
HPCの歩み50年記事一覧

スパコンリスト日本

記事寄稿について

2021年11月 TOP500まとめ
Tiffany Trader & Katsuya Nishi
TOP500
第58回となるTOP500の発表はハイブリッド開催ではあるがセントルイスで開催されているSC21で行われた。10位以内の変化は1システムだけに留まっており、第10位にランクインマイクロソフトAzureのシステムだけで、残り9システムは前回のままで、日本の富岳が首位をキープしている。今回も名実ともとなるエクサスケールは登場しなかった。数年前の計画では今年までに米国は2台のエクサスケールシステムを登場させるはずだった。そのひとつで米国では初のエクサスケールシステムとなるAuroraは現在アルゴンヌ国立研究所でインストール中だ。
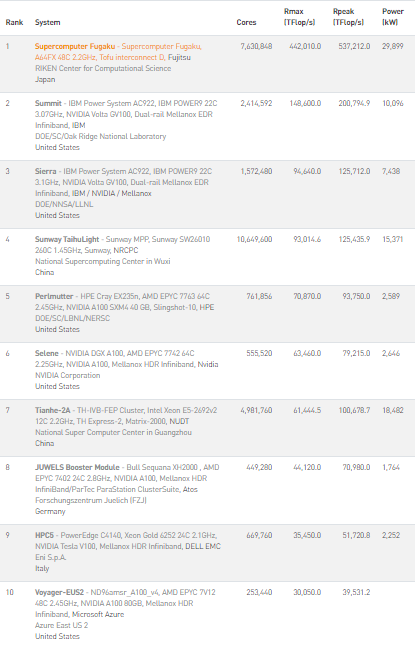 |
10位に入ったマイクロソフトAzureで構成されたVoyager-EUS2は、AMD Epyc Rome (48コア、2.45GHz)、Nvidia A100 80GBおよびHDR InfiniBandで構成されており、理論最大性能39.5ペタフロップスでLINPACK性能が30ペタフロップスだった。Linpackの効率はが76%と高いのは本システムがHDR InfiniBandを使用しているためである。Voyager-EUS2は、Azure East US 2リージョンで立ち上げられている。(このシステムは、今年の初めに詳細が発表されたVoyagerシステムとは関係ない)
また、HPEが2台の新製品を発表しランクインさせた。11位ランクインしたサムスン電子向けの「SSC-21」がそのひとつだ。このApollo 6500 Gen10 Plusシステムは、32コアのAMD Epyc Milan 7543 CPUを2.8GHzで動作させ、InfiniBand HDR200ネットワークを搭載している。SSC-21は、理論最大性能31.8ペタフロップス、Linpackで25.2ペタフロップスを達成し、効率は79%となった。同様のアーキテクチャを採用した2.27ペタフロップスの小型HPEシステム「SSC-21 Scalable Module」は、1ワットあたり33.98ギガフロップスのエネルギー効率を達成し、Green500の2位に選ばれている。
アルゴンヌ国立研究所のスーパーコンピュータ「Polaris」は12位にランクインしている。Polarisは、HPEのApollo 6500をベースに、第2世代のAMD Epyc Rome 7532 CPU(32コア、2.4GHz)を約560個、Nvidia A100 40GB SXM4 GPUを約2,240個搭載し、Slingshot 10ネットワークを装備している。ピーク時34.6ペタフロップスで、23.8ペタフロップスというHPLスコアを達成した(効率68.8%)。Polarisは、アルゴンヌが近々発表するエクサスケールシステム「Aurora」への橋渡しを行い、ラボに追加の計算能力を提供するとともに、ソフトウェアの準備を支援するものだ。アルゴンヌによると、このシステムは、第2世代のRome Epyc CPUを、より高性能なMilan Epyc CPUに交換することで、最終的に44ピークペタフロップスに達するとのことだ。
14位にランクインしたCEA-HFは、フランスのエネルギー原子委員会(CEA)に提供されたAtos社のBullSequana XH2000システムで、23.24Linpackペタフロップスを達成している。CEA-HFは、AMD社の第3世代Milan Epyc CPU(64コア、2.45GHz)で構成され、Atos社独自のBXI V2インターコネクトでネットワーク接続されている。
