数のシナリオを提示する事もでき、結果として、事前の震災対策・地震時の挙動・緊急対応・復旧対応などの多面的な状況を考慮した震災のマネジメントシステムへ繋げる研究となる。
これらの一連の流れに関しては、デジタルツインを用いた都市地震シミュレーターの実現と、その応用を研究する者にとっては、分かりやすい利用の流れであるのだが、そこで課題となるのは、その求められる領域が大きいこと、そして、要求される空間の分解能がとりわけ高いことあり、この種のシミュレーション計算の規模は、非常に大きくなる。
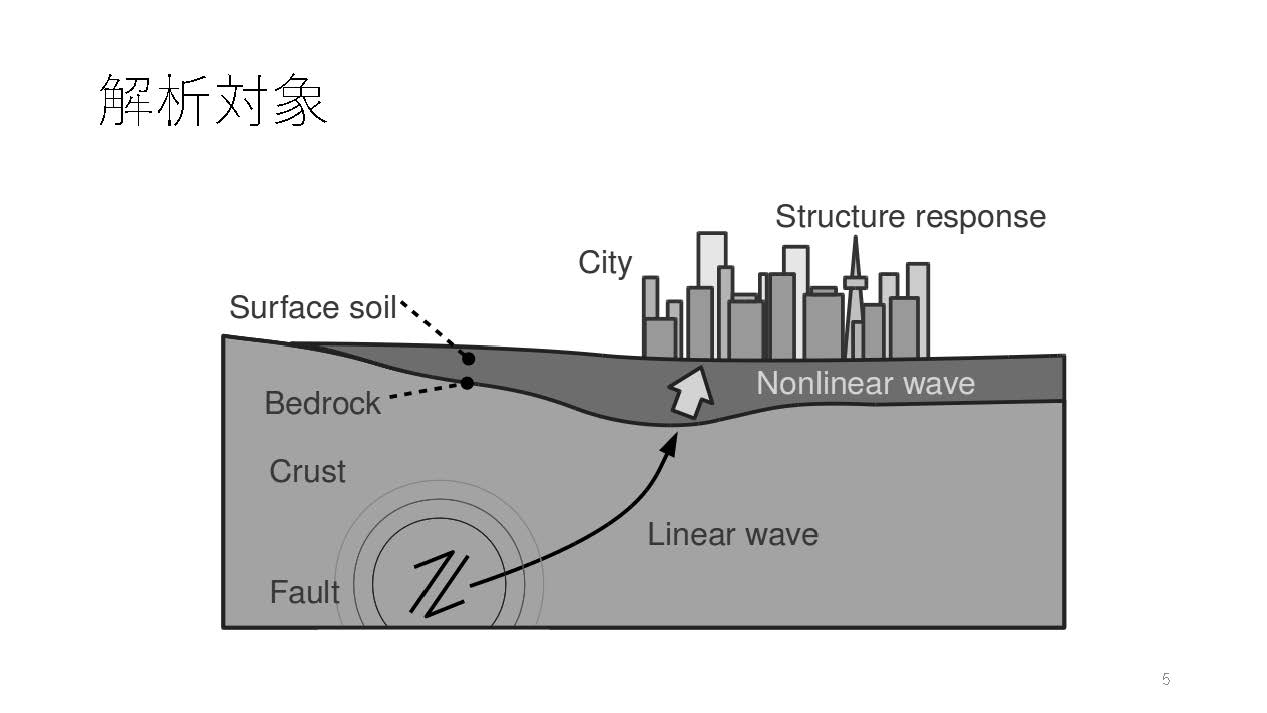 |
| 図1 大規模地震シミュレーションの解析対象の概観 (講演資料より) |
地震シミュレーションの解析を行う際には、図1のような地殻構造の中で、まず断層が破壊され、地表に地震動として伝わっていく事からスタートする。そして、地表近傍の堆積層と言われる非線形を示す場所で揺れが増幅されて、最終的に都市に揺れが伝わっていく。
この一連の過程をシミュレーションしたいわけだが、その範囲は数十キロから百キロ程度のオーダーとなる。同様に、深さに関しても、数十キロから百キロのオーダーとなる規模を扱う事からも、非常に大きなボリュームを対象としている。一方、地表にある構造物に対して、求められる空間の分解能は非常に高いために非常に大規模な計算量になると見積もられる。
都市・構造物の被害想定等の地震対策用シナリオ構築のために、地震時の地表面の揺れの分布に関する情報が面的に必要になる。一方、地震の揺れは、その振動が伝わった場所により大きく異なる事が知られていて、この地表面の近傍における揺れは、地盤増幅と呼ばれ、100メールぐらいの深さで存在する柔らかい層(東京であれば、30メートルぐらいの層)の3次元的な、非常に複雑な地盤構造によって、下から入ってくる入力基盤地震動が増幅される強い非線形性を示す事が知られている。
最近では、この地盤の情報に関して整備されてきており、10mオーダーの起伏を持つ3D地盤構造データが整備され、地表面の標高だけでなく、複数の層の層境のデータに関しても利用できるようになってきている情勢となっている。
この地盤増幅解析を行うためには、専門的に言えば、低次の非構造要素を用いた陰的時間積分非線形波動有限要素解析を行う事が必要となる。つまり、地盤構造の幾何形状を正確にモデル化して、応力フリーの境界条件を解析的に満足させること。そして、高い不均質性や強い非線形を解析するために、安定性の観点から陰的時間積分が必要になる。
地震の揺れを解析するために、有限要素法で非線形の波動方程式の解析を行う方法論は、これまで、よく知られている事であるが、未知の変数が1000億自由度を持つ事で、極めて大きな、離散化された非線形波動方程式を解く事になり、陽的時間積分と比較して格段に難しくい問題となっている。
