
HPCの歩み50年記事一覧

スパコンリスト日本

記事寄稿について

インテル・ディスクリート・ハイパフォーマンスGPUの登場に備える
Hartwig Anzt

このゲスト投稿では、Hartwig Anztが、DPC++プログラミング環境を使用して、スパース線形代数数学ライブラリをインテルGPUに移植する作業についてまとめています。疎な線形代数機能の初期のベンチマークをスパース線形代数機能の初期のベンチマークについても紹介しています。
インテルのGPUが来る。米国エクサスケール・コンピューティング・プロジェクトの2番目のエクサスケール・システムであるAuroraスーパーコンピュータにおいて、インテルのGPUがどのような役割を果たすかについては議論があるかもしれないが、インテルがハイパフォーマンス・コンピューティングのためのディスクリートGPUの開発に取り組んでいることは確かだ。また、性能特性や技術的実現についての予測は推測の域を出ないが、ソフトウェア・エコシステムについての計画はかなり成熟している。
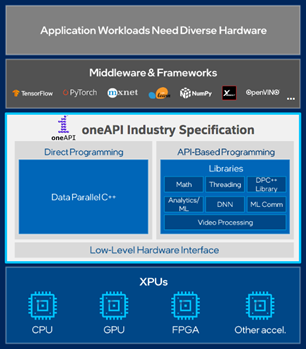
インテルは、Codeplay、HPE、その他の業界機関、およびアカデミアと協力して、「業界を超えた、オープンな標準ベースの統一プログラミングモデルで、アクセラレータ・アーキテクチャ間で共通の開発者体験を提供する」oneAPIを策定した。このSYCLベースのプログラミングモデルは、アプリケーションがインテルのGPUの演算能力を活用するための主要な手段となることが期待されている。米国のエクサスケール・コンピューティング・プロジェクトにおけるインテル・アーキテクチャーの重要性を念頭に置き、インテル・GPUアーキテクチャ用の高性能数学ライブラリを準備するために必要な開発者の取り組みと、oneAPIエコシステムの成熟度について、プレプリントで報告している。このエコシステムには、マルチコア・プロセッサやGPU用のコードをコンパイルする準備が整ったDPC++コンパイラだけでなく、インテルが開発した数学機能、ビデオ処理、分析・機械学習、ディープ・ニューラル・ネットワークなどのライブラリが多数含まれている(図1参照)。その目的は、アプリケーションの専門家に生産性の高いツールボックスを提供し、開発や性能チューニングを容易にすることだ。
 |
|
| 図1:oneAPIのエコシステム。出典は以下の通り。インテル株式会社 | |
インテルが提供するDPC++ Compatibility Tool(DPCT)は、CUDAコードをDPC++に変換するための便利なツールであるが、主にoneAPIエコシステムへの完全な移行を目的とした、依存関係の少ない中規模のライブラリ向けに設計されていると、我々のレポートでは説明している。E4Sソフトウェアスタックの一部であるECP製品として開発しているGinkgoライブラリのように、プラットフォームの移植性のためにハードウェア固有のバックエンドに依存しているアプリケーションの場合、DPC++ Portability Toolを使用するには、他のアーキテクチャのサポートを無効にすることなく動作するバックエンドを生成するために、ファイルの前処理と後処理の両方が必要になってくる。
「バックエンドが動くということは、エントリーレベルに過ぎません。高性能なアプリケーションでは、ハードウェア固有の限界まで性能を引き上げるために、大幅な最適化作業が必要になります」
カスタマイズされた回避策を用いることで、DPCTは移植作業を大幅に軽減することができる。我々は、2週間でGinkgo用のDPC++バックエンドを開発することができた。しかし、バックエンドが動くということはエントリーレベルに過ぎない。高性能なアプリケーションでは、ハードウェア固有の限界まで性能を高めるために、大幅な最適化作業が必要になる。また、この段階では、oneAPIのエコシステムがまだ開発中であることがわかる。協調グループのような基本的な機能はまだ欠けており、また、インテルのオープンソースのoneMKL数学ライブラリは、これまで、CPUに特化した模範的なインテルMathカーネルライブラリ(MKL)のカーネル・ズーをカバーするように徐々に拡張されているに過ぎぎない。完全な機能を実現するためには、手作りのソリューションが必要である。その後は?変換されたCUDAカーネルは、インテルのGPU上で良いパフォーマンスを発揮するだろうか?明白な理由から、オリジナルのCUDAカーネルが、スーパーコンピュータSummitに搭載されたNvidia V100 GPUで達成した性能と、Auroraシステムに予定されているIntel GPUのプロトタイプを比較することは無意味だ。そこで、絶対的な性能ではなく、アーキテクチャ固有の制限に対する相対的な性能を見ることにした。図2では、Nvidia V100 GPU(左)とIntel Gen12LP GPU(右)のハードウェア仕様に対するGinkgoのスパース行列ベクトル(SpMV)カーネルの性能を可視化している。
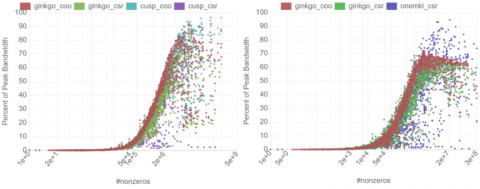 |
| 図2:Nvidia V100 GPU(左)とIntel DevCloudで利用可能なIntel Gen12LP GPU(右)におけるハードウェア固有の制限に対するスパース行列演算のパフォーマンス。Intel GPU上で動作するGinkgoカーネルは、DPCT変換されたCUDAカーネルであり、追加のアーキテクチャ固有の最適化を適用していません([1]参照)。 |
これらのグラフでは、アーキテクチャの特性だけでなく、ベンダーが最適化したカーネルと比較するために、ベンダー・ライブラリで提供されているSpMVカーネルの性能も示している。このグラフから、DPCTによるコード変換やアーキテクチャの変更によって、カーネルの性能比が影響を受けないわけではないことがわかる。しかし、DPCTによって生成されたカーネルは、Intel GPU用のアーキテクチャ固有のカーネル最適化を適用しなくても、ベンダーの機能に対して競争力を維持し、理論ピークのかなりの部分を達成している。
エコシステムの初期段階での未熟さにもかかわらず、この取り組みに将来性があると思わせるのは、インテルのコミュニティへの参加である。インテルは、oneAPIの取り組みにおいてオープンなコミュニケーション戦略を実施しており、すでに早い段階で科学者に接触し、コミュニティからの提言を歓迎し、最も早い段階でバグを修正し、oneAPIライブラリにコミュニティによるコードの貢献を認めてオープンソース化し、Intel DevCloudでアーリーアダプターがインテルGPU上でコードを実行する感覚をすでに得ることができるプラットフォームを提供するなど、多くのことを行っている。
[1] Yu-Hsiang M. Tsai, Terry Cojean, and Hartwig Anzt: Porting a sparse linear algebra math library to Intel GPU, https://arxiv.org/abs/2103.10116
著者プロフィール – Hartwig Anzt
Hartwig Anztは、カールスルーエ工科大学(KIT)のSteinbuch Centre for ComputingのHelmholtz-Young-Investigatorグループのリーダーであり、テネシー大学のJack Dongarra’s Innovative Computing Labのリサーチサイエンティストでもある。2012年にカールスルーエ工科大学で数学の博士号を取得している。Hartwig Anztは、米国のエクサスケール・コンピューティング・プロジェクト(ECP)の一員として、研究室横断の多精度フォーカス・エフォートをリードしている。また、次期EuroHPCプロジェクトであるMICROCARDの数値ソルバーを担当している。Hartwig Anztは、高品質のソフトウェア開発において長年の実績がある。MAGMA-sparseオープンソース・ソフトウェア・パッケージの作者であり、Ginkgo数値線形代数ライブラリの開発者でもある。
特別イベント

