
HPCの歩み50年記事一覧

スパコンリスト日本

記事寄稿について

Dojo登場:テスラ、モジュール型スパコンとD1チップのデザインを公開
Oliver Peckham

2ヶ月前、Tesla社は、「世界でおよそ5番目のスーパーコンピュータ」と称する巨大なGPUクラスタを公開したが、これはTesla社の真のスーパーコンピュータのムーンショットの前触れであった:長い間噂になっていたが、ほとんど詳細が明らかになっていない「Dojoシステム」だ。Tesla社の自動運転エンジニアリングディレクターであるMilan Kovacは、「当社はここ数年、ニューラルネットワークのトレーニング用コンピュータの規模を劇的に拡大してきました。」と述べている。「今日では、1万台のGPUに届くかどうかというところまで来ています。しかし、それだけでは十分ではありません。」
Tesla社のAI Dayイベントにおいて、構成するD1チップのデザインとともに公開された「Dojo」の登場である。
Dojoの夢
Tesla社の自動運転ハードウェア担当シニアディレクターであるGanesh Venkataramananは、「ニューラルネットワークのトレーニングには、容量だけでなくスピードも求められています。」と述べている。 数年前、TeslaのCEO兼共同創業者であるElon Muskは、Venkataramananのチームに “超高速 “トレーニングコンピュータの開発を依頼した。その目的は、最高のAIトレーニング性能を実現し、より大規模で複雑なニューラルネットモデルを可能にし、電力効率とコスト効率の両方を達成することだった。
Venkataramananは、「Dojoでは、非常に堅牢な演算素子を搭載した大規模なコンピュートプレーンに大容量のメモリを搭載し、非常に高い帯域幅と低レイテンシのファブリックで相互接続することを想定しました。私たちは、スタックの上から下までのすべてに着手し、これらのどのレベルでもすべてのボトルネックを取り除きたいと考えました。」と述べている。
D1チップとトレーニングタイル
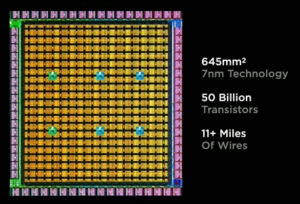 |
|
| Tesla社のD1チップ。画像提供:Tesla社 | |
前述の先駆けのクラスタでは、アクセラレータにNvidia社のA100 GPUが主に使用されていた。しかし、「Dojo」ではそうではない。「Dojo」は、ほぼすべてがTeslaのユニークなD1チップで構成されている。D1は、FP32、BFP16(別名bfloat16またはbrain浮動小数点)、そしてCFP8(”コンフィギュラブルFP8”)と呼ばれる新しいフォーマットをサポートしているとVenkataramananは言う。機械学習のワークロードに最適化されたD1(354個の “トレーニングノード “から構成されている)は、7nmプロセスで製造され、わずか645平方ミリメートルのサイズに500億個のトランジスタを搭載している。Venkataramananは、Teslaの社内エンジニアが完全に設計したこのチップについて、「ダークシリコンもレガシーサポートもありません。これは純粋な機械学習マシンです。このチップは、CPUレベルの柔軟性を備えたGPUレベルのコンピュートを備えています。」と述べている。
 |
|
| 25個のD1チップを搭載した統合型トレーニングタイル。画像提供:Tesla社 | |
Tesla社は、ハードウェア全体のモジュール性を重視している。D1は、横方向の各エッジに4TBpsのオフチップ帯域幅を備えており、4つのエッジすべてにコネクタが装備されているため、速度を犠牲にすることなく他のD1チップと接続して拡張することができる。
次のステップアップは、Teslaの「トレーニングタイル」だ。これは、D1チップを25個搭載した1立方フィートにも満たない大きさのくさびである。このトレーニングタイルは、D1チップと同様にモジュール化されており、電源と冷却はタイルの上部から行われ、タイルの4つの側面には最大の帯域幅(タイル外の帯域幅は合計36TB/s)に対応した高出力コネクタが装備されている。
「Dojo」
Venkataramananは、「ここまで来れば、当社のモジュール化がかなり進んでいることがお分かりいただけると思います。我々はただタイルを組み合わせただけです。タイルを組み合わせただけなんです!」 と言う。354個のトレーニングノードで1つのD1チップが構成され、25個のD1でトレーニングタイルが構成され、6個のトレーニングタイル(2×3)で “トレーニングマトリックス “と呼ばれるトレイが構成され、2個のトレイでキャビネットが構成され、さらに10個のキャビネットでVenkataramananが “ExaPOD “と呼ぶ、均一な帯域幅を持つ巨大な機械学習マシンが構成されている。(「Dojo」に何台のExaPODが搭載されるかは不明)
 |
| ExaPODの詳細。画像提供:Tesla社 |
1個のD1チップで22.6テラフロップスのFP32性能を提供し、1個のトレーニングタイルで565テラフロップス、12個のタイルを格納する1個のキャビネットで6.78ペタフロップスとなり、1台のExaPODだけで最大67.8 FP32ペタフロップスの理論性能を発揮することになる。(Tesla社は、BFP16とCFP8の性能を提供することを希望しており、その基準では、ExaPODは1.1エクサフロップスとなる。) Venkataramananによると、これらの性能はすべて、高性能なコンパイラによって利用可能になる。コンパイラは、人間が関与せずに自動的に動作し、研究者が開始する際の労力は最小限で済む。
「これこそが、”Dojo “が目指すものです。」とVenkataramananは語る。「最速のAIトレーニングコンピュータになるのです。」
しかし「Dojoは」まだ到着していない。実際、Venkataramananによると、機能的なトレーニング用タイルの1枚目が到着したのは前週のことだった。次はキャビネットを(もうすぐ)作るとのことだ。
「そして」とVenkataramananは続けた。「まだ終わっていません。Teslaでは、次世代の計画がすでに全部できています。」と、次の10倍の性能を見据えている。
さらに詳しく
特別イベント

寄稿者
![]() 西克也
西克也
西克也はフェアチャイルド社、クレイ・リサーチ社、ベストシステムズ社など、30年以上に渡ってHPCに関する仕事に従事している。Hpcwire Japanの編集長として記事の作成と翻訳を行っている。
![]() 島田佳代子
島田佳代子
1999年~2007年まで英国在住。2001年よりスポーツ、旅、ビジネス、映画など幅広いジャンルで執筆活動を開始し、Hpcwire Japanでは主に日本のHPC業界が世界に誇る研究者、開発者の方々のインタビューを担当。
![]() 小柳義夫
小柳義夫
小柳義夫氏は40年以上に亘ってHPCに携わってきた研究者であり、日本のHPC業界における生き字引として有名。現在 高度情報科学技術研究機構に所属し、産業界のHPC推進にあたっている。
![]() 小西史一
小西史一
小西史一は、理化学研究所、東京工業大学においてHPCおよびバイオインフォマティクスに関する研究と教育に携わってきた研究者。2012年からフォトグラファーとしての活動を開始し、現在はIT技術・セキュリティのコンサルティング業務に携わっている。