新たに19、36、40、43位にランクインしたのは、ロシアの4つのシステムだ。19位の「Chervonenkis」(21.5ペタフロップス)と36位の「Galushkin」(16.0ペタフロップス)は、IPE、Nvidia、Tyanの3社がロシアのインターネット企業YANDEXのために開発したシステムだ。これらのシステムには、2GHzで動作する64コアのAMD Rome EpycプロセッサとNvidia A100 80GB GPUが採用され、InfiniBandネットワークが実装されている。
ロシアの3台目のスーパーコンピュータ「Lyapunov」もYANDEX社向けに構築され、12.8 Linpackペタフロップスで40位にランクインした。Lyapunovは、Inspur社のNF5488A5サーバをベースに、64コアのAMD Rome Epycプロセッサ(2GHz動作)とNvidia A100 40GB GPUを搭載し、InfiniBandでネットワーク接続されている。このシステムは、中国の2つの組織によって製造されており、NUDTとInspurだ。
ロシアの4番目の新規参入者は、SberCloud(ロシアのスベルバンクグループが支援するクラウドプラットフォーム)向けに構築された「Christofari Neo」だ。この11.95ペタフロップスのシステムは43位に入っている。
AMDは、トップ500での地位を引き続き向上させており、トップ10のうち4つのマシンが搭載している。リスト全体では、Epyc Romeシステムが54台、Epyc Milanシステムが17台、Epyc Naplesシステムが2台となっている。合計73台のシステムを擁するAMDのシェアは、6月のリストから9.4%増の14.6%に拡大し、1年前に比べて3倍のシステムがリストに掲載されている。インテルは、Top500システムの81.4%のシェアを主張しており、6ヶ月前の86.4%から減少している。
Nvidiaは、今回のリストに掲載された14台のシステムの製造元であり、他の4台の製造にも共同で関わっている。Sierra(2位)、Chervonenkis(19位)、Lassen(26位)、Galushkin(36位)だ。
IBMのシステムも健在で、まだ7システムある。Summit (#2), Sierra (#3), Marconi-100 (#18), Lassen (#26), PANGEA III (#29), AiMOS (#57), Longhorn (#279)だ。
今回のTOP500には、新たに70のシステムがランクインした。中でも注目すべきは、435位にランクインした「NA-IT1」だ。1.68ペタフロップスのLinpackシステムは、2017年にCEOともう一人の従業員が詐欺罪で起訴された後、静かになっていた日本のスーパーコンピューティング企業PEZYの復帰を意味している。NA-IT1は、AMD 64コアのEpyc RomeプロセッサとPEZY-SC3独自のメニーコアチップの両方を搭載したZettaScaler3.0マシンで、ノードレベルではInfiniBand EDRで接続されている。
全500システムのLinpack性能の合計は3.06エクサフロップスで、6ヶ月前の2.79エクサフロップス、12ヶ月前の2.43エクサフロップスから上昇した。全体のLinpack効率は6ヶ月前の63.1%から63.5%とほぼ横ばいであるが、上位100セグメントのLinpack効率は6ヶ月前の70.7%から76.3%に上昇した。トップの「Fugaku」は、82.28%という健全な計算効率を実現している。
 |
| クレジット:Top500 |
第58回Top500へのランクインに必要なLinpackスコアの最小値は、半年前の1.51ペタフロップスから1.65ペタフロップスになった。また、トップ100セグメントのエントリーポイントは、前回のリストの4.13ペタフロップスに対して、4.85ペタフロップスに増加した。現在の500位のシステム(NA1、レノボ、1.65ペタフロップス)は、前回のランキングでは433位であった。
中国はどうなった?