ISC 2026
6月 22 - 6月 26
International Conference for High Performance Computing, Networking, Storage & Analysis (SC26)
11月 15 - 11月 20
寄稿者
![]() 西克也
西克也
西克也はフェアチャイルド社、クレイ・リサーチ社、ベストシステムズ社など、30年以上に渡ってHPCに関する仕事に従事している。Hpcwire Japanの編集長として記事の作成と翻訳を行っている。
![]() 島田佳代子
島田佳代子
1999年~2007年まで英国在住。2001年よりスポーツ、旅、ビジネス、映画など幅広いジャンルで執筆活動を開始し、Hpcwire Japanでは主に日本のHPC業界が世界に誇る研究者、開発者の方々のインタビューを担当。
![]() 小柳義夫
小柳義夫
小柳義夫氏は40年以上に亘ってHPCに携わってきた研究者であり、日本のHPC業界における生き字引として有名。現在 高度情報科学技術研究機構に所属し、産業界のHPC推進にあたっている。
![]() 小西史一
小西史一
小西史一は、理化学研究所、東京工業大学においてHPCおよびバイオインフォマティクスに関する研究と教育に携わってきた研究者。2012年からフォトグラファーとしての活動を開始し、現在はIT技術・セキュリティのコンサルティング業務に携わっている。