
HPCの歩み50年記事一覧

スパコンリスト日本

記事寄稿について

インテル、4/8ソケット用のCooper Lake Xeonを発表
Tiffany Trader

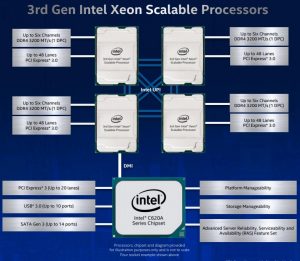
インテルは、データセンターで利用されるAIおよび解析ワークロードをターゲットとした4ソケットおよび8ソケット・サーバ向けの第3世代Scalable Xeonプロセッサ・ファミリ(コードネームはCooper Lake)を発表した。16~28コア、3.1GHzまでの基本クロック(ターボブーストで4.3GHzまで)、および6本までのメモリチャネルをサポートした合計11の新しいSKUが発表された。
インテルによると、Cooper Lakeはクラウド・データ分析の実行モデルで平均1.92倍の性能向上を提供し、標準的な5年前の(Haswell)プラットフォームに対して最大1.98倍のデータベース性能を提供する。SupermicroとLenovoは、新しいIntelプロセッサ用に最適化されたサーバを発表しているシステムメーカーである。
インテルによると、Cooper Lakeの発売により不揮発性メモリであるIntel Optane 200シリーズが採用され、前世代より平均25%増のメモリ帯域幅を提供しているという。Optane 100シリーズと同様に、Optane 200には128GB、256GB、512GBのモジュールが提供されており、マザーボード上の従来のDDR4 DIMMと並べて使用できる。1つのソケットには最大6つのモジュールが装着され、ソケットあたり最大3TBの不揮発性メモリと、ソケットあたり最大4.5TBの総メモリ容量が提供される。
 |
|
| プロセッサごとに 6 本の Intel UPI をサポート(最大 10.4GT/s) | |
インテルの14nm++プロセス上で製造されたCooper Lakeは、Intel Deep Learning Boost (DL Boost)技術に追加された新しいbfloat16サポートで、組み込みAIトレーニングの高速化を提供する最初のx86プロセッサである。インテルは、bfloat16を「今日のFP32フォーマットの半分のビットを使用するが、(もし可能なら)最小限のソフトウェア変更で同等のモデル精度を達成するコンパクトな数値フォーマット」として記述している。
これらの新しいAI能力を用いて、4ソケットCooper Lakeプラットフォームは、インテルのベンチマークにおいて、4ソケットCascade Lake基準プラットフォームに対して、1.93倍高速なAIトレーニング性能および1.87倍高速な画像分類AI推論性能を提供した。別の内部テストにおいてインテルは、自然言語処理のためのBERTスループットについて、Cascade Lakeよりも1.7倍高速なAIトレーニング性能を実証した。
TIRIAS Researchの主要アナリストKevin Krewellは、DL Boostとbfloat16がインテルにとって重要な技術であり、重要な競争優位性を提供していると考えている。「DL Boostとbfloat16によるAIの高速化は、問題に対する本当に革新的な解決策です。同じ作業負荷を達成するのに、より多くの性能を提供し、より多くのエネルギーを節約することができるのです。」とKrewellは述べている。この種のインストラクション・イノベーションを加えることで、インテルがAMDより一歩手前に留まることができる方法の1つである。AMDは、より多くのコアを同じ電力規模内に入れ、2ソケットおよびシングルソケットのパフォーマンスを向上させるという点で良い仕事をしているのですが、AMDはサーバ製品に機械学習技術を追加する際に、依然としてインテルに遅れをとっています。」と述べている。
インテルは、特に大規模クラウドサービスプロバイダの中で、4ソケットおよび8ソケット市場におけるDL Boostおよびbfloat16の需要を見出している。
「Facebookは、第3世代Xeonプロセッサのかれらのインフラストラクチャでの使用について話し合うのに最も声高でした。」とFacebookの5月の発表を参照して、新しいXeonサーバCPUが、そのリフレッシュされたOCP(Open Compute Platform)サーバの基礎になると述べた。「Alibaba、Tencent、およびBaiduも、この技術の強力な支持者です。」
BF16は、FP32と比較して精度を失うことなく、これらの顧客および他の顧客により高い性能を提供する。DL Boost機能セット(INT8とFP32も含む)にBF16を追加することで、メインストリームサーバCPUに組み込まれた高度なAI機能を顧客に提供し続けることができます。」と述べた。
また、新プロセッサは拡張されたIntel Select Speed技術を導入する。Intel Select Speed テクノロジは、第2 世代スケーラブルXeon プロセッサで起動され、特定のコアの基本間隔周波数をユーザが制御できるようにする。これにより、優先度の高いワークロードのパフォーマンスを最大限に引き出すことができるのだ。「最善のレスポンスを保証し、りの計算資源を超効率的に利用するために、作業負荷の最も重要な部分をあなたの最も重要なトラフィックに優先順位を付けることを可能にする質の高いサービスタイプの機能と考えることができます。」と、インテルの法人副社長であり、XeonおよびMemory GroupのLisa Spelmanは述べている。
