
HPCの歩み50年記事一覧

スパコンリスト日本

記事寄稿について

新たなHPC Research:TensorFlow、Buddy Compression、Intel Optaneなど
Oliver Peckham
HPCwireは、この2か月に1回の特集において、ハイパフォーマンス・コンピューティングコミュニティおよび関連分野で新たに発表された研究に焦点を当てている。下記詳細のとおり、並列プログラミングからエクサスケール、量子コンピューティングまで、幅広く取り上げる。
 |
|
HPCアプリケーションにおけるTensorFlowのパフォーマンスの評価
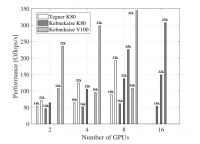
異なるハードウェア上での分散アプリケーションの使用をサポートする新しいオープンソースフレームワーク「TensorFlow」 は、MLアプリケーションで人気が高まっている。本稿においてスウェーデン王立工科大学、South Park Commonsおよびオークリッジ国立研究所のチームは、スーパーコンピュータでHPCワークロードを実行するためのTensorFlowの実用性について議論している。その中で彼らは4つの従来のベンチマークHPCアプリケーションを設計し、TensorFlowが高性能ネットワークとアクセラレータを最大限に活用できることを実証している。
著者:Steven W.D. Chien、Stefano Markidis、Vyacheslav Olshevsky、Yaroslav Bulatov、Erwin Laure、Jeffrey S. Vetter
高性能な気象・気候モデルにおけるスケーラビリティとパフォーマンスの移植性の実現
本稿では、バース大学のEike Müllerが、統一モデルを置き換えるために英国気象庁によって開発された新しい高性能の気象・気候モデル「LFRic」について議論している。Müllerは、PSycloneと呼ばれるアプリケーションによって可能になる、科学的コードと並列コードとの間の「関心の分離」に焦点を当てている。そして科学的要件の概要、ソフトウェア基盤の設計、さらにはPSycloneの使用例を提示している。
著者:Eike Müller
 |
|
「バディ圧縮」を使用して、GPUでのディープラーニングおよびHPCワークロードのために大容量メモリを可能にする
GPUはCPUのみのシステムよりも高いメモリバンド幅を提供することができるが、それらのメモリは比較的小さく、拡張することができない。テキサス大学オースティン校とNVIDIAのチームによって書かれた本稿では、メモリ拡張技術の典型的な落とし穴を避けながら、有効なGPUメモリ容量と帯域幅を増やすシステムである「バディ圧縮」を提案している。また、より強力なシステムに匹敵するパフォーマンスを示す初期結果についても議論する。
著者:Esha Choukse、Michael Sullivan、Mike O’Connor、Mattan Erez、Jeff Pool、David Nellans、Steve Keckler
自動チューニングによるHPCアプリケーションの入出力パフォーマンスの最適化
とりわけI / Oミドルウェアとハードウェアの相互依存性が原因で、異なるプラットフォーム上の多様なアプリケーションに対して高品質のI / Oパフォーマンスを得ることは大きな課題となるだろう。これらの相互依存関係の最適化は、パラメータの無限の組み合わせによって難読化されている。本稿では、イリノイ大学とローレンスバークレー国立研究所の研究者が、I / Oパフォーマンスを最適化することができるオートチューニングソリューションを紹介し、いくつかのHPCプラットフォームにわたるその利点を示している。
著者:Babak Behzad、Surendra Byna、Prabhat、Marc Snir
 |
|
HPCアプリケーションのライフサイクル強化のためのフレームワークの開発
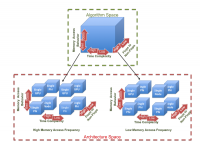
「エクサスケール」の時代が近づくにつれ、研究者たちは既存のアプリケーションやアルゴリズムを新しいアーキテクチャやプログラミング言語に移植するという困難な課題に直面している。クレムソン大学のKaran Sapraによる本稿では、アーキテクチャマッピングを最適化するためのアプリケーションと、異機種環境の最適化を支援するためのフレームワークを提供することによって、アプリケーションのライフサイクルを豊かにすることに焦点を当てている。
著者:Karan Sapra
大規模FPGAクラウドコンピューティングに対するソフトエラーの影響の評価
FPGAは、HPCアプリケーションを高速化するためによく使用されるが、「ソフトエラー」の影響を受けやすく、サイレントデータ破損やシステムの不安定化を招く可能性がある。NSFのスペース・ハイパフォーマンス・レジリアンㇳ・コンピューティングセンターの研究者によって書かれた本稿では、フォルトインジェクション実験を行うことにおいて発生する、一握りのFPGAアプリケーションの失敗率を調査し、特定のシステムにおいてのソフトエラーの検出と軽減の必要性を示唆している。
著者:Andrew M. Keller、Michael J. Wirthlin
 2019_03_12_NVMW_Rush |
|
Intel Optane DC Persistent Memory Moduleのパフォーマンス測定
カリフォルニア大学サンディエゴ校のコンピュータ科学者のチームによって書かれた本稿は、インテルの新しいOptane DC Persistent Memory Moduleの初めての包括的な評価について議論を行っている。そして著者らは、Optane DIMMが重要なストレージアプリケーションを17倍速くし、パフォーマンスを犠牲にすることなくメインメモリ容量を大幅に拡大できることを見出した。
著者:Joseph Izraelevitz、Jian Yang、Lu Zhang、Juno Kim、Xiao Liu、Amirsaman Memaripour、Yun Joon Soh、Zixuan Wang、Yi Xu、Subramanya R. Dulloor、Jishen Zhao、Steven Swanson。
来月のリストに含めるべき研究についてご要望があれば、oliver@taborcommunications.com宛にメールでご連絡ください。皆様のご意見をお待ちしております。
特別イベント

ISC 2026
6月 22 - 6月 26
International Conference for High Performance Computing, Networking, Storage & Analysis (SC26)
11月 15 - 11月 20
寄稿者
![]() 西克也
西克也
西克也はフェアチャイルド社、クレイ・リサーチ社、ベストシステムズ社など、30年以上に渡ってHPCに関する仕事に従事している。Hpcwire Japanの編集長として記事の作成と翻訳を行っている。
![]() 島田佳代子
島田佳代子
1999年~2007年まで英国在住。2001年よりスポーツ、旅、ビジネス、映画など幅広いジャンルで執筆活動を開始し、Hpcwire Japanでは主に日本のHPC業界が世界に誇る研究者、開発者の方々のインタビューを担当。
![]() 小柳義夫
小柳義夫
小柳義夫氏は40年以上に亘ってHPCに携わってきた研究者であり、日本のHPC業界における生き字引として有名。現在 高度情報科学技術研究機構に所属し、産業界のHPC推進にあたっている。
![]() 小西史一
小西史一
小西史一は、理化学研究所、東京工業大学においてHPCおよびバイオインフォマティクスに関する研究と教育に携わってきた研究者。2012年からフォトグラファーとしての活動を開始し、現在はIT技術・セキュリティのコンサルティング業務に携わっている。