
HPCの歩み50年記事一覧

スパコンリスト日本

記事寄稿について

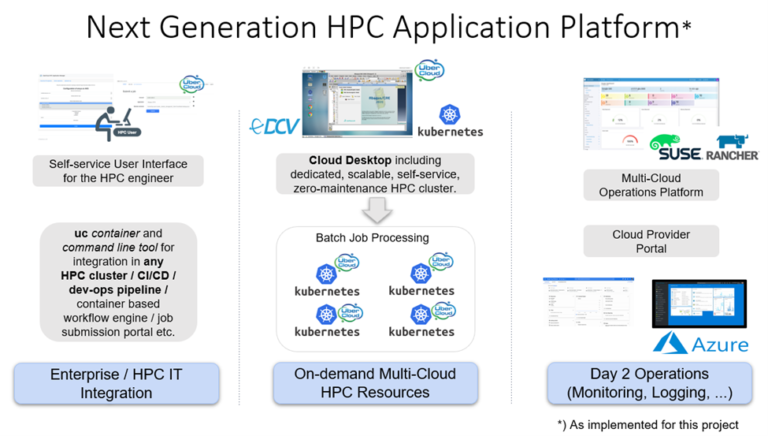
マルチクラウド環境におけるKubernetesベースのHPCクラスタの展開
Daniel Gruber、Burak Yenier、Wolfgang Gentzsch (UberCloud社)