お隣の中国はどうなっているのだろうか?本来であればプリエクサスケール規模のシステムが続々と登場してきても可笑しくない。しかし、一時のスパコン競争熱が冷めたのか、今回も新システムの登場は無かった。2015年11月にエントリ数が100を超え、ピークの2019年11月には228システムと米国の117システムの倍近くあったエントリが、今回では173システムまで減少した。また上位もSunway TaihuLightとTianhe-2Aで変わりがない。
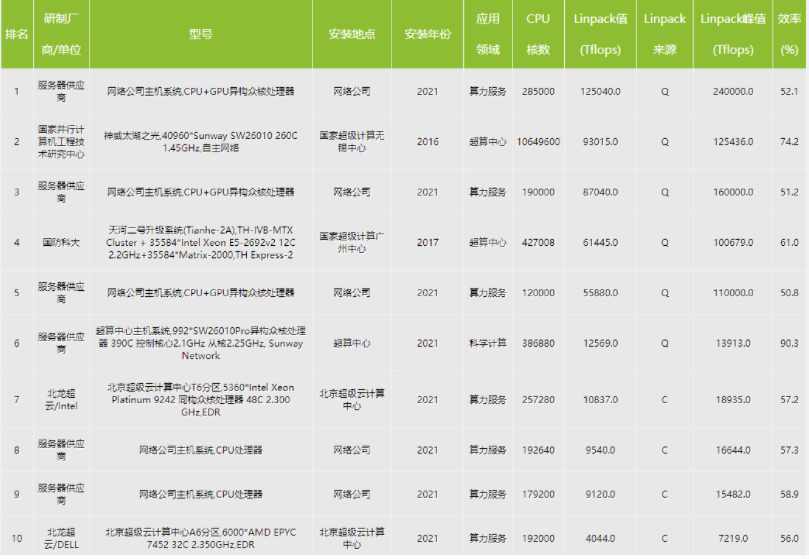
しかし、中国メディアcnbeta.comに掲載された11月12日にChinaSC 2021公表された中国のスパコンリストであるChina TOP100によると、TOP500で中国1位のSunway TaihuLightは中国のリストでは2位で、1位は会社名は不明だがネットワーク系の企業でLinpack性能が125ペタフロップスであった。この性能は米国のSierraを凌いでTOP500の3位に入る性能である。しかし、TOP500にはエントリしなかった。中国第3位のシステムも匿名ネットワーク企業でLinpack性能は87ペタフロップス。これもTOP500の第5位に入る性能だがエントリは無かった。中国のTOP10の中にはこのように匿名の企業が他にも第5位、第8位、第9位と合計で5システムもエントリしている。欧米でも日本でも元々企業はTOP500にエントリしないシステムが多いが、中国の場合には、China TOP100にはエントリしながら、TOP500にはしないというのは不思議だ。恐らく米国に配慮しているのかもしれない。
 |
日本は?
今回のリストでは日本は32システムがエントリしている。前回34システムだったので2システム減少した。今回の目玉は2システムあり、一つ目は301位にランクインしたPreferred NetworksのMN-3と435位にラインクインしたNA-IT1だ。
|
今回 順位 |
前回 順位 |
機関名 |
システム名 |
Linpack PFLOPS |
|
1 |
1 |
理化学研究所 |
富岳 |
442.010 |
|
16 |
12 |
産業技術総合研究所 |
ABCI 2.0 |
22.209 |
|
17 |
13 |
東京大学 |
Wisteria/BDEC-01(Odyssey) |
22.121 |
|
31 |
25 |
宇宙航空研究開発機構 |
TOKI-SORA |
16.592 |
|
39 |
32 |
JCAHPC |
Oakforest-PACS |
13.555 |
|
48 |
39 |
海洋研究開発機構 |
地球シミュレータ |
9.991 |
|
59 |
50 |
東京工業大学 |
TSUBAME3.0 |
8.125 |
|
63 |
54 |
核融合科学研究所 |
プラズマシミュレータ |
7.893 |
|
73 |
62 |
名古屋大学 |
不老 |
6.618 |
|
78 |
66 |
日本原子力研究開発機構 |
HPE SGI8600 |
6.162 |
|
79 |
67 |
大阪大学 |
SQUID |
6.105 |
|
86 |
74 |
気象庁 |
Cray XC50 |
5.731 |
|
87 |
75 |
気象庁 |
Cray XC50 |
5.731 |
|
98 |
85 |
名古屋大学 |
不老 Type IIサブシステム |
4.880 |
|
103 |
90 |
九州大学 |
ITO Subsystem A |
4.541 |
|
106 |
93 |
東京大学 |
Wisteria/BDEC-01(Aquarius) |
4.425 |
|
110 |
97 |
東京大学 |
Oakbridge-CX |
4.290 |
|
112 |
99 |
匿名研究所 |
Apollo 6500 |
4.128 |
|
122 |
108 |
さくらインターネット |
Apollo 6500 |
3.712 |
|
134 |
118 |
物性研究所 |
Ohtaka |
3.486 |
|
160 |
137 |
物質・材料研究機構 |
数値材料シミュレータ |
3.082 |
|
162 |
139 |
京都大学 |
Camphor 2 |
3.057 |
|
190 |
154 |
量子科学技術研究開発機構 |
JFRS-1 |
2.787 |
|
301 |
335 |
Preferred Networks |