この問題に対して、この地盤構造解析に合った大規模有限要素解析手法を新たに開発した。通常このような大規模問題に対して利用する、共役勾配法 (Conjugate Gradient Method, CG 法)に、前処理という形で、通常は何らかの処理をするが、開発した新しい方法では、可変的な前処理を行うとして開発を行った。
この可変的前処理では、等価な粗い問題を解けば良い事から、四面体1次と2次のジオメトリックマルチグリッドに入れる事や、精度混合演算を適用する処理を行い、階級間の疎密や演算空間の粗密を使った処理を行った。その処理の効果の1つとして、通信量の削減にもつながり、超並列計算に適した大規模有限要解析のソルバーとして開発する事が出来た。これはSC14,SC15でゴードン・ベルのファイナリストとして評価された。
この大規模有限要素解析手法は、京、Oakforest-PACS、富岳、Summit、Piz Daintなどでも、良好なスケーラビリティを示す性能が発揮された事から、CPUでもGPUでも高速に機能する手法である事を確認している。
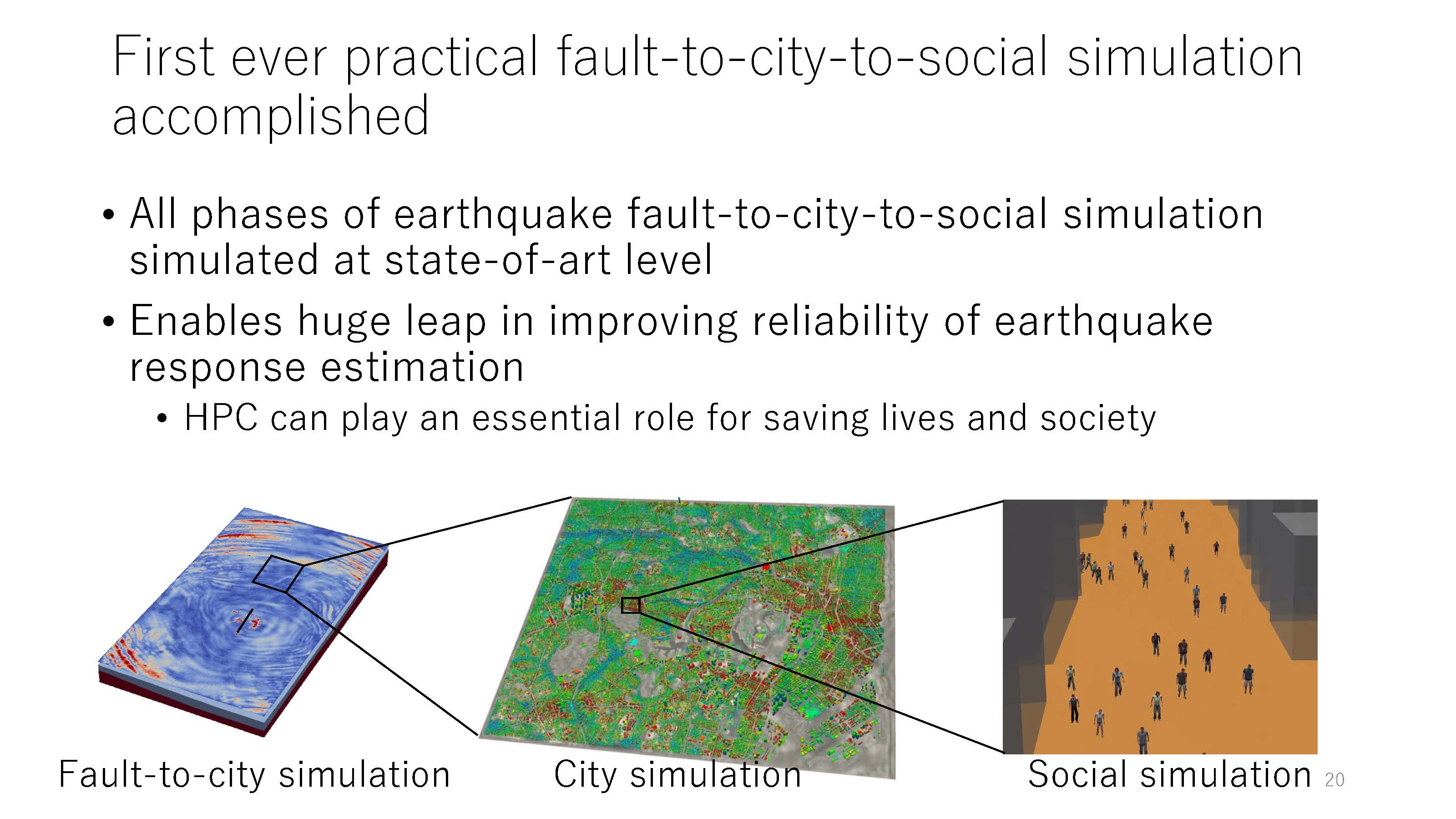 |
| 図2 断層・都市・社会の一気通貫地震シミュレーション(講演資料より) |
断層・都市・社会の一気通貫地震シミュレーション
首都圏の山手線内を対象とした仮想首都直下地震のシミュレーションにおいて、今回開発したソルバーを使い、この首都東京の山手線全域における大規模有限要素解析を行った。この計算には、京コンピュータ全系と使用計算時間を8時間として、シミュレーションを行った。
まず、断層から地表までの地震動シミュレーションを行った。そのシミュレーションでは、10Hzまでの精度保証した非構造有限要素による地震動をシミュレーションした。その計算機規模を示す自由度は、低次非構造有限要素は180億自由度であり、560億自由度の陰的時間積分の計算を行った。
その際の自由度は、1336億自由度と、かなりの規模の問題となった。このような大規模なモデルに対して、地震動を入れる事で、地盤の固い場所や柔らかい場所などの地盤構造を反映した地震動の影響がどの様に現れるかを、有限要素解析として通常のCAEの枠組みで計算する事ができる。この計算で導き出された、複雑に増幅された地震動を、さらに地表にある32.8万棟の個々の構造物の非線形地震応答を計算する事で、首都東京全体の非常に複雑な揺れを計算する事ができた。
最終的に、得られた都市の揺れを踏まえて、その全域に存在する200万人の個人を表すエージェント、つまり、自律的に環境を判断して行動するエージェントモデルを使って、個別の構造物のシミュレーション上で計算された揺れの中で、個人の行動に起因する集団的行動や人流に関する避難解析を行う事が、京コンピュータを使ったプロジェクトの中で達成する事ができた。このような非常に大規模な震災に関するシミュレーションを行った例はまだ世界に無いため、現時点でも唯一の結果といえる。
OpenACCによるGPU化
