
HPCの歩み50年記事一覧

スパコンリスト日本

記事寄稿について

Hot Chips:Arm、Nvidia、IntelのDPUとIPUが登場
John Russell

今回のHot Chipsでは、クラウドやデータセンターのアーキテクチャにおいて重要な役割を果たす可能性のあるデータプロセッシングユニット(DPU)とインフラストラクチャプロセッシングユニット(IPU)が登場した。Arm、Nvidia、Intelの3社は、この新しいクラスのデバイスに関する講演を行った。各社の最新製品に関する技術的な詳細は目新しいものではないが、DPUとIPUのセッションが設けられたことは注目に値する。また、Octeon10(Marvell/Arm)、BlueFieldシリーズ(Nvidia)、Mount Evans(Intelの新チップ)など、すべての新製品にArm技術が採用されていることも興味深い。
DPU/IPUは、かつてはSmartNICのステロイドに過ぎないと思われていたが、支持者が増えている。DPUとIPU、あるいはその呼び名はともかく、DPUとIPUは増大する問題に取り組み、大きなメリットを提供するというコンセンサスが高まっている。大まかに言うと、現在ホストCPUで実行されているネットワーク制御、ストレージ管理、セキュリティなどの多くのハウスキーピング業務を肩代わりしようというものだ。これらのタスクは、データセンターやクラウド内のCPUリソースを確実に消費している。
「GoogleとFacebookの調査によると、さまざまなマイクロサービスのワークロードにおいて、(インフラストラクチャのワークロードが)CPUサイクルの22%から80%を消費していることがわかっています。」と、IntelのBrad Burresは講演で述べている。「このデータから、インフラアプリケーションをオフロードすることで、重要な分野でクラウド事業者に有意義な利益をもたらすことがわかります。」
Intelは、DPU/IPUの領域に乗り込んだ最近の大手企業だ。IntelのフェローであるBurresは、Intelが新たに設立したネットワーキング&エッジグループでIPUのアーキテクチャを担当している。Intel初のASIC IPUであるMount Evansは、Intelのアーキテクチャ・デイで発表されたばかりである。注目すべきは、Mount Evansがx86コアを使わず、Arm Neoverse N1コアを採用したことだ。これは、消費電力の面で有利になるからである。
「IPUはインフラストラクチャ・プロセッシング・ユニットの略で、Intelが最近導入した用語です。」とBurresはIntelの旗を立てる。「これまではSmartNICと呼んでいました。しかし、ネットワークだけでなく、コントロールプレーンを含むインフラアプリケーションが増えてきたため、より正確な名称を使用したいと考えました。IPUはDPUと呼ばれることもありますが、すべてがデータ処理を行うものであるため、この名称は多くのお客様を混乱させてしまいます。それよりも重要なのは、IPUがデータセンターアーキテクチャに革命をもたらすということです。」
競合他社との競争(とデバイスのネーミング)が始まる。
Hot Chipsの魅力の1つは、技術的な話に偏っていることであり、スライドを見れば、アプローチや能力について有益な情報が得られることが多い。程度の差こそあれ、今回もそうであった。ここでは、3つのプレゼンテーションの簡単なスナップショットを紹介する。
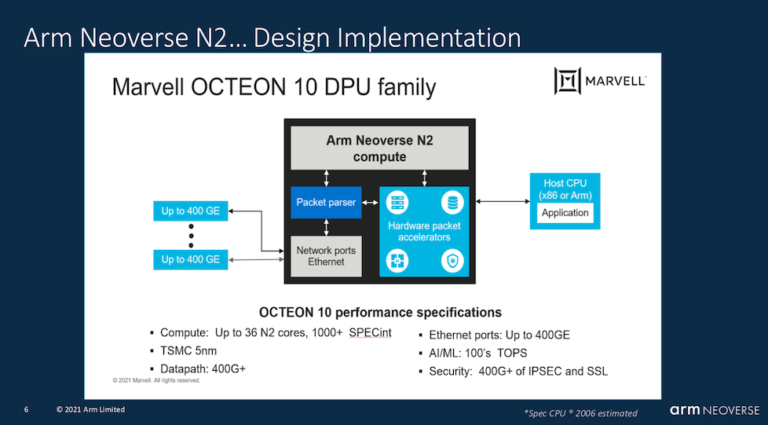
- Arm Neoverse N2とOcteon。Armの著名なエンジニアであるAndrea Pellegriniは、Arm Neoverseプラットフォームのロードマップを確認し、N1に比べてNeoverse N2がどのように進化しているかを掘り下げて説明した。提示された資料の多くはよく知られたものであった(HPCwireの報道を参照)。N2では、SVE2のサポート、CMN-700(コヒーレント・メッシュ・ネットワーク)、IPCの向上(40%)、分岐予測の大幅な改善などが行われている。今回のセッションに関連して、Marvell社が6月に発表した、Neoverse N2アーキテクチャを採用したOcteon10 DPUファミリーについても簡単に説明した。TSMCの5nmプロセスで製造される予定である。
