
HPCの歩み50年記事一覧

スパコンリスト日本

記事寄稿について

Rice Oil and Gas HPC Conference基調講演、エクサスケールの教訓とテクノロジーの普及
John Russell

米国のExascale Computing Initiative(ECI)は、この10年間、精力的に活動を続けてきた。今年は最初のエクサスケールスーパーコンピュータである「Frontier」が発表され、その後「Aurora」、「El Capitan」が発表される予定だ。エクサスケールに由来する技術は、どのくらいの期間でHPCの世界に普及するのだろうか。ECIのソフトウェア部門であるExascale Computing Project (ECP)のアプリケーション開発担当ディレクターであるAndrew Siegelは、先週開催されたRice Oil and Gas HPC Conferenceの基調講演で、この質問に答えるとともに、ECP全体の進捗状況をまとめた。
 |
|
| Andrew Siegel(ECPおよびANL) | |
「ECPプロジェクトの進捗状況、予想以上に困難だったこと、意外にうまくいったこと、まだ残っていること、今後の展望についてお話します。その前に、皆さんが講演中に気になるであろう基本的な質問をさせていただきたいと思います。私にとって非常に重要なことは、誰もがハイパフォーマンスコンピューティングの最先端で活動しているわけではなく、ほとんどはミッドレンジのようなところで起こっているということです」と Siegelは語った。
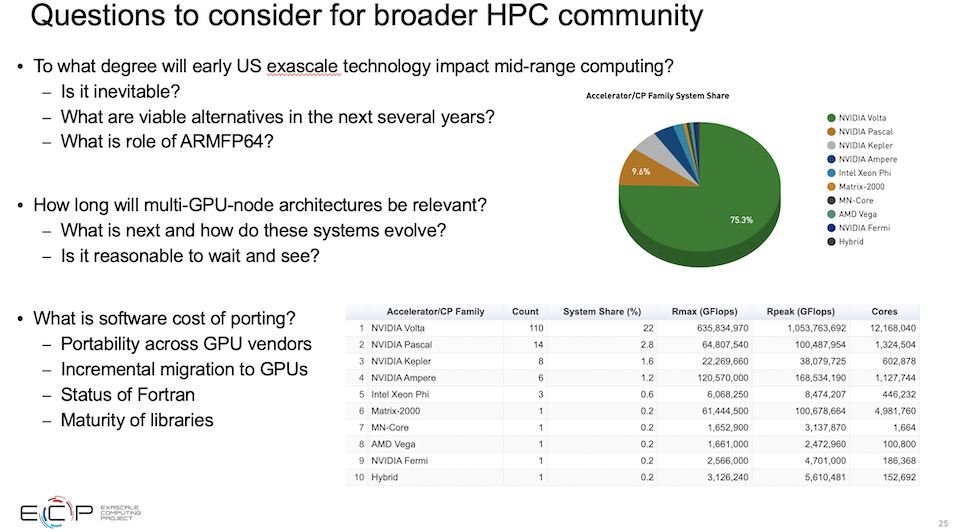
「ひとつの疑問は、この米国の初期のエクサスケール技術が、ミッドレンジのハイパフォーマンスコンピューティングにどの程度の影響を与えるかということです。そして、これは避けられないことなのでしょうか。それとも、そのような影響は見られないのでしょうか。また、今後数年の間に調達を行う人たちにとって、実行可能な代替案は何でしょうか。私はさまざまな人と話をしてきましたが、たとえばGPUベースのシステムを今買うべきなのか、待つべきか。待つことの意味は何か。どのように決断すればよいのか。米国がエクサスケールへの第一歩として選択した技術に代わるものは何か。例えば、富岳に搭載されているARM64システムでしょうか。これらのアーキテクチャはどのくらいの期間有効なのでしょうか。そして、今回のエクサスケールの第一波の後には何が待っているのでしょうか。」
良い質問です
予想通り、Siegelの答えはより慎重なものだった。多くの技術はまだ始まったばかりであり、広く利用可能である勝者を選ぶことは容易ではないが、それでも、ECPの経験と教訓をスピーディーに再現したSiegelの言葉は貴重なものだった。例えば、これから登場するエクサスケールシステム(すべてのシステムがGPUで加速される)にアプリケーションを適合させるためには、ドメインエキスパートが果たすべき役割がリストの最上位に挙げられていた。
 |
「ほとんどの場合、AD(アプリケーション開発)チームはドメインサイエンティストが率いています。ドメインサイエンティストは、モデリングの問題や、それがどのようにバリデーションやベリフィケーションと関連しているのか、そして数値的なことを当然理解しています。しかし、ハードウェアの複雑さや、それを実現するために必要なハードウェアのアルゴリズムインターフェースなどは、ほとんど理解していません。そのため、チームには応用数学やコンピュータサイエンス、ソフトウェアエンジニアリングなどの専門家を配置しています。最も成功しているのは、これらの要素をすべて組み合わせ、非常に多様なチームを構成している場合です」とSiegelは述べている。