大企業においてクラウドコンピューティングが事実上の導入モデルとなったことで、1つの企業内で複数のクラウドを利用することが一般的になっている。特定のクラウド・プロバイダを選択する際には、提供されているクラウド・サービスの可用性と機能に基づいて決定されることが多い。また、企業内のさまざまなグループの要求により、異なるクラウド・スタックを利用する断片的な利用パターンが生まれている。
この記事は、Kubernetes HPCに関する連載記事(Part-1, Part-2)のPart-3であり、要求の高いエンジニアリングアプリケーション向けに提供されているクラウド事業者のハイパフォーマンスコンピューティング(HPC)と、その顧客のマルチクラウド導入の潜在的なニーズについて説明している。
Kubernetesは、どのクラウドを使用するかに関わらず、企業のワークロードの共通のワークロード管理となっている。以前の2つの記事では、その有用性をHPCの分野でも評価した。この記事では、マルチクラウドHPCにおけるKubernetesの有用性を示すために、ケーススタディを紹介する。これは、SUSE Rancher Kubernetes管理を用いたAzure/Googleマルチクラウド環境で、患者固有のデータ生成と機械学習を用いて心臓弁の漏れをシミュレーションするもので、顧客と協力して3,000件のAbaqusシミュレーションをそれぞれのKubernetesクラスタで実行した。
 |
クラウドプロバイダが提供するカスタマイズされたHPCソリューションは、マルチクラウドの導入を妨げることが多い
AWS、Azure、および Google Cloud Platform には、HPC クラスタを実行するための使いやすいソリューションが用意されている。しかし残念なことに、クラウド事業者が提供するHPCソリューションには、マルチクラウド化のためのソリューションパターンがない。カスタマイズが必要なインフラ維持ソリューションは、クラウド事業者の自社環境内でしか再利用できないのだ。同様のテスト環境やフェイルオーバー環境を別のクラウドプロバイダで構築するには、全く異なるテクノロジースタックを学習し、適応させ、維持する必要がある。これにより、ライセンス管理、データステージング、ワークロード管理などの既存の課題の複雑性が大幅に増加する。そのため、クラウド事業者のベストプラクティスに従うことは、HPCワークロード管理を孤立した問題として扱うことになる。従来のHPCワークロードマネージャの遺産により、ジョブのスケジューリング、分配、管理の問題は、通常、単一のネットワーク内でのみ解決される。UberCloudの顧客に見られるのは、HPCワークロードをリージョンやクラウドプロバイダーのサブスクリプション、さらには単一のクラウドの境界線を越えて展開・管理する必要性である。
Kubernetesは、共通のHPCワークロード管理レイヤーとなり得るのだろうか?
エンタープライズワークロード向けのKubernetesの台頭により、すべてのクラウドプロバイダーは、マネージドKubernetesソリューションスタックに大規模な投資を行っている。2年以上前、我々がHPCコンテナ用の最初のKubernetesクラスタをデプロイし始めたとき、多くの問題に遭遇したが、今では解決されてきた(大きなコンテナイメージサイズのサポート不足、ベアVMに比べて長いインフラ展開時間、データセンター内でのVMのコロケーション不足)。今日では、クラウド・プロバイダーのロードマップには、すぐに使えるInfiniBandのサポートのような重要な機能も含まれているが、これは我々自身のツールで対応しなければならない。
すべてのクラウドプロバイダーにKubernetesクラスタを割り当てることができるという事実を考えると、それはマルチクラウドの実現にどのように役立つのだろうか。まず第一に、どこでも同じテクノロジースタックを扱うことができる。細かい違いはあるが、ワークロード管理層、つまりKubernetes APIサーバは、ワークロードのデプロイメント命令の再利用を大幅に簡素化する。当社のHPCアプリケーションコンテナのおかげで、どのクラウドでも全く同じ特性のHPC環境を提供することができるようになる。Kubernetesは、必要なワークロード管理の抽象化を提供する。Kubernetes環境でサポートされている巨大でオープンなソフトウェア・エコシステムにより、クラウド・プロバイダーに依存せずに動作し、サポートされるカスタマイズされた機能性を導入することが、かつてないほど容易になってくる。マルチクラウドのKubernetes管理プラットフォームは、異なる地域やクラウドに分散したHPCワークロードに対しても、モニタリング、ロギング、ワークロード管理を一枚ガラスのように提供する。
同じソフトウェアスタックを異なるクラウドで利用できるかどうかは、一つの問題に過ぎない。ライセンス管理についてはどうだろうか?シミュレーションの入力データはどこから来るのか、結果はどこに保存するのか。長期的な保存についてはどうだろう。クラウド間の通信はどのように保護されるのか。コストはどのように管理されるのか?認証と認可はどのように実装されるのだろうか?これらのテーマについては、今後の記事で紹介する予定だ。
3,000個のマルチフィジックス生体心臓シミュレーションを3,000台のKubernetesクラスタで機械学習を用いてマルチクラウド環境で行う
最近では、カリフォルニア大学サンディエゴ校のスピンオフ企業である3DT Holdings社から、Azure/Googleのマルチクラウド環境で、SUSE RancherのKubernetes管理と当社のエンジニアリング・シミュレーション・プラットフォームを用いて、患者固有のデータ生成と機械学習による心臓弁漏出のシミュレーションを行うという課題に挑戦した。エンドユーザである3DTホールディングスのYaghoub Dabiri、UCSFのJulius Guccione、UCSDのGhassan Kassabをサポートし、3,000回のシミュレーションを実行し、人間の心臓内部の血流、ストレス、体積、圧力を正確にシミュレートした。その目的は、僧帽弁逆流(MR)を抑えるために心臓の僧帽弁に装着するMitraClipと呼ばれる部品の最適な位置を見つけることであった。MitraClipは小さな金属製のクリップで、医師がカテーテルを使って僧帽弁を修復する手術を可能にし、開胸手術に代わる低侵襲手術を実現する。この3,000回のシミュレーションにより、数時間から数日ではなく、ほぼリアルタイム(数秒以内)で僧帽弁におけるMitraClipの最適な位置を予測するMLアルゴリズムのセットを学習するための十分なシミュレーション結果を収集した。
3DTホールディングスの予算内に収めるため、プリエンプティブル(スポット)モードで割り当てられるGoogle Cloud PlatformのC2 HPC VMを使用した。しかし、ユーザに代わって環境を管理・監視する必要があったため、必要なアーキテクチャコンポーネントの一部は、当社のAzureアカウント内に実装した。そのため、シミュレーションを中断させるリスクを減らすために、毎回自動的にゼロから起動されるGoogle Kubernetes Engineクラスタで各シミュレーションを実行することにした。ライセンスサーバやSUSEのRancher(監視用)など、残りのインフラはAzure上で運用している。どちらの環境もファイアウォールルールで保護されており、コンポーネント間を流れるトラフィックのみを許可している。ある特別な GKE クラスタでは,安価なインスタンスタイプと GPU を使用して Abaqus コンテナを実行し,Abaqus がインストールされた Linux デスクトップをリモート(NI-SP のマシンイメージをAWSのDCV を介してアクセス)で提供した。このクラスタは、プロジェクト全体を通して、エンジニアのエントリーポイントとして、入力データの準備や出力結果の監督を行なった。
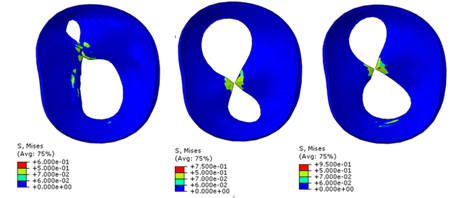 |
| MitraClipインプラントの配置を変えた場合の僧帽弁へのストレス(出典:UberCloud社) |
マネージドKubernetesのデプロイには、若干のオーバーヘッド(管理費、コンピュートノード上で実行されるデーモンやプロセスの増加など)が発生するが、C2 preemptible CPUの価格を80%削減できたこと、単一のコマンドでデプロイされる一貫したアプリケーションスタックを使用できたこと、SUSE Rancherとの統合によりKubernetesのエコシステム全体との互換性を利用できたことなどの利点が、それらをはるかに上回った。コストや先取りによるジョブの失敗を最小限に抑えつつ、同時にクラウドのリソースやライセンスを最大限に活用して最大のスループットを得ることができた。その結果、3,000回のシミュレーションの総コストは2万ドル以下に抑えることが可能となった。
謝辞
素晴らしいサポートを提供してくれたMicrosoft AzureチームとGoogle GCPチーム、そしてAbaqus、Rancher、DCVのソフトウェアライセンスを惜しみなく提供してくれたソフトウェアプロバイダのDassault Systèmes、SUSE、NI-SPに感謝いたします。
著者について
Daniel Gruber、Burak Yenier、Wolfgang Gentzschの3名はUberCloud社に所属しており、2013年にHPCコンテナ技術とコンテナ化されたエンジニアリングアプリケーションの開発を目的として設立された。
特別イベント

