
HPCの歩み50年記事一覧

スパコンリスト日本

記事寄稿について

Nvidia、64ビットコンピューティングは放棄していない
オリジナル記事「Nvidia Says It’s Not Abandoning 64-Bit Computing」

Nvidiaはスーパーコンピューティングコミュニティの一部から批判を受けている。同社はAIに有用な低精度計算の性能向上を優先し、従来のモデリングやシミュレーション作業に必要な64ビット性能を軽視しているという指摘だ。しかしNVIDIA幹部はHPCwireに対し、64ビットコンピューティングを放棄しているわけではなく、cuBLASのような新しいエミュレーションライブラリが助けとなり、次世代NVIDIA GPUでは64ビット性能が向上すると語った。
テネシー大学のジャック・ドンガラは、先ごろ開催されたSC25カンファレンスで新たなTOP500リストを発表した際、NVIDIAのFP64性能がホッパーからブBlackwellへ移行しても実質的な向上が見られない点を強調した。
「プラットフォームの浮動小数点演算能力は前世代から改善されていない。64ビット性能は向上していない」とドンガラは記者会見で述べた。「我々が目にするのは、帯域幅は向上したものの、浮動小数点演算能力が停滞したプロセッサだ。」
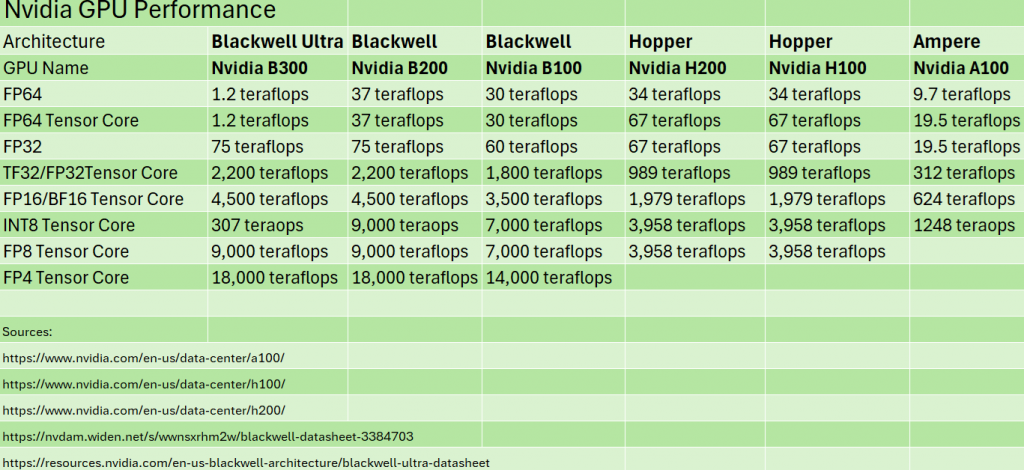
NVIDIAのHopper H100と後継のH200は、いずれもFP64で34テラフロップス、Tensor CoreではFP64で67テラフロップスの性能を備えている。(テンソルコアはGPU上の専用エンジンで、行列乗算を高速化し混合精度ワークロードをサポートする。)これは2020年にNvidiaがAmpere A100 GPUで実現したFP64性能9.7テラフロップス、FP64テンソルコア性能19.5テラフロップスから大幅な向上であった。
NVIDIAが2024年にBlackwellアーキテクチャを発表した際、64ビット演算性能は低下し、B100ではFP64とFP64 Tensor Core性能がわずか30テラフロップスだった。NVIDIAはB100を出荷せず、代わりにB200とGB200 Grace Blackwell「スーパーチップ」を提供することを選んだ。B200はB100よりFP64およびFP64テンソルコア性能がわずかに向上したものの、総合的なFP64テンソルコア性能ではH200に及ばなかった。このため従来型HPCワークロードでは、旧世代(かつ低価格)のH100やH200の方が優れた選択肢となった。
 |
| 最近のNvidia GPUの性能 |
NvidiaがB300 Ultra Blackwell GPUを発表した時点で、FP64およびFP64テンソルコアの性能はほぼ付随的な要素に過ぎず、この形式の演算に割り当てられたテラフロップスはわずか1テラフロップスに満たず、B200やH200/H100よりも大幅に低かった。しかしBlackwellチップは、AIワークロードが要求する低精度FP4演算において14ペタフロップス以上の性能を発揮する。