挑戦の気持ちを伝えるために:
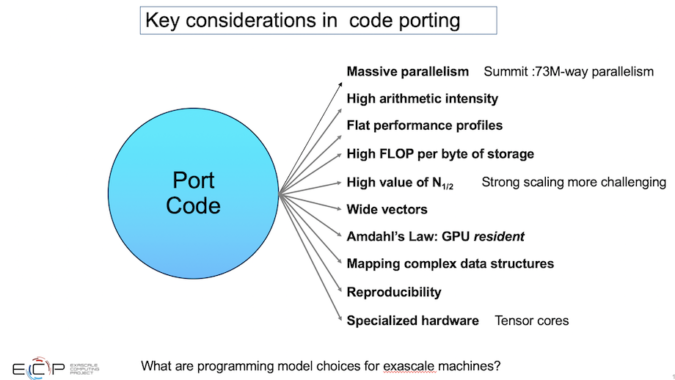
「5、6年前からこれらのプロジェクトを統括してきた中で、私が学んだことがあります。1つ目は、アルゴリズムから大規模な並列性を引き出すことができなければならないということです。これは言うまでもないことですが、大規模とはどのようなものかが分からなくなることがあります。プリ・エクサスケール・システムであるSummitでは、文字通りすべてを利用可能なすべての並列処理にマッピングすると7,300万度の並列処理になりますが、これはGPUタイプのアーキテクチャが効率的にスケジューリングできるようにオーバーサブスクライブする必要性を考慮していません。将来のシステムでは、10億通りの並列処理が、システムを効率的に利用するための出発点になることは想像に難くありません」とSiegelは語っている。
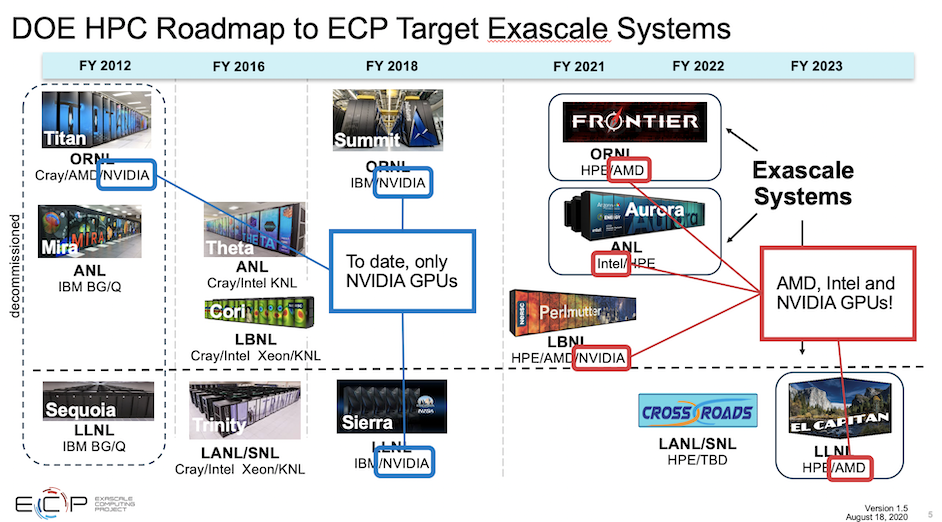
もちろん、ECPは、来るべきエクサスケールシステムを活用できるソフトウェアエコシステムを確保するための主要な役割を担っている。これには、ハードウェアと統合、ソフトウェア技術、アプリケーション開発という、相互に関連する3つの分野が含まれる。初期の作業の多くは、同じアーキテクチャを持ち、Nvidia GPUを採用しているエクサスケール以前のSummitおよびSierraシステムで行われた。しかし、エクサスケールのポートフォリオには、AMDやIntelのGPUを使用するシステムも含まれているため、このような比較的シンプルなシステムは変わるだろう。
 |
 |
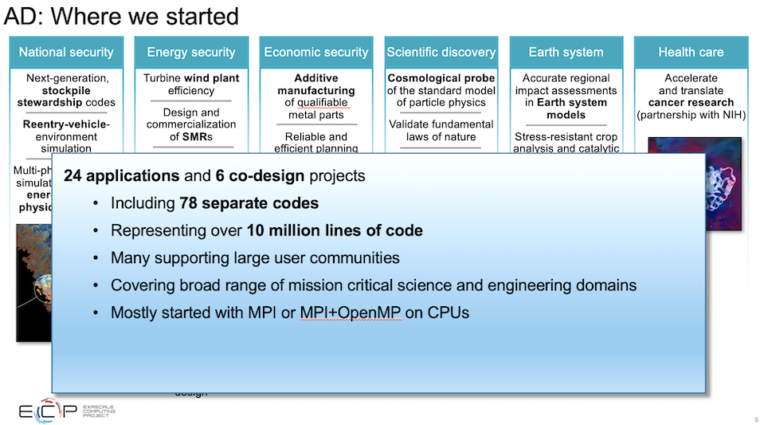
SiegelのADグループは、システムのアプリケーションの準備に重点を置いてきた。ECPは、6つのアプリケーション分野(国家安全保障、エネルギー安全保障、経済安全保障、地球システム、ヘルスケア)と、シミュレーションとデータ駆動(AI)のアプローチに重点を置いた24のアプリケーションに決定した。
「私たちが探していたのは、最先端の仕事をしてリスクを負うことを厭わない、ある種のモルモットのような人たちでした。そして、これらのシステムの使い方を理解し、これらのシステムでサイエンスを行い、同時にシステムの成熟にも貢献してくれる人を探していました。そのため、想像に難くないRFPプロセスが行われました。しかし、最終的には24のアプリケーションが選ばれ、エクサスケール時代への道を切り開いていくことになりました」とSiegelは語っている。
「100億行を超えるコードが対象となりました。非常に重要なことは、これらのコードの多くが、少なくとも私たちの分野では、大規模なユーザーコミュニティをサポートしているということです。計算化学の分野では1万人程度が上限ですが、数十万人になることもあります。他のアプリケーションでは、分子動力学はもっと多いかもしれませんし、宇宙物理学はまだ100の研究チーム、計算流体力学はもっと多いかもしれません。」
明らかにこれは大変な作業だが、今では完成に近づいている。Siegelは、具体的なアプリケーションと、より一般的なソフトウェアの問題の両方について語った。
