
HPCの歩み50年記事一覧

スパコンリスト日本

記事寄稿について

Nvidia、Hopper H100 GPU、新型DGX、Grace メガチップを発表
Tiffany Trader

データセンターの覇権争いはますます熱を帯びてきている。先日、Nvidiaは春のGTCイベントを新しいシリコン、新しいソフトウェア、そして新しいスーパーコンピュータで幕を開けた。CEOのJensen Huangは、3Dコラボレーションおよびシミュレーション・プラットフォーム「Nvidia Omniverse」の仮想環境から、新しいHopper GPUアーキテクチャと、HPCおよびAIワークロード用のデータセンター規模のシステムを強化するH100 GPUを紹介した。
Nvidia初のHopperベースの製品であるH100 GPUは、TSMCの4Nプロセスで製造され、先行世代の7nm A100 GPUよりも68%多い、なんと800億個のトランジスタを活用している。H100は、PCIe Gen5をサポートする最初のGPUであり、HBM3を利用して3TB/秒のメモリ帯域幅を可能にした最初のGPUでもある。
コンピュータ科学者で米海軍少将のGrace Hopperにちなんで名付けられたこの新しいGPU(SXMメザニンフォームファクタ)は、30テラフロップスの標準IEEE FP64ピーク性能、60テラフロップスのFP64テンソルコアピーク性能、および60テラフロップスのFP32ピーク性能を提供する。Nvidiaによれば、Hopperで導入された新しい数値フォーマットであるFP8テンソルコアは、最大4,000テラフロップスの理論上のAI性能を実現するとのことである。スペック情報および世代間比較は以下を参照。
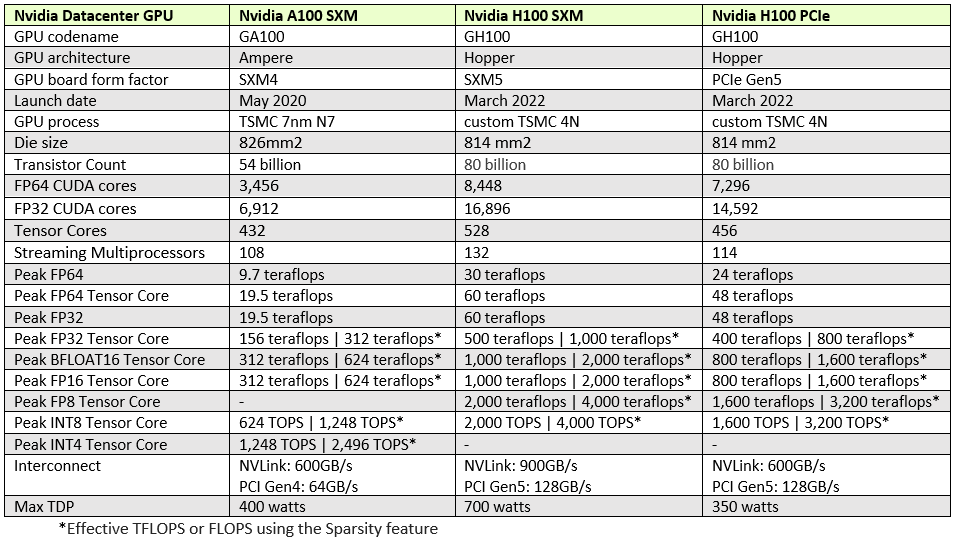 |
Hopperは、自然言語処理に広く使用されているトランスフォーマーモデル用のビルトインハードウェアアクセラレーションを導入している。Nvidiaによると、Hopperトランスフォーマーエンジンは、8ビットと16ビットの計算を動的に選択し、トランスフォーマーネットワークのレイヤーの精度をインテリジェントに管理し、精度を損なうことなく高速化を実現するとのことだ。
「Hopper H100は、これまでで最大の世代的飛躍です。A100の9倍のアットスケールトレーニング性能と、30倍の大規模言語モデル推論スループットを実現します」と、Huangは基調講演で述べている。
Hopperの第2世代マルチインスタンスGPU(MIG)技術は、1つのGPUを7つの小さな完全に分離されたインスタンスに分割することを可能にする。Nvidiaによれば、Hopperはまた、経路最適化やゲノムなど多くのアルゴリズムで使用できる新しいDPX命令を導入し、ダイナミックプログラミングを前世代のGPUに比べて7倍、CPUに比べて40倍高速化する。
Hopperは、新しい第4世代のNvidia NVLinkテクノロジーを搭載している。このテクノロジーは、新しいNVLinkスイッチという形で初めてサーバの外部にまで拡張された。このスイッチシステムは、最大256個のH100 GPU(32 ノードDGX Pods)を、Nvidia HDR Quantum InfiniBandを使用する前世代と比較して9倍高い帯域幅で接続する。
 |
|
| Nvidia H100 CNXコンバージドアクセラレータ 出典:Nvidia |
|
Hopperは、DGXおよびHGXシステム内で使用されるSXMフォームファクタに加えて、H100 PCIeフォームファクタのGPUも提供され、これらはNVLinkブリッジを介して2つリンクさせることが可能だ。Hopperはさらに、H100とConnectX-7 SmartNICを組み合わせた新しいコンバージドアクセラレータ「H100 CNX」として提供され、どちらもPCIe Gen 5をネイティブで実行する。H100 CNXは、CPUへのPCIe接続により、メインストリームサーバに導入することができる。 Nvidiaの製品管理・マーケティング担当シニアディレクターであるParesh Kharyaは、メディアやアナリスト向けに開催した事前説明会で、「GPUを4基搭載したメインストリームサーバにおいて、H100 CNXはGPUへの帯域を4倍に高め、同時にCPUを解放してアプリケーションの他の部分の処理に充てます」と述べた。