明らかに、NvidiaはBlackwellチップで低精度AIワークロードを重視している。大規模言語モデル(LLM)やその他のAIモデルの訓練・実行に、ますます膨大な演算能力が求められる市場の要求に、同社は適切に対応しているのだ。同社のGPU販売は極めて好調で、Nvidiaを世界初の時価総額5兆ドル企業に押し上げた。この事実を否定するのは難しい。
しかし(いつもそうだが)、HPC関係者は少し取り残された気分だ。材料科学、気候モデリング、計算流体力学においては、生のFP64性能に代わるものはない。高帯域メモリ(HBM)を山ほど積めるのは確かに素晴らしい。結局のところ、メモリが多すぎるなんて文句を言う者などいるだろうか?だがこうした進歩はAIの要求によって推進されているもので、HPCのためではない。
AIが科学計算を変革しているのは確かだ——米国政府のジェネシス・ミッションの取り組みを見れば明らかだ——しかし現実には、新しいGPUはHPC分野が求めるFP64性能を提供していない。モデリングやシミュレーションといったワークロードを実行するには、この性能が不可欠だ。何十年もHPCの基盤となってきた分野である。
 |
|
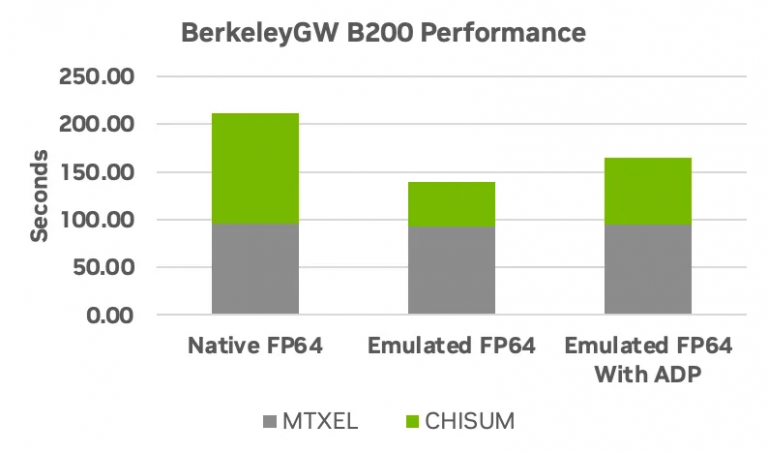
| cuBLASはFP64をエミュレートすることで性能向上をもたらす。バークレーGWイプシロンパッケージの実行結果がそれを示している(出典:Nvidia) | |
「FP64は研究機関だけでなく、製造業、エネルギー、金融、医療など幅広い企業にとって、ユーザーコミュニティにとって極めて重要だ」とIntersect360 ResearchのCEO、アディソン・スネルは述べた。「我々のHPC-AIリーダーシップ組織(HALO)の諮問委員会は、これを業界が直面する最重要課題の一つとして指摘している。
『科学のためのAI』を目指すなら、64ビット演算は必須要件と見なすべきだ。」
NVIDIAのHPC・AIハイパースケールインフラソリューション担当シニアディレクター、ディオン・ハリスはこう語る。「Blackwellの64ビット性能がHopperに及ばないからといって、NVIDIAがこの分野での主導権を放棄しているわけではない。」
「我々のプラットフォームを見ると、FP64は依然として重要な要件だ。なぜなら、これらの驚異的なAI代替モデルを創出するには…基盤となる真実値が必要だからだ。これは多くの場合、中核となるシミュレーションに基づいている。それを基に他の多くの活動を訓練・開発するか、少なくともそれらを検証できる」とハリスは語った。「したがってFP64が中核であることは認識している。」
ハリスは10月にリリースされたcuBLASを挙げた。これはTensorコア上で倍精度(FP64)演算をエミュレートするCUDA-X数学ライブラリだ。ハリスによれば、cuBLAS APIを使用することでFP64行列乗算の性能が1.8倍向上するという。ハリスは「ソフトウェアでこうした革新を実現することで、HPC専門家はNVIDIAが提供する機能群から必要な精度を得られるようになる」と述べた。