- NvidiaのBlueFieldラインナップ。プリンシパルアーキテクトのIdan BursteinがNvidiaのビジョンを発表したが、技術的な詳細については多くの人が知っている内容であった(HPCwireの記事を参照)。Nvidiaは、Mellanox社の買収を通じて、スマートネットワークをフル機能のDPUに進化させることを最も長く追求してきた。BlueField-2は現在出荷中で、BlueField-3は来年の予定、BlueField-4の計画も進行中である。NvidiaのDPUに対するビジョンは壮大で、一般的に言われている仕事(ネットワーク、ストレージ、セキュリティ)だけでなく、他のアプリケーションの部分を含むように拡張することも含まれている。BlueField-2は70億トランジスタのSOCで、BlueField-3はArmコアとGPUコアを含めて220億トランジスタになる。
- IntelのMount Evans 登山。Burresは、実装を深く掘り下げることなく、その機能を大まかに説明した。Mount Evansは、Intelにとって初のASIC IPUである。これまでにもFPGAベースのIPU SOCはあったし、大まかには2019年にBareFoot Networksを買収した際の資産を活用しているという。その初期のターゲット市場は、膨大なx86のインストールベースがあるクラウドプロバイダーのようで、Burresは、Mount Evansは、誰とは言わなかったが、大手クラウドプロバイダーと共同で設計されたと述べた。
ここでは、それぞれのプレゼンテーションからいくつかのポイントと、設計上の選択や実装を垣間見ることができるいくつかのスライドを紹介する。
NeoverseにおけるArmの野望はDPUを含む
Armは、大規模データセンターには比較的新しい企業であり、Pellegriniは、第2世代のNeoverseであるN2は、より広いインフラ市場に貢献することを目的としていると述べている。「パートナーは、このプラットフォームを使って、5Gの展開に必要なような、電力エンベロープの制約があるシステムで、最適化されたローカルシステムを構築することができます。一方で、データセンター向けの高コア数、高周波数、高メモリ帯域のシステムを構築することもできます。」と述べている。N2の効率性プロファイルにより、ユーザは1つのソケットに多くのコアを詰め込むことができ、電力効率の高い特殊な設計に最適な設計となっていると述べている。
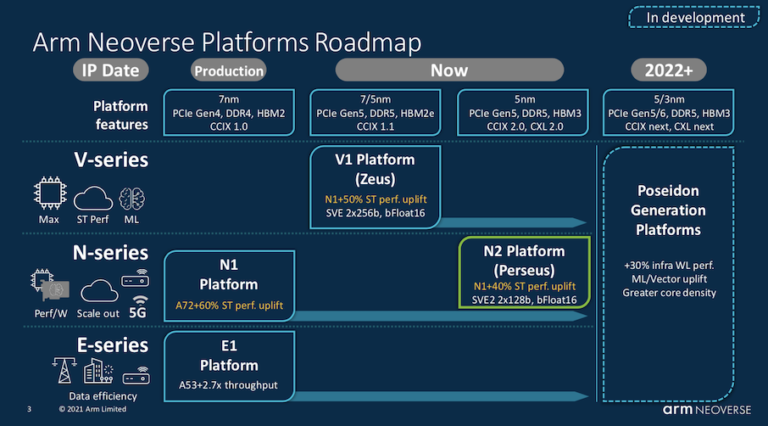 |
Pellegriniは、特殊用途の設計の例として、Marvell社のOcteon 10 DPUを挙げている。「このDPUは、汎用コンピュータシステムとしてNeoverse N2プラットフォームを採用しており、最大36個のN2コアを搭載しています。このデザインの具体化とその機能を見ると、MarvellのようなパートナーがいかにしてNeoverse N2プラットフォームを最大限に活用し、DDR 5やMPCエージェントファイルなどの最先端技術を利用して、画期的なネットワーク速度を実現できるかがわかります。ここでは、最大400ギガビットのイーサネットについて話しています。」
 |
 |
Neoverse N2では、MPAM(Memory Partition and Monitoring)が導入されている。MPAMは、「ユーザが共有システムのリソースを監視し、分割することで、競合の激しいマルチテナントシステムにおいても、より信頼性の高い一貫したパフォーマンスを確保することができる 」という技術である。また、Neoverse N2では、「ネストした仮想マシンを処理するための優れたハードウェア機能を導入し、一般的に使用される仮想マシン操作のオーバーヘッドとコストを削減する」など、利用のサポートが大幅に進化している。
NvidiaのBlueFieldはスタートダッシュに成功したか?