MN-3 |
2.181 |
|
323 |
262 |
国立天文台 |
ATERUI II |
2.090 |
|
349 |
287 |
北海道大学 |
Grand Chariot |
2.000 |
|
350 |
288 |
富士通 |
A64FX prototype |
2.000 |
|
384 |
319 |
日本原子力研究開発機構 |
HPE SGI 8600 |
1.871 |
|
412 |
346 |
分子科学研究所 |
分子シミュレータ |
1.786 |
|
428 |
362 |
気象研究所 |
PRIMERGY CX2550 |
1.716 |
|
433 |
367 |
東北大学流体科学研究所 |
AFI-NITY |
1.691 |
|
435 |
新 |
NA Simulation |
NA-IT1 |
1.685 |
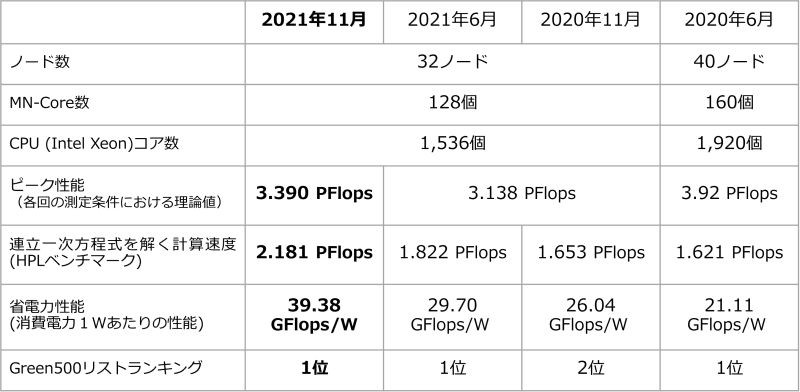
Preferred NetworksのMN-3は前回は335位であったのに対して今回は301位とランクアップしている。記録を見ると全体のコア数に変化はないが理論最大性能は前回の3.138ペタフロップスから3.390ペタフロップスと約8%向上しているのに対し、Linapck性能は前回の1.822ペタフロップスから2.181ペタフロップスと約2割向上している。今回の性能向上に関して同社はプレスリリースで次のように述べている。「MN-Coreは2020年5月の運用開始から同一のものを使用していますが、ソフトウェアによる制御のさらなる効率化、MN-Core同士を相互接続する専用インターコネクト(計算機ノード間を結ぶネットワーク)の改善などにより、前回(2021年6月)と比較して、計算能力が19.70%、電力効率が32.59%と飛躍的に向上しました。」 同社は前回に引き続きGreen500において首位を継続している。
 |
今回新たに加わった日本のシステムは435位にラインクインしたシステムだ。「NA-IT1」と名付けられたシステムは先に説明したようにPEZY Computing社とExascaler社が製造したシステムで、演算プロセッサにPEZY-SC3を採用し、ノード間通信はInfiniband EDRとなっている。理論最大性能は2.354ペタフロップス、Linpack性能では1.685ペタフロップスとなっている。PEZY-SC3はWikiChipによれば、コア数は8,192コアで動作周波数は1.3GHz、TSMCの7nmプロセスを使用しており、倍精度性能は21.845テラフロップスとされている。今回のシステムはアクセラレータコア数が819,200コアなので、PEZY-SC3を100台搭載していると考えられる。PEZY Computing社は有名なスキャンダル事件以降、静けさを保っていたが、昨年の後半からホームページでゲノム解析の高速化に関するニュースリリースを出している。
まとめ
今回も(?)日本の富岳が首位をキープしたことは日本国民にとっては嬉しいことだが、世界はそう甘くはない。来年からは続々と米国のエクサスケールシステムが登場してくる。日本では「富岳」の次のシステム検討に入っているが、まだまだ時間が掛かるだろう。何度も主張しているがスパコンは道具・手段であってゴールではない。スパコンを使って何ができるのか?何をやるのか?が一番重要だ。
特別イベント

寄稿者
![]() 西克也
西克也
西克也はフェアチャイルド社、クレイ・リサーチ社、ベストシステムズ社など、30年以上に渡ってHPCに関する仕事に従事している。Hpcwire Japanの編集長として記事の作成と翻訳を行っている。
![]() 島田佳代子
島田佳代子
1999年~2007年まで英国在住。2001年よりスポーツ、旅、ビジネス、映画など幅広いジャンルで執筆活動を開始し、Hpcwire Japanでは主に日本のHPC業界が世界に誇る研究者、開発者の方々のインタビューを担当。
![]() 小柳義夫
小柳義夫
小柳義夫氏は40年以上に亘ってHPCに携わってきた研究者であり、日本のHPC業界における生き字引として有名。現在 高度情報科学技術研究機構に所属し、産業界のHPC推進にあたっている。
![]() 小西史一
小西史一
小西史一は、理化学研究所、東京工業大学においてHPCおよびバイオインフォマティクスに関する研究と教育に携わってきた研究者。2012年からフォトグラファーとしての活動を開始し、現在はIT技術・セキュリティのコンサルティング業務に携わっている。