
HPCの歩み50年記事一覧

スパコンリスト日本

記事寄稿について

ジェネシス計画:FP64性能で尾崎スキームに大きく依存
オリジナル記事「Genesis Mission Will Lean Heavily on Ozaki Scheme for FP64 Capability」

エネルギー省科学担当次官ダリオ・ギルは先週HPCwireに対し、最新世代のGPUはAIワークロードに適した低精度性能を重視しているが、64ビット浮動小数点(FP64)のような高精度計算は、ジェネシス計画とAIによる科学的発見の加速という目標にとって依然として「極めて重要」だと述べた。
「[AMD CEO]リサ・シュウと[エヌビディア CEO]ジェンセン・フアンとの双方との議論で、両社ともFP64への強いコミットメントを示し、継続すると表明した」とギルは先週のインタビューで語った。「我々にとってこれは非常に重要だ。なぜなら、これを代替と見なしていないからだ。これらは補完的な関係にある。」
科学計算の基盤となってきたモデリング・シミュレーションのワークロードを支える高性能ハードウェアと、新たなAI技術のための性能の両方が重要だとギルは述べた。さらに、これら二つの計算手法が連携し、AIを活用した科学技術における限界突破を目指すジェネシス・ミッションの目標を支えると付け加えた。
「高精度で動作する高忠実度シミュレーションコードがある。そのコードを検証後、基礎として訓練用サンプルを生成し、サロゲートモデルを訓練する。最終的にAIスーパーコンピュータで実行するのだ」とギルは述べた。「生産性や解決までの時間において、しばしば10倍、20倍、100倍のメリットが得られる。」
 |
|
| エネルギー省科学担当次官ダリオ・ギルが先週HPCwireとの対談で語った | |
AIモデルによる生産性向上は膨大だが、実験・シミュレーション・訓練で構成されるループを維持することが前提だと彼は付け加えた。
「このループを断ち切り『シミュレーションコードはもう使わない』と言えば、問題が生じる。実験データだけではこのプロセスを完結させられないからだ」 とギルは語った。「我々にとってこれは根本的に重要だ。継続的に維持すべき既存コードがミッション上極めて重要であるだけでなく、AIワークフローを実現するためにも必要だ。このループが存在することを人々は理解すべきだ。だから様々なアーキテクチャアプローチを維持することは我々にとって非常に重要だ。」
HPCコミュニティでは、最新GPUにおけるFP64の性能向上が見られないことについて懸念が示されている。テネシー大学のジャック・ドンガラは、11月のSC25におけるTop500記者会見でこの問題を提起し、「プラットフォームの浮動小数点演算能力は前世代から改善されていない。まったく改善されていない」と述べた。
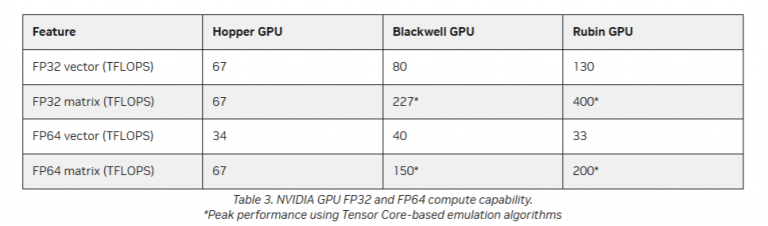
ここでの状況を把握するため、エヌビディア GPUの過去3世代を見てみよう。2022年に出荷されたエヌビディア Hopper H100チップは34テラフロップスのFP64性能を備えていた。一方、第一世代のBlackwell B100チップは30テラフロップスだった。第2世代のBlackwell B200は37テラフロップスを実現し、NVL4およびNVL72システムに搭載されたGB200Blackwellは40テラフロップスのFP64演算性能を発揮した。
エヌビディアが先月共有したデータによれば、次世代Rubin GPUのネイティブFP64性能はわずか33テラフロップスとなる。これはBlackwellのネイティブFP64性能を下回り、Hopperの性能すらも下回る数値だ。しかし、Rubin GPUはTensor Coreベースのエミュレーション機能を有効にした場合、200テラフロップスのFP64行列演算性能を発揮する。これはBlackwell GPUのエミュレートFP64行列性能150テラフロップス、HopperのエミュレートFP64性能67テラフロップスを上回る数値だ。
 |
|
| RubinはネイティブFP64性能で33テラフロップスを実現する(出典:エヌビディアブログ「NVIDIA Rubinプラットフォームの内部:6つの新チップ、1台のAIスーパーコンピュータ」) | |