Bursteinは、他の研究者と同様に、ネットワーク帯域幅の需要が急増していること(AIの要求を考えてみて)や、CPUサイクルの25~50%が「インフラ」のニーズに消費されていることが、DPUへの移行を促していると述べている。
「データセンターのワークロードを分離して、より高い帯域幅の要求に対応するために加速する必要があります。この問題を解決するための素朴なアプローチは、アプリケーションプロセッサ上で実行されていたインフラストラクチャ処理要素を、ネットワークデバイスに組み込まれたプロセッサ上で実行することです(SmartNICsを考えてみてください)。この方法では、効率以外のパフォーマンスの向上は望めません。アイソレーションの問題は解決しますが、より高い帯域幅の要求には対応できませんし、CPUの消費電力が大きくなるため、システムを大幅に変更する必要があります。」とBursteinは述べている。
BlueField-3のスペックは、220億個のトランジスタ、初の400ギガビット/秒のネットワークチップ、16個のArm CPUを搭載し、例えばVMware ESXを動作させるなど、仮想化ソフトウェアスタック全体を動作させることができるという素晴らしいものだ。「BlueField-3では、IPsecとTLSの暗号化、秘密鍵の管理、正規表現の処理を完全にオフロードして高速化し、セキュリティを全く新しいレベルに引き上げました。我々は18ヶ月ごとにBlueFieldの新世代を導入するペースで進めています。BlueField-3は毎秒400ギガビットで、Bluefield-2の10倍の処理能力を持ち、BlueField-4は毎秒800ギガビットで、NvidiaのAIコンピューティング技術を加えることで、さらに10倍の処理能力を得ることができます。」と、4月のBlueField-3の発表時にNvidiaは報告している。
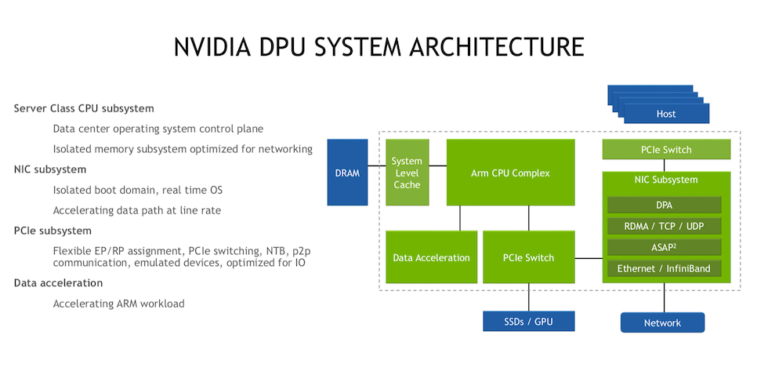 |

Bursteinは、「BlueFieldは複雑なシステムです。約400ギガビットのイーサネットとInfiniBandをパイプライン化し、暗号化とセキュリティのアクセラレーションを行っています。また、36レーンのPCIを搭載しています。毎秒370パケットの2倍、毎秒4000万パケットの2倍をサポートし、すべて数百万フローの規模に対応します。」
大まかに言えば、BlueFieldはクラウド・ネイティブなスーパーコンピューティング・アーキテクチャ戦略に不可欠であるとしている。同社は、Dell Technologies、Inspur、Lenovo、SupermicroがBlueField DPUを自社システムに統合していること、また、例えばBaidu、JD.com、UCloudなどの複数のクラウドプロバイダーがBlueField DPUを統合している、または統合する予定であることを報告している。このように、BlueField DPUを導入することで、より多くの人がBlueField DPUを利用するようになるだろう。
