
HPCの歩み50年記事一覧

スパコンリスト日本

記事寄稿について

Nvidiaの研究開発責任者が語る、AIによるチップ設計の改善
John Russell

Nvidiaの研究開発を垣間見ることは、春のGTCカンファレンスの恒例行事となっており、チーフサイエンティスト兼研究担当上級副社長のビル・ダリーは、Nvidiaの研究開発組織の概要と現在の優先事項に関するいくつかの詳細を説明した。今年は、Nvidiaが自社製品の改良のために自社で開発・使用しているAIツールに主に焦点を当て、逆セールスピッチのような形で説明した。例えば、NvidiaはGPU設計を効果的に改善し、高速化するためにAIを使い始めている。
 |
|
| 自宅の「作業場」にいるNvidiaのビル・ダリー | |
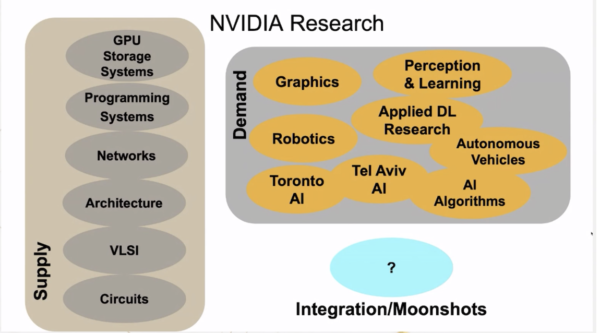
「我々は、Nvidiaの製品がどこにあるのか、先を見ようとする約300人のグループです」と、ダリーは今年の講演で説明している。「私たちは、遠くのものを照らそうとするハイビームのようなものです。私たちは、ゆるやかに2つの組織に分かれています。供給部門は、GPUに供給する技術を提供します。回路からVLSI設計手法、アーキテクチャネットワーク、プログラミングシステム、GPUやGPUシステムに入るストレージシステムに至るまで、GPUそのものをより良いものにします」という。
「Nvidiaの研究の需要側は、GPUがうまく動くために必要なソフトウェアシステムや技術を開発することで、Nvidia製品の需要を促進しようとするものです。我々は、3つの異なるグラフィックス研究グループを持っており、常にコンピュータグラフィックスの最先端を突き進んでいます。GPUを使ってAIを実行することは、現在、非常に重要なことであり、さらに大きくなっているからです。また、ロボット工学や自律走行車のグループもあります。また、トロントやテルアビブのAIラボのように、地理的にオーダーメイドのラボも多数あります」と語った。
Nvidiaは時折、複数のグループからなるMoonshotの取り組みを開始する。例えば、その1つがNvidiaのリアルタイムレイトレーシング技術の開発だ。
いつものように、ダリーの前年度の講演と重なる部分もあったが、新しい情報もあった。2019年には175人程度だった規模が、確実に拡大している。当然のことながら、自律走行システムやロボティクスを支える取り組みが活発化している。およそ1年前、Nvidiaはスタンフォード大学からマルコ・パヴォーネを採用し、新たに自律走行車の研究グループを率いることになったとダリーは言う。CPU設計の取り組みについては多くを語らなかったが、これも間違いなく活発化している。
 |
| ここでは、Nvidiaがチップの設計にAIを活用しつつあることについてのダリーのコメントの一部を(軽く編集して)、いくつかのサポートスライドとともに紹介する。 |
1 電圧降下のマッピング
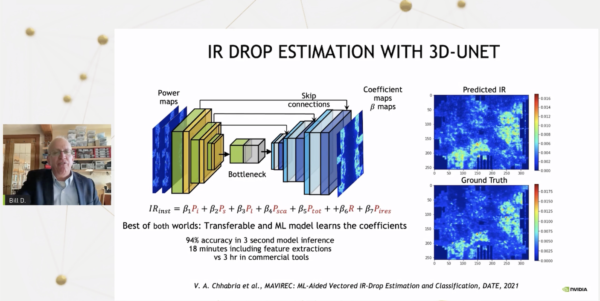
「AIの専門家として、そのAIを利用してより良いチップを設計したいと思うのは自然なことです。私たちはこれを2つの異なる方法で行っています。まず、最もわかりやすいのは、既存のコンピュータ支援設計ツールにAIを組み込む方法です。例えば、GPUで電力が使用されている場所のマップを取得し、電圧グリッドがどの程度低下するかを予測するツールがあります(電流×抵抗低下でIRドロップと呼ばれます)。これを従来のCADツールで実行すると3時間かかります」とダリー。