「私が言及した24のアプリケーションは、いずれも次のような変遷を経ています。つまり、CPUまたはマルチスレッドのCPUのようなものから、CPUとシングルGPU、そして複数のGPUで動作するCPUへと移行しており、多様なマルチGPUアーキテクチャに新たな課題をもたらしています。これには、インテルやAMDの初期のハードウェアや、AIワークフローをターゲットにしたNvidiaの新しいハードウェア機能も含まれています。すべてのプロジェクトがSummitおよびSierraアーキテクチャに移植され、パフォーマンスが向上しました。これは、それぞれのアプリケーションに固有の、20倍から300倍の間のかなり複雑なメリット(FOM)によって定量化されているからです。このように、Summitプラットフォームでの成功は、このプロジェクトの大きな特徴です。そして、これはまた別の話になります」とSiegel.は述べた。
 |
 |
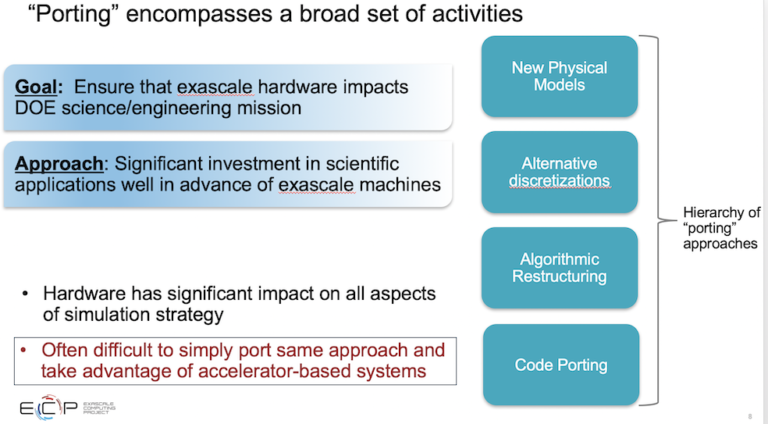
「私たちが学んだことの1つは、私にとって驚きであり、十分に強調することはできません。シミュレーションのすべての側面に影響を与える移植アプローチの階層が実際に存在するということです。コードの移植は、どのような場合でも、ループの並べ替え、データ構造の変更、メモリの合体と考えています。しかし、より基本的なアルゴリズムの再構築であるものもあります。これには、通信回避アルゴリズム、同期の低下、特殊なハードウェアの使用などが含まれる可能性があります。私たちは、ハードウェアに適した高次の手法で問題にアプローチすることでハードウェアへの追従性を高めることができるため、代替の離散化についても考えています」とSiegel氏は述べている。
「今、私たちはまったく新しい物理モデルを考えています。それは、新しいコンピューティングパワーを手に入れたからです。このようなコンピューティングハードウェアの大きな変化は、シミュレーション戦略のあらゆる側面に大きな影響を与えています。ほとんどの場合、同じアプローチを単純に移植して、加速器ベースのシステムを最大限に活用することは困難でした。」
 |
 |
 |
当然のことながら、新しいハードウェアへのアプリケーションの移植は困難を極め、時には、弱いスケーリングと強いスケーリングに関連する長所と短所に対処するための重要な選択を迫られることもあった。
「アクセラレータベースのシステムによる強力なスケーリングの悪影響を緩和するための巧妙な戦略がたくさんありました。HPCがアーリーアクセスマシンに依存しているソフトウェアエコシステムの成熟度には多くの問題があったのです。緻密な行列演算など、優れたパフォーマンスが求められるものです。これらのマシンでの実行を考えた場合、ハードウェアそのものではなく、ハードウェア周辺のすべてのものの成熟度を考えなければなりません。OpenMPオフロードの性能、GPUの居住性に関する戦略、統合仮想メモリの役割とその実現などです。」
「ノードに搭載されるGPUの数が増え、ノードがますます複雑になるにつれ、ノード間通信のコストが相対的に増加するという、実に興味深い問題が浮上してきました。10,000ノードではそれほど問題にならなかったMPIの実装が、シングルノードでの驚異的なパフォーマンスに対応しなければならなくなったのです。これが私たちの本当のボトルネックだと言われ始めています。このプロジェクトのこの段階までは、そうではありませんでした」とSiegelは述べた。
スピーディな進行にもかかわらず、Siegelは遭遇した多くの課題を掘り下げた。その意味では、彼の講演は直接視聴/掲載するのが最善であり、掲載の予定もある。ちなみに、カンファレンスの名称を少し変更する予定だ。来年は15年目で、「Rice Energy High Performance Computing Conference」となる。