ISC 2026
6月 22 - 6月 26
International Conference for High Performance Computing, Networking, Storage & Analysis (SC26)
11月 15 - 11月 20
寄稿者
![]() 西克也
西克也
西克也はフェアチャイルド社、クレイ・リサーチ社、ベストシステムズ社など、30年以上に渡ってHPCに関する仕事に従事している。Hpcwire Japanの編集長として記事の作成と翻訳を行っている。
![]() 島田佳代子
島田佳代子
1999年~2007年まで英国在住。2001年よりスポーツ、旅、ビジネス、映画など幅広いジャンルで執筆活動を開始し、Hpcwire Japanでは主に日本のHPC業界が世界に誇る研究者、開発者の方々のインタビューを担当。
![]() 小柳義夫
小柳義夫
小柳義夫氏は40年以上に亘ってHPCに携わってきた研究者であり、日本のHPC業界における生き字引として有名。現在 高度情報科学技術研究機構に所属し、産業界のHPC推進にあたっている。
![]() 小西史一
小西史一
小西史一は、理化学研究所、東京工業大学においてHPCおよびバイオインフォマティクスに関する研究と教育に携わってきた研究者。2012年からフォトグラファーとしての活動を開始し、現在はIT技術・セキュリティのコンサルティング業務に携わっている。