DOCA(Data Center Infrastructure-on-a-Chip Architecture)は、BlueFieldのためのNvidiaのプログラミングフレームワークである。「DOCAソフトウェアは、SDKとランタイム環境で構成されています。DOCA SDKは、ネットワークとセキュリティのためのDPDK(Data Plane Development Kit)とP4、ストレージのためのSPDK(Storage Performance Development Kit)など、業界標準のオープンAPIとフレームワークを提供します。これらのフレームワークは、統合されたNVIDIAアクセラレーション・パッケージにより、アプリケーションのオフロードを簡素化します。DOCAベースのサービスは、業界標準のI/Oインターフェースとしてコンピュートノードで公開され、インフラの仮想化と分離を可能にします。」
 |
Mount Evansに登る – IntelのIPUはクラウドを目指す
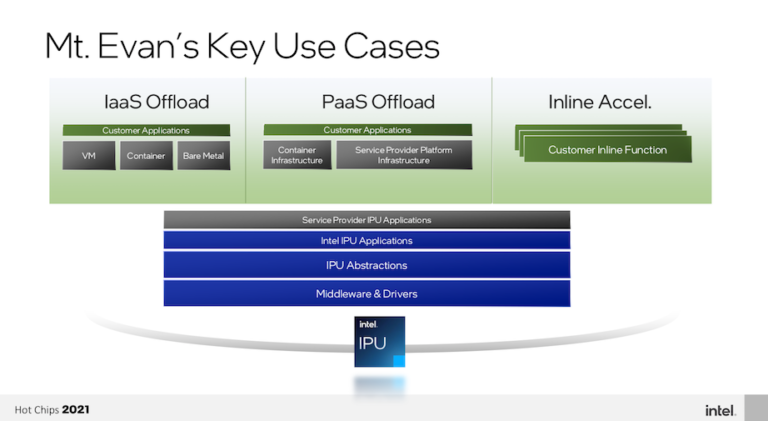
Burresは、Mount Evansの技術について大まかに語り、クラウド・プロバイダーが採用するケースを中心に説明した。
「まず、IPUによって、サービスプロバイダーとテナントの間で機能を分離することができます。これにより、すべての関係者がより高いセキュリティと分離を得ることができます。また、ベアメタル・ホスティングのような重要なユースケースでは、仮想マシンと同じサービスを使用して、同じハードウェア・プラットフォーム上で実行することができます。テナントは、自分のCPUを完全にコントロールすることができます。テナントは、独自のハイパーバイザーを実行することなどができます。その場合でも、ネットワーク、ストレージ、セキュリティなどのインフラ機能はIPU内に設置されているため、クラウド事業者が完全にコントロールすることができます。」とBurresは述べている。
「次に、IPUはインフラに最適化された実行環境を提供します。これには、IPUのハードウェアアクセラレータへの多大な投資が含まれており、IPUはインフラタスクを非常に効率的に処理することができます。これにより、この種のワークロードに対応するソフトウェアやコアのチューニングが可能になります。パフォーマンスが最適化され、クラウド事業者はゲストに100%のCPUを貸し出すことができるようになり、収益も最大化されます。最後に、IPUは、ストレージをテナントから抽象化することで、ストレージの新しいサービスモデルを実現することができます。」と述べている。
 |
Burresは、Mount Evansのプログラム可能なパケット処理機能は、おそらく最も素晴らしい機能であると主張している。この機能は、「vSwitchのオフロード、ファイアウォール、テレメトリ機能などのユースケースをサポートし、実際の実装では最大2億パケット/秒のパフォーマンスをサポートします。これは、完全な機能を備えた送信トラフィックシェーパによって強化されています。」 Mount Evansは、ネットワーク上で送信されるすべてのパケットを保護するインラインIPsecを提供し、最大1,600万のセキュアな接続をサポートしている。