「我々は開発者環境にこれらの機能を公開し、必要なFP64を実現できるようにしている」とハリスはHPCwireに語った。「しかし重要なのは、チップをHDL向けに最適化しようとしているわけではない点だ。誰もが、それは価値がないと認めている。重要なのは科学的な研究を確実に実行できることであり、シミュレーションからデータ処理、トレーニング、推論に至るまでの全ワークストリーム、そして新たな計算科学ワークフロー内で発生するフィードバックループ全体を実現するために、我々は多大な努力を注いでいるのだ。」
 |
|
| Nvidia GH200 グレース・ホッパー スーパーチップ(出典:Nvidia) | |
物理的に低精度な環境内で高精度環境をエミュレートする手法は、開発者が採用する手法の一つだとスネルは述べた。「だが64ビット演算は64ビットベクトル命令とは異なる」と彼は付け加えた。「これは複雑な道筋だ。」
HPC業界は過去に同様の課題に直面してきた。「これはベクトル処理からスカラ処理への移行、あるいは共有メモリシステムから分散メモリクラスタへの移行で見られた変化と似ている」とスネルは語った。「プログラミングモデルは適応せざるを得なかった。これらの移行には時間がかかり、アプリケーションによってはより長くかかった。HPCは前進する方法を見出すものだ。」
HPC専門家は64ビット性能の向上も期待できる。ハリスは詳細を明かせなかったが、NVIDIAが将来のGPUにおいて64ビット演算の「中核となる基本性能」を向上させる方向で検討中だと示唆した。
「次世代アーキテクチャでは確実に追加機能を導入するつもりだ」と彼は述べた。「シミュレーションワークロードを駆動する必要な性能を確実に提供することに真剣に取り組んでいる。これは最終的にAIベースのアプローチを実装する上での重要な推進力になると考えている。なぜなら、その作業には中核的なシミュレーションが必要だからだ。」
その具体的な意味は、来年3月のGTC 2026まで待つ必要がある。HPC市場が望むのは、A100 AmpereからH100 Hopper世代で見られたような、FP64における大幅な性能向上の復活だろう。Nvidiaがそれを実行する用意があるかは不明だ。特にAI性能とのトレードオフを意味する場合、なおさらである。
答えは3月に明らかになるだろう。
特別イベント

寄稿者
![]() 西克也
西克也
西克也はフェアチャイルド社、クレイ・リサーチ社、ベストシステムズ社など、30年以上に渡ってHPCに関する仕事に従事している。Hpcwire Japanの編集長として記事の作成と翻訳を行っている。
![]() 島田佳代子
島田佳代子
1999年~2007年まで英国在住。2001年よりスポーツ、旅、ビジネス、映画など幅広いジャンルで執筆活動を開始し、Hpcwire Japanでは主に日本のHPC業界が世界に誇る研究者、開発者の方々のインタビューを担当。
![]() 小柳義夫
小柳義夫
小柳義夫氏は40年以上に亘ってHPCに携わってきた研究者であり、日本のHPC業界における生き字引として有名。現在 高度情報科学技術研究機構に所属し、産業界のHPC推進にあたっている。
![]() 小西史一
小西史一
小西史一は、理化学研究所、東京工業大学においてHPCおよびバイオインフォマティクスに関する研究と教育に携わってきた研究者。2012年からフォトグラファーとしての活動を開始し、現在はIT技術・セキュリティのコンサルティング業務に携わっている。