
HPCの歩み50年記事一覧

スパコンリスト日本

記事寄稿について

Graphcore、ウェハ・オン・ウェハの「Bow」IPUを発表
Oliver Peckham

Graphcoreは6年前にAIに特化したPCIeベースのIntelligent Processing Units(IPU)を発表した。それ以来、同社はペースを落とすことなく、2020年に第2世代のIPUを発表し、数年かけてIPUベースの「IPU-POD」システム、最近では数カ月前に発表したIPU-POD128、IPU-POD256とますます大型化させてきた。そして今、Graphcoreは(まさに文字通り)次のレベルへと進化し、2層ウェハ・オン・ウェハの第3世代IPUを発表した。「Bow」と呼ばれるこのプロセッサは、現在すでに出荷中だが、以前のものに比べて性能と電力効率が大幅に向上している。また、次世代IPUをベースにした巨大システムの計画も発表され、「Good computer」と名付けられている。
Bow、WoW
Bow IPUは、ロンドンの地区名にちなんで命名されたが、TSMCの7nmプロセスの新しいバリエーションで製造され、WoW(ウエハ・オン・ウエハ)パッケージが可能である。「ウェハ・オン・ウェハは、例えばAMDのMilan-Xのように、プロセッサの上にL3キャッシュを積み重ねるチップ・オン・ウェハの垂直スタッキングとは異なる技術です」と、Graphcoreの共同創設者兼CTO兼エンジニアリング担当執行副社長のSimon Knowlesは説明する。「ウェハ・オン・ウェハは、より洗練された技術で、互いに積み重ねられたダイ間の相互接続密度をより高くすることができます。その名の通り、ウェハーを切断する前に貼り合わせる技術です。つまり、2枚のウェハーを接続し、将来的には2枚以上のウェハーを接続し、それらを別々のシリコンチップに分割するのです。」
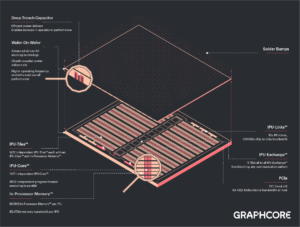 |
|
| クリックで表示:グラフコアのBow IPU用WoW構造の詳細図 画像はGraphcoreの提供 | |
Bowでは、GraphcoreとTSMCは、プロセッサ・ウェハに第2のウェハを取り付け、第2のウェハには、デバイスへの電力供給をよりスムーズにするディープトレンチ・コンデンサ・セルを大量に搭載し、その結果、プロセッサをより高速かつ高電圧で動作させることができるようにしたのである。「これは、私たちにとって最初のステップにすぎません」とKnowlesは言う。「私たちはTSMCと協力して、この技術を習得してきました。しかし、近い将来、この技術はそれ以上のものになるでしょう。」
Graphcoreは、TSMCを称賛し、TSMCは、Bow IPUについて、18ヶ月間、彼らと協力してきたという。Graphcoreは、ウエハ・オン・ウエハ技術を量産品として提供した最初の企業である。
電力供給の改善により、Bowは主要なAIワークロードにおいて、ローエンド(物体検出ワークロードの場合)の29%向上から、ハイエンド(各種NLPや画像分類ワークロードの場合)の39%向上まで、前モデルより最大40%の向上を誇っている。また、Bow IPUは電力効率も最大で16パーセント向上している。
 |
|
| Bow IPU。画像提供:Graphcore | |
Bowは、それ以外の点では、前世代のIPUと比較的よく似ている。「1GB近いスタティックRAMを搭載しているのは前世代と同じですが、アクセスが40%高速化されており、1GB近いオンチップメモリに65テラバイト/秒でアクセスできるようになっています」とKnowlesは述べている。「1,472個の独立したプロセッサ・コアを搭載し、それぞれが6つの独立したプログラムを実行することができます。そして最後に、チップ間を接続する10個のIPUリンクを備え、合計で毎秒320ギガバイトのチップ間帯域幅を実現しています。」
Bow IPUは、350ピークテラフロップスの混合精度AI演算、または87.5ピーク単精度のテラフロップスを提供する。Graphcoreは、これはNvidia A100の記載されたピーク(19.5ピークテラフロップスFP32)と紙面上で比較すると有利であると指摘しているが、実際の性能比較はもちろん興味深いところであろう。
IPUマシンとBow Pods
前世代のGraphcoreのIPUと同様に、BowはBow-2000 IPU Machinesに4倍搭載され、1.4ピークペタフロップスのAI演算(350ピークテラフロップスFP32)を提供する。Bow-2000は、Bow Pod16(4×Bow-2000, 1.4peak petaflops FP32)から、現在早期アクセス中の前例のないBow Pod1024(256×Bow-2000, 89.6peak petaflops FP32)まで、様々なサイズのBow Podsに搭載さ れることになる。( Graphcoreでは、Pod32、Pod64、Pod256の各サイズも提供している。)
Graphcoreの共同設立者兼CEOである Nigel Toonは、「これらの製品はすべて今日存在し、今日お客様に出荷しています」と語った。さらに、コストアップもないという。(「(従来の)システムのコストを下げるという選択肢もあるかもしれないが、まだその発表はしていない」)
Toonは、Bow Pod-16(同氏によれば小売価格は「15万ドル弱」)を、「30万ドル弱」で販売されているNvidia DGX A100と比較している。Bow Podは、効率的な画像分類モデルの学習に14時間かかったのに対し、Nvidiaのシステムでは17時間かかったという。「半分の値段のシステムで5倍速く訓練できる 」ということです。
 |
| Bow Pod16 画像提供:グラフコア |
これらすべてが、Graphcoreの先行製品に慣れた開発者にとってつらい調整なしに実現したとToonは言う。「コードの変更は一切ありません」と彼は断言した。「そのため、当社の既存モデルや、当社のPoplarソフトウェア環境を使って構築した顧客のモデルはすべて、箱から出してすぐにシームレスに動作します」。
そして、Graphcoreは、第3世代の製品について、印象的な顧客リストを作成した。Graphcoreによれば、このIPUを使用して、計算化学やサイバーセキュリティのためのトランスフォーマーベースおよびグラフニューラルネットワークモデルの開発を支援する予定だ。
PNNLのComputational and Theoretical Chemistry Instituteの共同ディレクターであるSutanay Choudhuryは、「Pacific Northwest National Laboratoryでは、機械学習とグラフニューラルネットワークの限界を押し広げ、既存の技術では困難であった科学的問題に取り組んでいます」と述べている。「例えば、計算化学やサイバーセキュリティの応用を追求しています。今年、Graphcoreシステムによって、これらのアプリケーションの学習と推論の両方の時間を数日から数時間にまで大幅に短縮することができました。このスピードアップにより、機械学習のツールを有意義に研究ミッションに取り入れることができるようになると期待されています。この最新世代の技術で共同研究を拡大することを楽しみにしています。」
その他の主要顧客には、サンディア国立研究所、インペリアル・カレッジ・ロンドン、マサチューセッツ大学アマースト校、オックスフォード大学、スタンフォード大学医学部などがあり、その多くは機密保持のため名前を挙げることができないと同社は述べている。
Goodコンピューター
しかし、Graphcoreはそれだけにとどまらない。「Graphcoreを始めたとき、”Intelligence Processing Unit “を作るという話をしました。つまり、人間の脳の能力を超える超知能マシンを作るというアイデアが常に頭の片隅にあったのです」–と、Knowlesは語った。
この劇的な目標のために何が必要なのか、正確にはわからないが、ある程度の推測はできるという。人間の脳には約1000億個の神経細胞と、数百兆個のシナプス重みを持つ軸索があるという。これに対して、現在最大のニューラルネットワークのモデルは、約1兆個のパラメータを持っている。
「つまり、人間の脳を明らかに超える情報量を持ち、超高知能AIを実現できる機械ができるまでには、明らかにあと2〜3桁の進歩が必要なのです」と述べている。「Graphcoreは、そのようなマシンを作ることを意図しており、実際、その道を進んでいます。」
「このマシンは、Bowプロセッサの1世代上の8,192個のIPUを含みますが、3Dウエハ・オン・ウエハ積層技術をさらに活用します」と述べ、マシンが「10エクサフロプス以上」の浮動小数点性能と4PBのメモリ、毎秒10PB以上のアクセス性を実現することを明らかにした。「これにより、何百兆ものパラメータを持つAIモデルのホスティングが可能になります。」 (グラフコアは具体的に500兆個のパラメータという目標を挙げている)
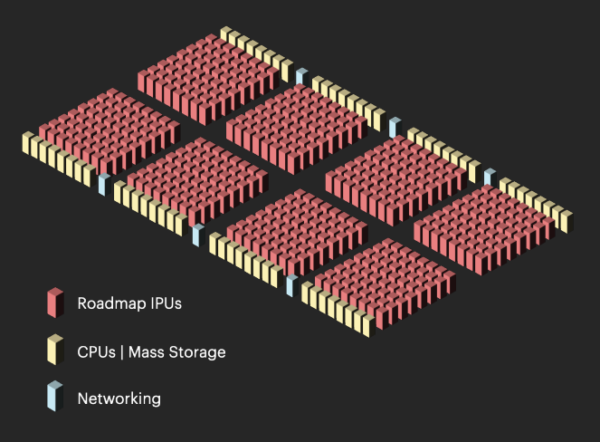 |
| Goodコンピュータの大まかな概要。画像はグラフコアの提供 |
Knowlesによると、Goodコンピュータは、「超知能コンピュータのコンセプト」を語った 1960年代のコンピュータ科学者、Jack Goodにちなんで命名されたという。彼らは、1億2,000万ドルと予想されるGoodコンピュータは、1台限りのシステムではなく、複数の顧客への販売を目的とした製品になることを明らかにした。
特別イベント