「右側(下のブロック図)にある当社のコンピュートコンプレックスは、N1コアを使用したArm Neoverseアーキテクチャで構築されており、最大16コアが3GHzまで動作します。また、32メガバイトの大容量システムレベルキャッシュと、理論上毎秒102ギガバイトのメモリ帯域幅を実現する3つのデュアルモードLP DDR4コントローラを搭載しています。これらを組み合わせることで、より大規模な生産ワークロードに対応できる帯域幅と馬力を得ることができます。コンピュートコンプレックスはネットワークサブシステムと密接に連携しており、NSSアクセラレータはシステムレベルのキャッシュを自分のラストレベルキャッシュとして使用することができます。両者の間に高帯域低遅延の接続を提供するメッシュです。」と述べた。
 |
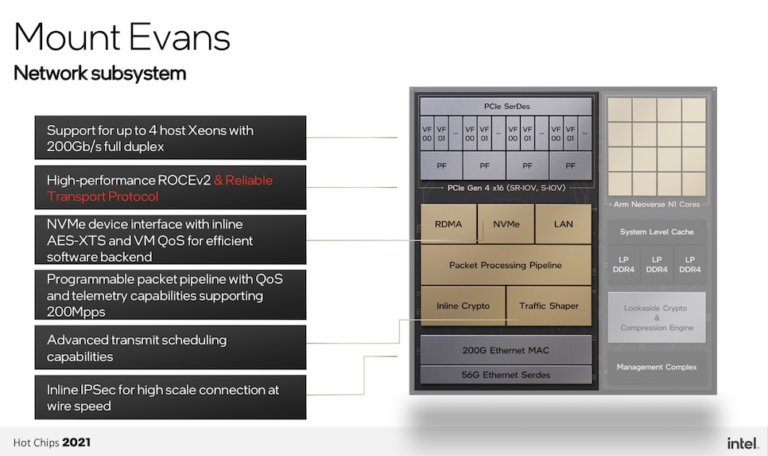 |
また、Burresは、新しいIntelIPUがゼロから設計されたものであることを強調し、Intelが既存のIPを単に接着しているだけであるというコメントを見て、それに応えたものであると述べた。Burresは、IAプロセッサコアではなくArmを選択したことについては、Intelの定期的な評価の一環として行われたということ以外、ほとんど語っていない。おそらく、Armの方が必要な電力が少ないことが要因となったのだろう。
IPUとDPUのどちらを採用するかは、今後2、3年のうちに実際に市場に投入され、その機能性(性能とコスト)が検証されることで明らかになるだろう。
アナリストたちは概してこのアイデアに好意的である。Cambrian AI Research社のプリンシパルであるKarl Freundは、HPCwireに対し次のように述べている。「このSmart NICS+の市場は、まだ始まったばかりです。初期の採用者は、ASIC(AWS)やFPGA(Microsoft)を使用するハイパースケーラーです。 しかし、Nvidiaは、IPUにArmコアとGPUを搭載した、より強力なものが必要になると予測しています。3年後には、非常に大規模なコンポーザブル・インフラのゲーム・チェンジャーになるかもしれません。」
特別イベント

寄稿者
![]() 西克也
西克也
西克也はフェアチャイルド社、クレイ・リサーチ社、ベストシステムズ社など、30年以上に渡ってHPCに関する仕事に従事している。Hpcwire Japanの編集長として記事の作成と翻訳を行っている。
![]() 島田佳代子
島田佳代子
1999年~2007年まで英国在住。2001年よりスポーツ、旅、ビジネス、映画など幅広いジャンルで執筆活動を開始し、Hpcwire Japanでは主に日本のHPC業界が世界に誇る研究者、開発者の方々のインタビューを担当。
![]() 小柳義夫
小柳義夫
小柳義夫氏は40年以上に亘ってHPCに携わってきた研究者であり、日本のHPC業界における生き字引として有名。現在 高度情報科学技術研究機構に所属し、産業界のHPC推進にあたっている。
![]() 小西史一
小西史一
小西史一は、理化学研究所、東京工業大学においてHPCおよびバイオインフォマティクスに関する研究と教育に携わってきた研究者。2012年からフォトグラファーとしての活動を開始し、現在はIT技術・セキュリティのコンサルティング業務に携わっている。