NvidiaのDGXシステム担当副社長兼ジェネラルマネージャであるCharlie Boyleは、もう一つの利点として、サーバ製品が市場に出る前にPCIe Gen 5の利点にアクセスできることを強調した。「現在購入できるサーバはまだ PCIe Gen 4 ですが、H100 CNX カードを組み合わせることで、CPU を介さずにネットワークから GPU に直接フル Gen 5 ネットワーキングを実行できる利点が得られます。CNXカードが利用可能になれば、顧客はHopperにアップグレードして、メーカーがGen 5に到達するのを待ってインフラを実際に変更する必要なく、フルPCIe Gen 5システムの利点のほとんどを得ることができます」と、Boyleは述べている。
 |
| Nvidia Hopper H100ファミリ 出典:Nvidia |
H100の発売と同時に、NvidiaはDGXシステムアーキテクチャを刷新する。同社の第4世代DGXシステム「DGX H100」は、8個のH100 GPUを搭載し、合わせて640GBのHBM3、3.6TB/sのバイセクション帯域幅を実現する。第4世代のNVLinkファブリックを搭載したNVSwitchがGPUを接続し、前世代の1.5倍となる900GB/sの接続性を提供する。
外部NVLinkスイッチは、最大32台のDGX H100ノードをNvidia DGX Podスーパーコンピュータにネットワーク化し、新しいDP8テンソルコアユニットを活用した最大1エクサフロップスのAI性能と、最大7.68ピーク・ペタフロップスの標準IEEE FP64性能を提供する
DGX Podsは32ノード単位で拡張でき、さらに大規模なシステムを構築することができる。Nvidiaは、今年後半に運用を開始する予定のEosと名付けられた別の新しい社内スーパーコンピュータで、DGX H100の技術を紹介している。Eosは、表向きはギリシャ神話の暁の女神にちなんで名付けられたもので、576台のDGX H100システム、500台のQuantum-2 InfiniBandシステム、360台のNVLinkスイッチで構成されている。合計 4608 個の GPU を搭載する Eos は、FP8 テンソルコアのピーク性能で 18エクサフロップス、FP16 テンソルコアのピーク性能で 9エクサフロップス、標準 IEEE FP64 のピーク性能で 138 ペタフロップスを実現する。NvidiaのFP64テンソルコア処理により、HPCのピーク性能は275ペタフロップスにまで押し上げられる。Eosに関するその他の報道はこちらを参照。
DGX H100の予測最大消費電力は10.2kWで、DGX A100の約1.6倍だ。これは、H100の熱外皮が高く、A100の400ワットに対し、最大700ワットを消費することに起因する。この余分な熱を収容するために、NvidiaはDGXを2Uの高さにしたが、この設計変更により、空冷式のボックスが引き続き使用できるようになった。
これまでのNvidia GPUと同様に、H100 SXMは、4GPUおよび8GPU構成のHGX H100サーバボードでも提供され、クラウドプロバイダやシステムメーカーが独自のH100システムやクラスタを構築して提供できるようにする予定だ。
 |
| Nvidia H100 HGXベースボード 出典:Nvidia |
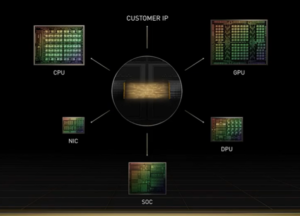
基調講演の中で、HuangはNvidiaの次期CPUであるGrace Armについてもう少し詳しく説明し、2種類のフォームファクタの「Grace Superchips」を発表した。昨年明らかにされたCPU+GPUの複合SoCは、「Grace Hopper Superchip」という名称が正式に確定した。巨大スケールのAIやHPC向けに設計されたこのプラットフォームは、GPUに600GBのメモリを搭載し、NVLinkチップ・ツー・チップ(C2C)と呼ばれる毎秒900ギガバイトのコヒーレントインターコネクトを装備している。
 |