先に紹介した地盤振動解析は、比較的単純な構成則を使ってきたので、構成則自体の計算の負荷は大きくなったが、より高精度な信頼性の高いシミュレーションを行う場合には、より複雑な構成則を使う必要性が出てくる。そのような高精度化を行う際にOpenACCによるGPU化を行った例について紹介する。
今回対象とするのは地震の揺れによって、地盤が液状のように振る舞う現象として知られてきた地盤液状化現象になる。この現象は、地盤が液状化するという事、つまりマルチフィジックスに関する解析をする必要性が出てくる。そのため、この現象を扱うための構成則は、地盤振動解析と比較して複雑になる。この3次元液状化解析は、ニーズがあるにも関わらず、まだそれほど高性能計算が適用されている分野ではないため、28万自由度で4万ステップの3次元解析で、CPUによる計算で約1ヶ月程度の逐次計算で行われている程度の解析であった。
この3次元液状化解析を高速に行うにあたり、SC14で発表した通常の3次元地震応答解析のための大規模解析手法を元に、新たにGPUを利用した大規模3次元液状化解析手法を開発し、OpenACCを使いソルバーの実装を行った。
液状化を考慮した3次元地震応答解析においては、その支配方程式は変わらないが、地盤の構成則の線形層と非線形層の2つの内、非線形層において、シミュレーション内で生成されるデータを使いながら逐次的に評価を行い進行する、マルチスプリングモデルによる実装を行うために高い計算コストが要求される。
GPUを利用するにあたり、先の構成則の線形要素と非線形要素の割合が、MPIプロセス毎に異なるため、ロードバランスが崩れる現象が起きる。また、解析ループ内において、分岐が発生しGPU計算での性能の低下についても課題があった。そこで、線形層と非線形層のそれぞれで並列化を行い、MPIプロセスのロードバランスを改善し、解析ループ内分岐を解消する事でGPUに適した計算となり、大幅に性能の向上を実現する事ができた。
並列計算自体はGPUにより高速化されるが、並列計算時の通信がボトルネックとなり、通信量の削減の必要性の課題が顕著化する。そこで、通信量を削減するために「解の精度」に影響しない範囲で、求解中にFP21を使う事で、その必要とされるX,Y,Zの3成分の情報をFP64に詰め込む事ができ、結果として通信量の削減を実現でき、CPU版と比較して10.7倍の解析の高速化を達成する事ができた。
 |
| 図3 性能計測結果(講演資料より) |
図3の大規模解析の性能測定結果にもあるように、8900万自由度の計算で、Oakforest-PACSでは、128ノードで14時間程度かかってきた計算が、ABCIの13計算ノード(52GPUs:NVIDIA Tesla V100-SXM2)で、3時間半で実行する事ができた。よって、OpenACCによりGPU化された実装のコードでは、より小規模な計算環境でも、高速に解析が実現可能となる事を示す事ができた。