ISC 2026
6月 22 - 6月 26
International Conference for High Performance Computing, Networking, Storage & Analysis (SC26)
11月 15 - 11月 20
寄稿者
![]() 西克也
西克也
西克也はフェアチャイルド社、クレイ・リサーチ社、ベストシステムズ社など、30年以上に渡ってHPCに関する仕事に従事している。Hpcwire Japanの編集長として記事の作成と翻訳を行っている。
![]() 島田佳代子
島田佳代子
1999年~2007年まで英国在住。2001年よりスポーツ、旅、ビジネス、映画など幅広いジャンルで執筆活動を開始し、Hpcwire Japanでは主に日本のHPC業界が世界に誇る研究者、開発者の方々のインタビューを担当。
![]() 小柳義夫
小柳義夫
小柳義夫氏は40年以上に亘ってHPCに携わってきた研究者であり、日本のHPC業界における生き字引として有名。現在 高度情報科学技術研究機構に所属し、産業界のHPC推進にあたっている。
![]() 小西史一
小西史一
小西史一は、理化学研究所、東京工業大学においてHPCおよびバイオインフォマティクスに関する研究と教育に携わってきた研究者。2012年からフォトグラファーとしての活動を開始し、現在はIT技術・セキュリティのコンサルティング業務に携わっている。