
HPCの歩み50年記事一覧

スパコンリスト日本

記事寄稿について

インテル、Sapphire RapidsおよびHPCに最適化されたMaxシリーズを正式発表
Tiffany Trader オリジナル記事

数々の延期を経て、インテルはIce Lakeの後継となる第4世代のIntel Xeon Scalableプロセッサ(コードネーム:Sapphire Rapids)を発表した。Intel 7ノード(旧10nm)で製造され、プロセッサあたり最大60個のGolden Coveコアと新しい専用アクセラレータコアを搭載したこのプラットフォームは、新しいアクセラレータを使用したターゲットワークロードにおいて、前世代に比べて平均1.53倍の性能向上と、ワットあたりの平均性能2.9倍の効率改善を実現していると、インテルは発表している。
この発表会は、グローバルなライブストリーミングによるウォッチパーティーとして開催され、最近改名されたMaxシリーズのCPUとGPUも参加し、これまでそれぞれ「Sapphire Rapids HBM」「Ponte Vecchio」と呼ばれていた。
Sapphire Rapidsファミリーは、Maxシリーズを含む10のセグメントに分類された52のSKU(図表参照)を含んでいる。このうち11製品は2ソケットパフォーマンス(8~56コア、150~350ワット)、7製品は2ソケットメインラインパフォーマンス(12~36コア、150~300ワット)、10製品は4ソケットおよび8ソケット(8~60コア、195~350ワット)、3製品はシングルソケット(8~32コア、125~250ワット)に最適化された製品となっている。また、クラウド、ネットワーク、ストレージ、メディアなどのワークロードに最適化されたSKUも用意されている。
“HPC 最適化” Xeon Max シリーズ SKU には、32 コア、40 コア、48 コア、52 コア、56 コア版がラインアップされている。これら5つの2ソケット製品の最高出力は350Wで、定価は32コアの9462が7,995ドルから、56コアの9480が12,980ドルとなっている。9480 Maxシリーズより高価なSKUは2つあり、60コアの8490Hは17,000ドル、48コアの8460Hは13,923ドルである。
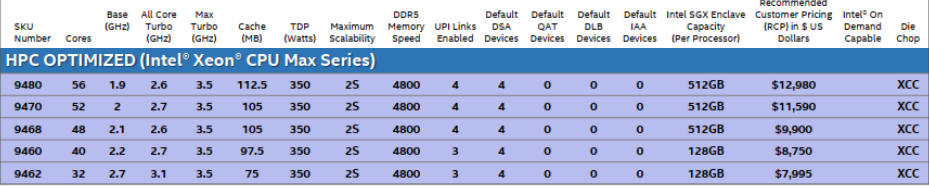 |
| Intel MaxシリーズCPUのSKU |
先月、オレゴン州ヒルズボロで開催されたプレスイベントで、インテルのシニアフェローであるロナック・シンハル氏は、SKUの幅の広さに言及し、次のように述べた。「顧客は、君たちはSKUが多すぎる、SKUの数を減らしてくれ、でも本当に本当に重要なこの3つのSKUを追加してくれないかと言うでしょう?このように、お客様と押し問答をしているのです。」
第4世代Intel Xeon Scalableプロセッサの新機能には、PCIe 5.0、DDR5メモリ、CXL 1.1のサポートなどがある。
 |
|
| 出典: インテル |
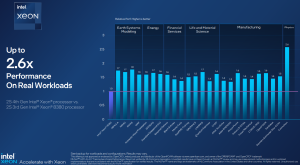
56コアの8480+トップオブビン2ソケット(非HBM)パーツは、Ice Lake対応製品よりも40%コアが多く、多くのベンチマークで世代を超えた性能向上を達成し、Stream Triadで1.5倍、HPLで1.4倍、HPCGで1.6倍の改善を実現している。WRF、ブラック・ショールズ、モンテカルロ、OpenFoamなど10数種類の実世界アプリケーションを対象としたインテルのテストでも同様の速度向上が見られ、物理ワークロードであるCosmoFlow(2.6倍)で最も大きな向上が見られたとのことだ。
 |
|
| MaxシリーズCPU(2022年12月オレゴン州ヒルズボロでのプレスイベントにて撮影) |
MaxシリーズCPUは、High Bandwidth Memoryを統合した初のx86プロセッサである。インテルによれば、メモリバウンドワークロードで3.7倍の性能向上を実現し、”導入済みの競合システム “と比較して68%のエネルギー消費を削減する。AlphaFold2アプリケーションにおいて、Xeon Max CPUはインテルのテストにおいてIce Lakeプロセッサの3倍のスピードアップを示した。HPCベンチマークウォッチャーにとって注目すべきは、Maxシリーズプロセッサが、DDRのみのSapphire Rapids相当と比較して、HPCGで約2.4倍、Stream Triadで3.5倍のスピードアップを達成したことだ。Max シリーズ CPU に搭載された HBM は、High Performance Linpack ベンチマークでは性能の向上が見られなかった。
