
HPCの歩み50年記事一覧

スパコンリスト日本

記事寄稿について

Googleクラウド、16GPUのA100インスタンスを発表
Tiffany Trader

5月にNvidiaのAmpere A100 GPUが発表された後、Google Cloudは、Google Compute Engine上でA100 “Accelerator Optimized” VM A2インスタンスファミリーのアルファ版の提供を発表した。インスタンスは、NVSwitchインターコネクトを使用して2台のHGX A100 8GPUベースボードを組み合わせたHGX A100 16-GPUプラットフォームを搭載している。
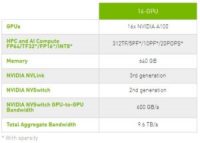 |
|
| 16-GPU A100 HGXの構成 | |
新しいインスタンスファミリーは、機械学習トレーニングや推論、データ分析、ハイパフォーマンス・コンピューティングワークロードを対象としている。Nvidiaによると、新しいテンソルおよびスパーシティ機能により、各A100 GPUは、前世代GPUと比較して最大20倍の性能向上を実現しているという。
VMのA2ファミリーは、1台から16台のGPUまでの5つの構成で提供され、CPUとネットワークのGPUに対する比率は2つの異なるものとなっている。Ampereのマルチインスタンスグループ(MIG)機能により、各GPUを7つの異なるGPUに分割することができる。
最も要求の厳しいAIワークロードを持つ顧客は、合計640GBのGPUメモリと1.3TBのシステムメモリを提供するフル16GPUインスタンスにアクセスすることができ、NVSwitchを介して最大9.6TB/sのアグリゲーション帯域幅で接続される。A2ファミリーの価格は現時点では明らかにされていないが、このハードウェアをそのまま購入するには40万ドル近くかかることになり、最新のHPCハードウェアがその数分の1のコスト、オンデマンドで利用できるクラウドベースのアプローチの民主化力を実証している。
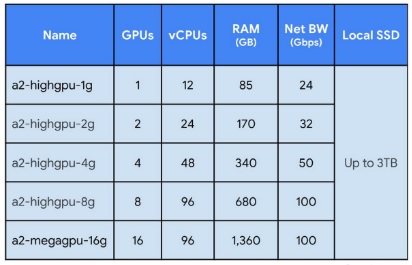 |
NvidiaのDGX A100システムが64コアのAMD第2世代Eypc Romeプロセッサを搭載しているのに対し、HGXプラットフォームはAMDまたはIntelプロセッサのいずれかで構成することができる。Google Cloudは後者のオプションを選択し、A2マシンは12~96個のIntel Cascade Lake vCPUに加えて、オプションでローカルSSD(最大3TB)を搭載している。
Googleクラウドは、Ampereの登場から2ヶ月足らずで新しいA2ファミリーを発表している。これは、GPUチップの発表からクラウドへの導入までの記録的な速さであり、AIワークロードに牽引されてクラウドでのHPC需要が高まっていることを反映している。これにはクラウドプロバイダーによる最新のアクセラレータギアの導入を加速させるための着実な行進があった。NvidiaのK80 GPUがクラウド(AWS)に導入されるまでには2年かかり、Pascalでは約1年、Voltaでは5ヶ月、Ampereでは数週間に短縮された。Googleは、NvidiaのT4グラフィックスプロセッサをデビューさせた最初のクラウドプロバイダーでもある。(GoogleはPascal P100インスタンスを最初に導入したのもGoogleで、AWSはPascalをスキップしたが、Voltaでは最初に導入した。)
また、Google Cloudは、Google Kubernetes Engine、Cloud AI Platform、その他のサービスに対するNvidia A100のサポートも発表した。
Ampereの発表の際の発言から、Amazon Web Services、Microsoft Azure、Baidu Cloud、Tencent Cloud、Alibaba Cloudなど、他の著名なクラウドベンダーによるA100の採用が期待されるかもしれない。
A2インスタンスは現在非公開のアルファプログラムで利用可能で、Googleによると、一般公開と価格は今年後半に発表されるとのことである。
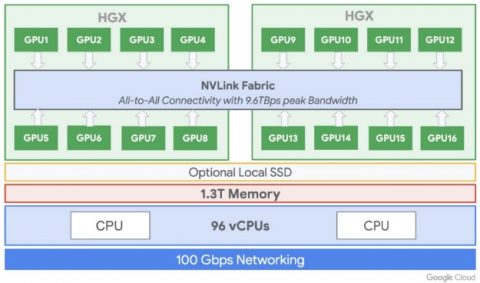 |
| Compute Engineの新しいA2-MegaGPU VM:最大9.6 TB / sのNVLINK帯域幅を備えた16個のA100 GPU(出典:Google Cloud) |
特別イベント

寄稿者
![]() 西克也
西克也
西克也はフェアチャイルド社、クレイ・リサーチ社、ベストシステムズ社など、30年以上に渡ってHPCに関する仕事に従事している。Hpcwire Japanの編集長として記事の作成と翻訳を行っている。
![]() 島田佳代子
島田佳代子
1999年~2007年まで英国在住。2001年よりスポーツ、旅、ビジネス、映画など幅広いジャンルで執筆活動を開始し、Hpcwire Japanでは主に日本のHPC業界が世界に誇る研究者、開発者の方々のインタビューを担当。
![]() 小柳義夫
小柳義夫
小柳義夫氏は40年以上に亘ってHPCに携わってきた研究者であり、日本のHPC業界における生き字引として有名。現在 高度情報科学技術研究機構に所属し、産業界のHPC推進にあたっている。
![]() 小西史一
小西史一
小西史一は、理化学研究所、東京工業大学においてHPCおよびバイオインフォマティクスに関する研究と教育に携わってきた研究者。2012年からフォトグラファーとしての活動を開始し、現在はIT技術・セキュリティのコンサルティング業務に携わっている。