物理シミュレーションの高度化と人工知能の融合に向けて
先ほどまで紹介した地盤増幅解析を計算する例では、インピーダンスコンストラクト比が無い媒質の中での非線形波動関数の解析であったと言える。言い換えれば、東京の様に、非常に堅い建物が地盤の中に埋め込まれており、それらの相互作用が本来存在している。つまり、地盤と構造物を分けて計算するのではなく、一括して計算をしたいというニーズがある。これは、地上構造物・地下構造物・地盤のフルカップルの超高分解能シミュレーションを行いたいが、解析的に格段に収束性が悪くなるため、これまでは、容易に扱う事ができない問題とされてきた。SC18で発表した新しいシミュレーションの高度化では、この収束性を改善するために人工知能を利用する事で改善を試みた。
基本的なアプローチは、人工知能を使い、対象とする系を学習し、方程式求解を高速化するという事で、微分方程式(支配方程式)の持っている情報と、離散化による2つの情報を、データ解析により、解きにくさを分析し、その部分をAIにより抽出し、重点的に反復の回数を増やすなどの処置を行う事で優先的に求解を行い、結果として、全体で実効する計算量を減らすというアプローチをとった。そして、SC14で発表したソルバーとSC18の新しいソルバーをWeak Scalingで評価すると、4倍程度の実効性能の向上と、良好なスケーラビリティを達成する事ができた。
Tensor コア を用いた物理シミュレーション
 |
| 図4 Tensor コアを用いた物理シミュレーション(講演資料より) |
次に、これまでの話とは異なり、人工知能用に開発された低精度・高速アクセラレータとなるTensor コアをHPC物理シミュレーションで活用する試みを行った。 NVIDIAのVolta GPUにおいては、FP64演算7.8 TFLOPSに比べて、Tensor コア は、125 TFLOPSと、約16倍高いピーク性能を持つ。しかしながら、制約として低精度演算である事や、局所性の高い演算の必要性や、定型の行列積などの制約があるが、このアーキテクチャーを活用できるようにしたい。それには、従来のHPC物理シミュレーションとは、異なる制約を持つアーキテクチャーに合うアルゴリズムを開発する必要がある。
もともと、低次の非構造の有限要素法では、FP64で対象の問題を解きたいという目的がある。そして、可変的前処理の内側で、粗く問題を解く事は、すでに説明した通りとなる。その時に、Tensor コアが非常に計算処理が速いために、通信に関してはINT14などの低精度のデータ構造を使い演算と通信のバランスを確認していた。そして、このような処置と同時にTensor コアが高速にデータに対してアクセスする事ができるように、構造格子状にマッピングをした上で、Tensor コアで計算する方法を取った。構造格子にマッピングする処理を行うため、一見では非効率な処理を行っているように見える。しかし、図4のグラフにあるように、演算数が増えているにもかかわらず、Tensor コアの演算速度が非常に速いために、全体の実効時間が大幅に改善され、3.98倍もの高速化が実現できている。