Cooper Lake SKUは、サポートされる機能に基づいて区別され、すべてのSKUがすべての機能をサポートするわけではない。SKUスタックの最上部には、Intel Xeon Platinum 8380Hおよび8380HLプロセッサがあり、28コア、2.9GHzベース周波数(ブースト付き4.3GHzまで)、250ワットTDP内の38.5MBのキャッシュメモリがあり、4または8ソケットプラットフォームをサポートする。−L指定は、「大容量メモリ」を表し、Optane不揮発性メモリとDRAMの組合せで、ソケット当たり4.5TBまでのメモリをサポートする。Platinum 8380Hは、Intel DL Boost for AIトレーニングをサポートする。18コアIntel Xeon Platinum 8354Hプロセッサは、学習と推論の両方においてIntel DL Boostをサポートする唯一のプロセッサである。Intel は、SKU テーブルとともに、各 SKU でサポートされている機能を示すリファレンスガイドを提供している。
もともと、Cooper Lakeは、マルチチップ・モジュール・パッケージ内のソケット付き56コア・パーツだけでなく、2ソケット・サーバも含めて、全範囲のデータセンタ・プラットフォーム用に意図されていたが、インテルはCascade Lake のリフレッシュと次のIce LakeサーバCPUとの間の暫定的なニーズを満たすために、製品ファミリーを縮小している。
「Cascade Lakeのリフレッシュで行なった仕事が、われわれが解決し、Cooper Lakeで「トップからボトムまで」対応しようとしていた一連の市場ニーズに応えるのに役立ったと感じています。4ソケットと8ソケット、そして第2世代のOptane不揮発性メモリの必要性が、より急を要する、あるいは広く普及する機会でした。Cascade Lakeのリフレッシュが、どのように集まるかを見ると、Cascade Lakeのリフレッシュが、性能とアップグレードに非常に素早い道筋を与えたと感じています。Cooper Lakeは、4ソケットと8ソケットに対応し、次に、より主流の2ソケットのためのIce Lakeに対応します。
それは正しいフィット感のように感じ、私たちにその混乱のいくらかを取り除く機会を与えてくれました。」と述べた。
 |
| 4/8ソケットCooper Lakeと1/2ソケットIce Lakeは、ともに「第3世代Intel Xeon Scalable」と名付けられた |
Spelmanは、インテルのCooper Lakeの10nm後継であるIce Lakeが今年後半に発売予定であると述べた。
またインテルは、Ice Lakeの後に登場する次世代の10nmサーバーチップ、Sapphire Rapidsが最近パワーオンを終え、Intelが学習と推論性能をさらに押し上げるだろうと語る次世代AI加速機能「Intel Advanced Matrix Extensions」または「AMX」などの機能をテストしていると報告した。Spelmanによると、AMXの仕様は今月公開され、開発者がAMXの準備と基盤となるソフトウェアの最適化を開始できるようになるという。
第3世代のIntel Xeon ScalableプロセッサとIntel Optane不揮発性メモリ200シリーズモジュールは、現在 顧客に出荷されている。Facebook、Alibaba、Baidu、Tencentは、CPUを採用する計画を発表した。OEMシステムは2020年後半に出荷が予定されており、SupermicroとLenovoは新しいXeonプロセッサとOptane 200シリーズメモリモジュールを活用したサーバのアップグレードを発表した。
特別イベント

寄稿者
![]() 西克也
西克也
西克也はフェアチャイルド社、クレイ・リサーチ社、ベストシステムズ社など、30年以上に渡ってHPCに関する仕事に従事している。Hpcwire Japanの編集長として記事の作成と翻訳を行っている。
![]() 島田佳代子
島田佳代子
1999年~2007年まで英国在住。2001年よりスポーツ、旅、ビジネス、映画など幅広いジャンルで執筆活動を開始し、Hpcwire Japanでは主に日本のHPC業界が世界に誇る研究者、開発者の方々のインタビューを担当。
![]() 小柳義夫
小柳義夫
小柳義夫氏は40年以上に亘ってHPCに携わってきた研究者であり、日本のHPC業界における生き字引として有名。現在 高度情報科学技術研究機構に所属し、産業界のHPC推進にあたっている。
![]() 小西史一
小西史一
小西史一は、理化学研究所、東京工業大学においてHPCおよびバイオインフォマティクスに関する研究と教育に携わってきた研究者。2012年からフォトグラファーとしての活動を開始し、現在はIT技術・セキュリティのコンサルティング業務に携わっている。