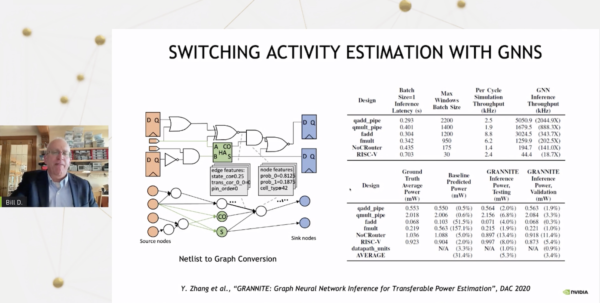
「繰り返しの作業なので、それが非常に問題になるのです。その代わり、同じデータをAIモデルに学習させ、多くの設計を行い、基本的にパワーマップを入力できるようにしたいと思います。その結果、推論にかかる時間はわずか3秒になりました。もちろん、特徴抽出の時間を含めると18分です。そして、非常に早く結果を出すことができます。この場合も同様で、畳み込みニューラルネットワークではなく、グラフニューラルネットワークを使用し、回路の異なるノードが切り替わる頻度を推定するためにこれを行い、これが実際に前の例への電力入力を駆動しています。そしてまた、従来のツールよりもはるかに速く、ほんのわずかな時間で、非常に正確な電力推定を行うことができるのです」とダリーは述べている。
 |
 |
2 寄生の予測
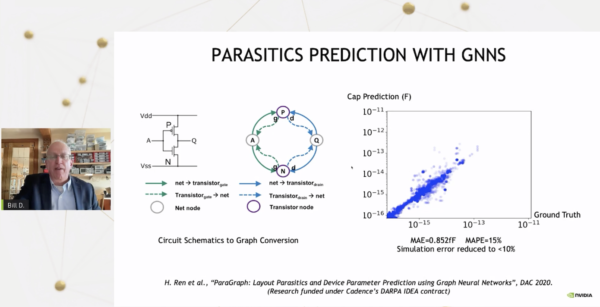
「数年前、回路設計者としてかなりの時間を費やした私が特に気に入っているのが、グラフ・ニューラル・ネットワークによる寄生の予測です。かつては、回路設計は非常に反復的なプロセスで、左の写真のような2つのトランジスタの回路図を描きました。しかし、レイアウト設計者がその回路図をもとにレイアウトを行い、寄生成分を抽出して、初めて回路シミュレーションを行い、仕様を満たしていないことがわかるのです」とダリーは指摘する。
「回路図を修正し、またレイアウト設計者に依頼するという、非常に長く、反復的で、非人間的な労働集約型のプロセスです。今、私たちができることは、ニューラルネットワークをトレーニングして、レイアウトを作成することなく、寄生素子がどうなるかを予測することです。そのため、回路設計者は、レイアウトという手作業の工程をループに入れることなく、非常に迅速に反復作業を行うことができます。このプロットは、グランド・トゥルースと比較して、寄生素子を非常に正確に予測できることを示しています。」
 |
3 配置と配線の課題
「これは、チップのレイアウトにおいて非常に重要です。通常のプロセスでは、ネットリストを作成し、配置配線プロセスを実行する必要がありますが、これにはかなりの時間がかかり、数日かかることもあります。そして、実際に混雑したときに初めて、最初の配置が適切でないことが判明します。このような赤い領域(下のスライド)を避けるためには、リファクタリングしてマクロを別の場所に配置する必要があります。その代わりに今できることは、場所とルートを実行することなく、これらのネットリストを使って、グラフ・ニューラル・ネットワークを使って、基本的に混雑が起こりそうな場所を予測し、かなり正確にすることができるようになりました。完璧ではありませんが、懸念されるエリアを示すことができ、それに基づいて行動することができます。」
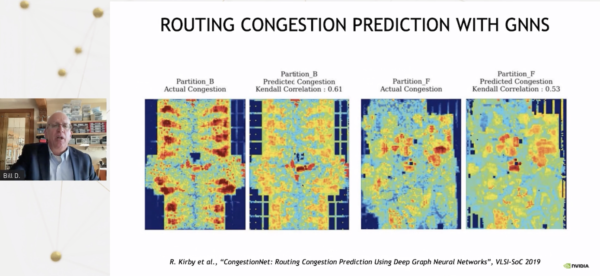 |
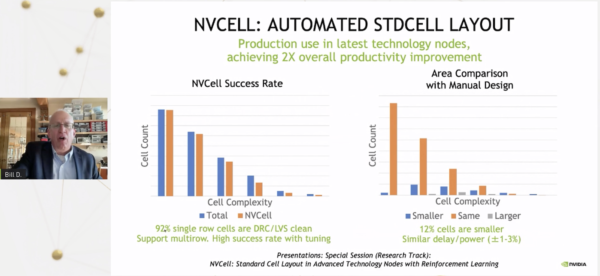
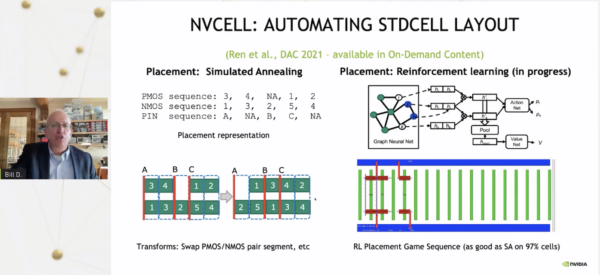
4 スタンダードセルの移動の自動化