CPUの半分は、Grace Hopper Superchipの基盤となっている。このデータセンター向けディスクリートCPUは、ArmベースのCPUチップ2個を毎秒900ギガバイトのNVLink C2Cインタフェースでコヒーレントに接続し、毎秒1テラバイトのメモリバンド幅を持つシングルソケットの144コアCPUを構成している。Grace CPU Superchipは、SPECrate2017_int_baseベンチマークで740の予測性能を発揮し、Nvidiaは、現在DGX A100とともに出荷されている2つのAMD CPUの性能を1.5倍向上させるとしている。Nvidiaはさらに、Grace CPU Superchipが “従来のサーバ “の2倍のワットあたりの性能を発揮すると見積もっている。Grace Hopper SuperchipとGrace CPU Superchipは、いずれも2023年前半に登場する予定だ。
 |
「Grace HopperとGrace Superchipを実現するのは、超省エネ、低レイテンシ、高速のメモリコヒーレントNVLink C2Cリンクです」とHuangは述べた。「ダイからダイへ、チップからチップへ、システムからシステムへとスケールアップするNVLinkにより、GraceとHopperを構成して、ワークロードの大きな多様性に対応し、最大で2つのGrace CPUと8つのHopper GPUで(システムを)構築できます。」
 |
|
Nvidiaは、NVLink C2Cをカスタムシリコン統合のために開放することを発表した。「顧客は、我々がGrace SuperchipやGrace Hopper Superchipを作ったように、NvidiaとSuperchipを統合して作ることができるようになります」とKharyaは述べた。「このダイ間およびチップ間のリンクは、将来のNvidia GPU、DPU、CPUで利用可能となり、新しいクラスのカスタムチップやシステムを実現することができます。高密度実装により、Nvidia C2CはNvidiaチップのPCIe Gen 5 PHYと比較して、25倍のエネルギー効率と90倍の面積効率を実現します」と述べている。
また、Nvidiaは、今月初めに開始された開発中のUniversal Chiplet Interconnect Express(UCIe)規格をサポートすることを発表した。顧客は、Nvidiaのチップに接続するために、チップとシステムレベルの統合を選択することができるようになる。「カスタム統合の場合、顧客はUCIeを好きなように使えるし、NVLink C2Cも使えます」とKharyaは言う。
Nvidiaによれば、DGXシステムとH100 GPUは、今年の第3四半期に出荷が開始される予定だ。DGXの価格は後日発表される予定だ。
Nvidiaは、新しいH100 GPUをサポートするために、さまざまなパートナーが列をなしていると指摘した。Alibaba Cloud、Amazon Web Services、Baidu AI Cloud、Google Cloud、Microsoft Azure、Oracle Cloud、Tencent Cloudから計画的なインスタンスが進行中である。一方、H100プラットフォームの構築または統合を予定しているシステム企業のリストには、Atos、BOXX Technologies、Cisco、Dell Technologies、富士通、Gigabyte、H3C、HPE、Inspur、Lenovo、Nettrix、Supermicroが含まれている。
特別イベント

寄稿者
![]() 西克也
西克也
西克也はフェアチャイルド社、クレイ・リサーチ社、ベストシステムズ社など、30年以上に渡ってHPCに関する仕事に従事している。Hpcwire Japanの編集長として記事の作成と翻訳を行っている。
![]() 島田佳代子
島田佳代子
1999年~2007年まで英国在住。2001年よりスポーツ、旅、ビジネス、映画など幅広いジャンルで執筆活動を開始し、Hpcwire Japanでは主に日本のHPC業界が世界に誇る研究者、開発者の方々のインタビューを担当。
![]() 小柳義夫
小柳義夫
小柳義夫氏は40年以上に亘ってHPCに携わってきた研究者であり、日本のHPC業界における生き字引として有名。現在 高度情報科学技術研究機構に所属し、産業界のHPC推進にあたっている。
![]() 小西史一
小西史一
小西史一は、理化学研究所、東京工業大学においてHPCおよびバイオインフォマティクスに関する研究と教育に携わってきた研究者。2012年からフォトグラファーとしての活動を開始し、現在はIT技術・セキュリティのコンサルティング業務に携わっている。