ここから従来のアルゴリズムのように演算量を減らす方法だけでなく、今回のようなアーキテクチャーの特徴を有効活用するような、アルゴリズムを開発する事で、一見非効率に見えるけれども、time to solutionの改善につながる方法がある事がわかり、今後のアルゴリズム開発の幅が広がった好例といえる。
以上のように、首都圏の超大規模地震シミュレーションに対する研究を積み重ねてきたなかで実証してきた成果では、従来の物理シミュレーションのアルゴリズムをデータサイエンス的な改良を加えるなどの手法のように、HPC物理シミュレーションとデータ駆動的なアプローチの融合が、様々な方向性に対して行われてきている。
さらに、計算量やアルゴリズムの評価といった視点では、CPUやGPU等が持つ演算器での浮動小数点の加算や乗算演習の最小単位を1FLOPとしてみた場合に、求める結果を得るまでに必要なFLOPの総数をできるだけ少なく最適化する方法をとるのが一般的である。
しかし、その精度に制限があっても、超高速な演算を実行できるAI等の特定の用途向けの演算機構であるTensor コア等を活用する場合には、違うアプローチが考えられる。
計算機構に沿った形式的なデータ構造の変形などの適用を施すだけで、その実効FLOP数の観点から、たとえFLOP数が大幅に増えても、結果をえるまでも時間が短くなるような、より強力なアルゴリズムの設計が可能になる。
このように、さらなる大規模化、高解像度化される対象に対する、新しい方向性の成果が出てきていることから、今後期待できる超大規模地震シミュレーションの高速化の手法の1つになっていく。
特別イベント

寄稿者
![]() 西克也
西克也
西克也はフェアチャイルド社、クレイ・リサーチ社、ベストシステムズ社など、30年以上に渡ってHPCに関する仕事に従事している。Hpcwire Japanの編集長として記事の作成と翻訳を行っている。
![]() 島田佳代子
島田佳代子
1999年~2007年まで英国在住。2001年よりスポーツ、旅、ビジネス、映画など幅広いジャンルで執筆活動を開始し、Hpcwire Japanでは主に日本のHPC業界が世界に誇る研究者、開発者の方々のインタビューを担当。
![]() 小柳義夫
小柳義夫
小柳義夫氏は40年以上に亘ってHPCに携わってきた研究者であり、日本のHPC業界における生き字引として有名。現在 高度情報科学技術研究機構に所属し、産業界のHPC推進にあたっている。
![]() 小西史一
小西史一
小西史一は、理化学研究所、東京工業大学においてHPCおよびバイオインフォマティクスに関する研究と教育に携わってきた研究者。2012年からフォトグラファーとしての活動を開始し、現在はIT技術・セキュリティのコンサルティング業務に携わっている。