
HPCの歩み50年記事一覧

スパコンリスト日本

記事寄稿について

研究:混合精度演算を利用した数値計算法の調査
Hartwig Anzt、Jack Dongarra

編集部注:強力な混合精度演算を実現するために急増するハードウェアの進歩を利用するため、DoEはこれらの新しい機能を最大限に活用するための新しいアルゴリズムの開発に向けた取り組みを開始した。この新しい取り組みは、従来のソフトウェア最適化からの意味のあるタイムリーな転換であると、Jack DongarraとHartwig Anztは述べている。その第一歩として、Dongarra、Anztおよび同僚達は数値線形代数のコミュニティを調査し、その結果を豊富なレポートにまとめた。ここで紹介するDongarraとAnztの簡単な解説は、レポートの内容を垣間見ることができるものだ。二人ともHPCではおなじみの人物である。最後に簡単な略歴が含まれている。
過去数年間に、ハードウェアベンダーは、機械学習コミュニティの需要と低精度フォーマットでの高い計算能力の要求に応えて、低精度の特殊機能ユニットの設計を開始している。また、オークリッジ国立研究所のSummitスーパーコンピュータに搭載されているNvidiaテンソルコアのように、サーバライン製品にも低精度特殊関数ユニットが搭載されるようになってきており、IEEE倍精度よりも桁違いに高い性能を実現している。
同時に、一方の計算能力と他方のメモリ帯域幅とのギャップは増大し続けており、データアクセスや通信は演算処理に比べて法外に高価なものとなっている。ハードウェアのトレンドを無視して従来の道を続けるか、ハードウェア設計の変化に合わせてソフトウェアスタックを調整するかの選択を迫られていたため、米国エネルギー省のExascale Computingプロジェクトでは、多精度に焦点を当てた取り組みを構築し、低精度で利用可能な計算能力を利用した新しいアルゴリズムの設計とエンジニアリング、およびアプリケーション固有のニーズに合わせた通信フォーマットの調整に挑戦するという積極的なステップを取ることを決定した。
多重精度重視の取り組みを開始するために、数値線形代数コミュニティの調査を行い、既存の多重精度に関する知識、専門知識、ソフトウェアの能力をすべてこの景観解析レポートにまとめた。また、「成熟した技術」とは言えないまでも、多精度に焦点を当てた取り組みの中で、生産品質にまで成長する可能性を秘めた、現在の取り組みや予備的な結果も含まれている。読者は数値線形代数の基礎を熟知していることを期待しているため、アルゴリズム自体の詳細な背景を説明することは控えるが、多精度・多精度混在技術がこれらの手法の性能向上にどのように役立つかに焦点を当て、従来の固定精度手法を大幅に上回る応用例のハイライトを紹介する。
本レポートでは、低精度BLAS演算、線形システムの系の解法、最小二乗問題、混合精度を用いた固有値計算を扱っている。これらは、密で疎な行列計算、直接法、反復法を用いて実証されている。提示されたアイデアは、計算時間の大部分を低精度計算で利用し、その後、解の精度を向上させるために数学的手法を使用して、解の精度を向上させ、より短い時間で全精度の精度を実現することを試みている。
最新のアーキテクチャでは、32ビット演算の性能は64ビット演算の性能の少なくとも2倍以上になることがよくある。これには2つの理由がある。第一に、ほとんどの最新のプロセッサでは、32ビット浮動小数点演算の実行速度は、通常、64ビット浮動小数点演算の実行速度の2倍である。第二に、メモリシステムを移動するバイト数が半減することである。より低い精度、例えば16ビット演算で計算を行うことも可能かもしれない。
低精度での計算能力を利用する一つのアプローチは、多くの場合、問題の単精度解を倍精度の精度を達成するところまで洗練させることができるという観察から動機づけられている。この改良は、例えば,繰り返し式に従って関数 f (x) のゼロを計算する Newtons アルゴリズム(式 (1) を参照)によって達成される。
 |
一般的には、単精度演算で始点とf(x)を計算し、倍精度演算で絞り込み処理を行うことになる。絞り込み処理が解の初期計算よりも安価であれば、倍精度の精度は単精度の精度とほぼ同じ速度で達成できる。
目を見張るような結果が得られている。図1では、Nvidia V100 GPU上の密なソルバーを使用した一次方程式の一般的なシステムの解を、64ビット、32ビット、16ビットの浮動小数点演算による因数分解の性能を比較し、その後、64ビットの因数分解を使用して達成されたものに対して、32ビットと16ビットの解を改良するための洗練技術を使用している。
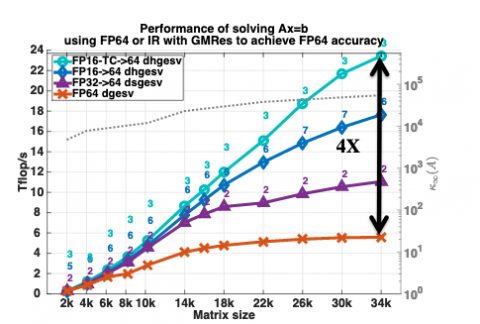 |
| 図1: MAGMAの混合精度反復細分におけるFP64ソルバーに対する高速化。反復あたりのオーバーヘッドは≈2%であり、混合精度LU対通常のFP16 LU(FP64収束までの3回対7回の反復)では反復回数の面で2倍以上のオーバーヘッドがないことに注意 |
この調査報告書では、これらの技術を用いた方法やアプローチについて、より詳細に紹介している。(https://www.icl.utk.edu/files/publications/2020/icl-utk-1392-2020.pdf)。
著者略歴 – Hartwig Anzt
Hartwig Anztは、カールスルーエ工科大学(KIT)のスタインバック計算センターのHelmholtz-Young-Investigatorグループのリーダーである。カールスルーエ工科大学で数学の博士号を取得した後、2013年にテネシー大学のJack Dongarraのイノベーティブ・コンピューティング・ラボに参加した。2015年からはテネシー大学の上級研究員にも就いている。Hartwig Anztは、数値数学に強いバックグラウンドを持ち、次世代ハードウェアアーキテクチャのための反復法と前提条件付け技術を専門としている。彼のHelmholtzグループは、エクサスケールでの数値計算のための固定小数点法(FiNE)に2022年までの資金援助を受けている。Hartwig Anztは、高品質なソフトウェア開発の長い実績を持っている。彼は、MAGMA-sparseオープンソースソフトウェアパッケージの著者であり、Ginkgo数値線形代数ライブラリの管理責任者および開発者であり、また、すぐに利用可能な数値線形代数ライブラリを提供する米国エクサスケール・コンピューティングプロジェクトの一員でもある。
著者略歴 – Jack Dongarra
1972年にシカゴ州立大学で数学の学士号を、1973年にイリノイ工科大学でコンピュータサイエンスの修士号を取得した。1980年にニューメキシコ大学で応用数学の博士号を取得した。1989年までアルゴンヌ国立研究所に勤務し、上級科学者となった。現在は、テネシー大学コンピュータサイエンス学部のコンピュータサイエンスの大学特別教授、オークリッジ国立研究所(ORNL)のコンピュータサイエンス・数学部門の特別研究員、マンチェスター大学コンピュータサイエンス・数学学校のチューリングフェロー、ライス大学コンピュータサイエンス学部の非常勤教授を務めている。
特別イベント