最後にSiegel は、冒頭のコメントに戻り、エクサスケールプログラムのために開発された技術がどれくらいの速さで広くHPCの世界に浸透していくかについての大まかな考えを述べた。Siegel は、結局のところ、待つのもよいが、準備するのも賢明だと述べた。
「私が最初に抱いた疑問(以下、スライドを繰り返す)に立ち返ると、私はこれらの疑問に対する回答を持ち合わせていません。多くの場合、あなた自身の状況に依存します。しかし、この技術がミッドレンジコンピューティングにどの程度の影響を与えるのでしょうか。大きな影響を与える可能性が高く、すでに影響が出ていると言えるでしょう。実現可能な代替品はありますか。もちろん、あります。大急ぎをする必要はありません。x86やArmベースのシステムは、特別なベクター拡張機能の有無にかかわらず、確かに実行可能な代替品です。」
「飛び込む前に、自分のコードがこの種のシステムにどのようにマッピングされるのかを学び、推論してみてください。私は、ある種の傍観者である人々に向けて話しています。重要な問題のひとつは、より簡単に移植できたとしても、マルチGPUシステムに比べて移植のパフォーマンスにどのようなコストがかかるのかということです。コードを理解して評価することは重要だと思いますが、調達を行う場合は様子見の姿勢をとることも十分にありえます。移植にかかるソフトウェアコストは、ローカライズされたオペレーション、高いインテンシティ、パフォーマンスのほとんどがコードのごく一部であるような場合には非常に低くなります。しかし、計算集約型ではなく、コード全体にパフォーマンスが分散している場合や、非常に複雑なデータ構造を持っている場合、計算量の少ない作業を行うと、かなり高くなる可能性があります」と彼は述べている。
「以下に挙げたものはすべて進化を続けているもので、比較的未熟であり、すぐにさらに良くなるということも忘れてはなりません。つまり、プログラミングモデルを中心にまとまり始め、選択肢の数が減り、最良のものが固まっていくことになるでしょう。」
|
2021 Rice Oil and Gas High Performance Conferenceへのリンク:https://rice2021oghpc.rice.edu/programs/
スライドはSiegelの基調講演のものです。
特別イベント

寄稿者
![]() 西克也
西克也
西克也はフェアチャイルド社、クレイ・リサーチ社、ベストシステムズ社など、30年以上に渡ってHPCに関する仕事に従事している。Hpcwire Japanの編集長として記事の作成と翻訳を行っている。
![]() 島田佳代子
島田佳代子
1999年~2007年まで英国在住。2001年よりスポーツ、旅、ビジネス、映画など幅広いジャンルで執筆活動を開始し、Hpcwire Japanでは主に日本のHPC業界が世界に誇る研究者、開発者の方々のインタビューを担当。
![]() 小柳義夫
小柳義夫
小柳義夫氏は40年以上に亘ってHPCに携わってきた研究者であり、日本のHPC業界における生き字引として有名。現在 高度情報科学技術研究機構に所属し、産業界のHPC推進にあたっている。
![]() 小西史一
小西史一
小西史一は、理化学研究所、東京工業大学においてHPCおよびバイオインフォマティクスに関する研究と教育に携わってきた研究者。2012年からフォトグラファーとしての活動を開始し、現在はIT技術・セキュリティのコンサルティング業務に携わっている。