エヌビディアが最新Rubin GPUで低精度AIワークロードを推進するため全速力で取り組む中、同社はcuBLASへの依存度を高めていく。これはTensorコア上で倍精度演算をエミュレートするCUDA-X数学ライブラリであり、FP64性能指標の向上を維持する役割を担う。
「我々はこれらの機能を開発者環境に公開し、必要なFP64性能を確実に得られるようにしようとしている」と、エヌビディアのHPCおよびAIハイパースケールインフラソリューション担当シニアディレクター、ディオン・ハリスは昨年12月にHPCwireに語った。
エヌビディアのエミュレーション技術は、2012年に尾崎克久が初めて提唱した「尾崎方式」に依存している。この手法は低精度演算を活用することで、高精度な行列乗算を実現する方法を提示する。「この手法は、高精度入力行列を複数の成分に分割し、それらの成分に対して低精度演算を用いて行列乗算を実行することでこれを実現する」と、HPCwireの寄稿者ダグ・イードラインは2025年4月に記している。「その後、結果を統合して最終的な高精度な行列積を得るのだ。」
エヌビディアは、低精度Tensor Coreハードウェア上で高精度ワークロードをエミュレートするために尾崎方式を採用する正当性を主張している。なぜなら、Cudaコアを追加してFP64の純粋な性能を向上させても、HPCアプリケーションの全体的な性能は実際には向上しないからだ。
「実稼働シミュレーションコードの分析によれば、持続的なFP64性能のピークは行列乗算カーネルで発生することが多い」とエヌビディアは1月5日のブログ記事で記している。「Hopperは専用ハードウェアでこれらの処理経路を高速化した。Blackwellを経て現在のRubinでは、この戦略を進化させ、低精度テンソルコアを複数パスで活用することで高FP64行列スループットを達成しつつ、統合ワークロード向けのアーキテクチャ柔軟性を維持している。」
 |
|
| エヌビディアは、今後発売予定のRubin GPUの仕様を公開した | |
「同時に、行列カーネルが支配的でない科学アプリケーションでは、専用のFP64ベクトル性能が依然として重要だ」とエヌビディアは続けた。「こうしたケースでは、性能はレジスタ、キャッシュ、高帯域メモリ(HBM)を通じたデータ移動によって制約され、純粋な演算能力ではない。したがってバランスの取れたGPU設計では、利用可能なメモリ帯域幅を飽和させるのに十分なFP64リソースを確保し、効果的に活用できない演算能力の過剰割り当てを回避する。」
ここには多くの変動要素が絡んでいる。従来のモデリング・シミュレーションワークロードには、エヌビディア GPUのCUDAコアやAMD Instinct GPUのストリームプロセッサが提供する生のFP64演算能力が必要だ。同時に、エヌビディアチップのTensorコアやAMDチップのマトリックスコアで低精度で動作するAI性能の向上も求められる。ジェネシス・ミッションはAI for Scienceと科学技術応用向けに多様なAIを生成する可能性が高く、それぞれがわずかに異なる計算要件を持つだろう。エヌビディアとAMDが行列演算コアを強化し、FP64演算をオザキエミュレーションに依存する形で最適なバランスを達成したかは未確定だが、HPCコミュニティの多くが注目する要素であることは確かだ。
特別イベント

寄稿者
![]() 西克也
西克也
西克也はフェアチャイルド社、クレイ・リサーチ社、ベストシステムズ社など、30年以上に渡ってHPCに関する仕事に従事している。Hpcwire Japanの編集長として記事の作成と翻訳を行っている。
![]() 島田佳代子
島田佳代子
1999年~2007年まで英国在住。2001年よりスポーツ、旅、ビジネス、映画など幅広いジャンルで執筆活動を開始し、Hpcwire Japanでは主に日本のHPC業界が世界に誇る研究者、開発者の方々のインタビューを担当。
![]() 小柳義夫
小柳義夫
小柳義夫氏は40年以上に亘ってHPCに携わってきた研究者であり、日本のHPC業界における生き字引として有名。現在 高度情報科学技術研究機構に所属し、産業界のHPC推進にあたっている。
![]() 小西史一
小西史一
小西史一は、理化学研究所、東京工業大学においてHPCおよびバイオインフォマティクスに関する研究と教育に携わってきた研究者。2012年からフォトグラファーとしての活動を開始し、現在はIT技術・セキュリティのコンサルティング業務に携わっている。