ISC 2026
6月 22 - 6月 26
International Conference for High Performance Computing, Networking, Storage & Analysis (SC26)
11月 15 - 11月 20
寄稿者
![]() 西克也
西克也
西克也はフェアチャイルド社、クレイ・リサーチ社、ベストシステムズ社など、30年以上に渡ってHPCに関する仕事に従事している。Hpcwire Japanの編集長として記事の作成と翻訳を行っている。
![]() 島田佳代子
島田佳代子
1999年~2007年まで英国在住。2001年よりスポーツ、旅、ビジネス、映画など幅広いジャンルで執筆活動を開始し、Hpcwire Japanでは主に日本のHPC業界が世界に誇る研究者、開発者の方々のインタビューを担当。
![]() 小柳義夫
小柳義夫
小柳義夫氏は40年以上に亘ってHPCに携わってきた研究者であり、日本のHPC業界における生き字引として有名。現在 高度情報科学技術研究機構に所属し、産業界のHPC推進にあたっている。
![]() 小西史一
小西史一
小西史一は、理化学研究所、東京工業大学においてHPCおよびバイオインフォマティクスに関する研究と教育に携わってきた研究者。2012年からフォトグラファーとしての活動を開始し、現在はIT技術・セキュリティのコンサルティング業務に携わっている。