「これらのアプローチは、人間が行った設計をAIで批評するようなものです。さらにエキサイティングなのは、AIを使って実際に設計を行うことです。その例を2つ挙げましょう。一つはNVCellと呼ばれるシステムで、シミュレーテッド・アニーリングと強化学習の組み合わせにより、基本的にスタンダードセルライブラリを設計します。新しい技術を導入するたびに、例えば7ナノメートル技術から5ナノメートル技術に移行する場合、セルのライブラリが必要になります。セルとは、ANDゲートやORゲート、加算器のようなものです。このセルを、新しい技術に対応させるために、非常に複雑な設計ルールで設計し直さなければならないのです」とダリーは言う。
「基本的には、強化学習を使ってトランジスタを配置します。しかし、もっと重要なのは、トランジスタを配置した後、設計ルールのエラーが続出し、まるでビデオゲームのような状態になることです。実は、これこそが強化学習の得意とするところです。素晴らしい例として、アタリのビデオゲームに強化学習を使っています。これはアタリのビデオゲームのようなものですが、スタンダードセルのデザインルールの誤りを修正するためのビデオゲームなのです。強化学習で設計ルールの誤りを修正していくことで、基本的にスタンダードセルの設計を完成させることができます。ご覧の通り(スライド)、92パーセントのセルライブラリは、このツールで設計ルールや電気的なルールのエラーを出さずに行うことができました。また、そのうちの12パーセントは人間の設計したセルよりも小さく、一般に、セルの複雑さに関しては、人間の設計したセルと同じかそれ以上の結果を出しています」と、彼は述べている。
「このツールは、私たちにとって2つのことを可能にします。1つは、大幅な省力化です。新しい技術ライブラリの移植には、10人程度のグループで1年の大半を費やしていました。それが、数台のGPUを数日間稼働させるだけで、移植が可能になったのです。そして、自動処理されなかった8パーセントのセルについては、人間が作業することができます。そして、多くの場合、より良い設計ができるようになります。つまり、省力化と人間より優れた設計ができるのです。」
 |
 |
この他にも、ダリーの話は、Nvidiaの様々な研究開発の取り組みを高速で駆け抜けるようなものだった。興味のある方は、HPCwireが過去2回のダリー氏のR&D講演(2019年、2021年)を取材しているので、製品に登場し始めるかもしれない仕事の裏側をご覧ください。NvidiaのR&Dは、原則として基礎科学よりも製品に重点を置いている。R&Dのミッションと組織に関する彼の説明はあまり変わっていませんが、トピックは異なっていることに注意してください。
特別イベント

寄稿者
![]() 西克也
西克也
西克也はフェアチャイルド社、クレイ・リサーチ社、ベストシステムズ社など、30年以上に渡ってHPCに関する仕事に従事している。Hpcwire Japanの編集長として記事の作成と翻訳を行っている。
![]() 島田佳代子
島田佳代子
1999年~2007年まで英国在住。2001年よりスポーツ、旅、ビジネス、映画など幅広いジャンルで執筆活動を開始し、Hpcwire Japanでは主に日本のHPC業界が世界に誇る研究者、開発者の方々のインタビューを担当。
![]() 小柳義夫
小柳義夫
小柳義夫氏は40年以上に亘ってHPCに携わってきた研究者であり、日本のHPC業界における生き字引として有名。現在 高度情報科学技術研究機構に所属し、産業界のHPC推進にあたっている。
![]() 小西史一
小西史一
小西史一は、理化学研究所、東京工業大学においてHPCおよびバイオインフォマティクスに関する研究と教育に携わってきた研究者。2012年からフォトグラファーとしての活動を開始し、現在はIT技術・セキュリティのコンサルティング業務に携わっている。