 |
|
| MaxシリーズGPUの製品とフォームファクタ |
Maxシリーズの「Ponte Vecchio」GPUも発売され、47タイルのパッケージに1000億以上のトランジスタを搭載し、最大128個のXe HPCコアを搭載している。フォームファクターによっては、最大128GBのHBM2eメモリーをサポートし、最大52のピークFP64テラフロップスを実現する。MaxシリーズGPUとMaxシリーズCPUプラットフォームの組み合わせ(GPU:CPUが3対1の割合)により、LAMMPS分子力学ワークロードのパフォーマンスが、GPUなしのIce Lakeプラットフォームと比較して12.9倍に向上することが、インテルが行ったベンチマークにより確認されている。また、Max GPUの追加(2CPUのサーバーに6つのGPUを追加)により、同じワークロードでMaxシリーズのCPUのみのプラットフォームと比較して、9.9倍の性能向上を実現した。また、ホストCPUの広帯域メモリにより、DDR5のみを使用した場合と比較して、1.55倍の性能向上を実現している。(写真は先月オレゴン州ヒルズボロで行われたデモの様子)
Maxシリーズの両パーツは、当初Auroraスパコンでデビューする予定だったが、遅延のため、初期展開ではMaxシリーズの「Ponte Vecchio」GPUに加え、HBMではない「Sapphire Rapids」を使用している。HBM搭載のMaxシリーズCPUは、今後、ロスアラモス国立研究所に建設中のHPE製スーパーコンピュータ「Crossroads」でデビューする。同所の研究者らは、量産前のIntel Maxハードウェアが、LANLのIntel Broadwell世代のHPCシステムに対して、コードを変更せずに最大8.6倍の性能向上を実現したと報告している。LANL の HPC Platforms/Projects Program Director であるジム・ルージャン氏によれば,平均 4 倍の向上が見られたとのことだ。
MaxシリーズのCPU製品は、ローレンス・リバモア国立研究所とサンディア国立研究所のCTS-2システム、京都大学のスーパーコンピュータ「Camphor 3」にも採用されており、両プロジェクトのサーバーパートナーはDellが務めている。アルゼンチンでは、同国の国立気象局向けにLenovoのMax+Maxシステムを今春に導入する準備を進めているとのことだ。
 |
|
| Auroraシステムブレードアーキテクチャ(CPU:Sapphire Rapids 2個、GPU:Maxシリーズ6個) |
Max シリーズ CPU は、現在、アルゴンヌ国立研究所の Aurora のアップグレードパスの一部となっている。現在導入されているIntel/HPEシステムは、2万個のSapphire Rapids CPUと6万個のMaxシリーズGPUを搭載し、Intelが「exascale compute platform」または「ECP」と呼ぶフォームファクタになっている(Exascale Computing Projectを明確に意識したものだそうだ)。この研究所では、今年中にMax CPUのHBMパーツを交換する予定だ。このプロジェクトに詳しいIntelの担当者によれば、新しいCPUの実装には5,000時間かかるそうで、1ブレードあたり約30分(×10,000ブレード)かかると予想されているそうだ。
2エクサフロップスを超えるAuroraシステムの技術を評価し、デバッグするためのテストベッドが、オレゴン州ヒルズボロにあるJones Farmのサイトに設置されている。Borealisと呼ばれるこのシステムは、2ラック、128ブレードのシステムで、もう1ラック、64ブレードのシステムもあり、さらなるテストが可能になっている。BorealisにはSunspotという双子のシステムがあり、Argonneに設置され運用されている。Sunspotは、今年アルゴンヌで発表される予定のスーパーコンピュータ「Aurora」の試験・開発用システムである。インテルは現在、BorealisにMaxシリーズのCPUを搭載してアップデートしている。
 |
| オレゴン州ヒルズボロにあるIntel社のHPCラボにあるBorealisシステム。出典:インテル |
内蔵型アクセラレータと新しいライセンスオプション
Sapphire Rapidsでは、(2016年にXeon Phi「Knights Landing」製品でデビューしたAVX-512に加え)新たに4つの専用アクセラレータを導入している。
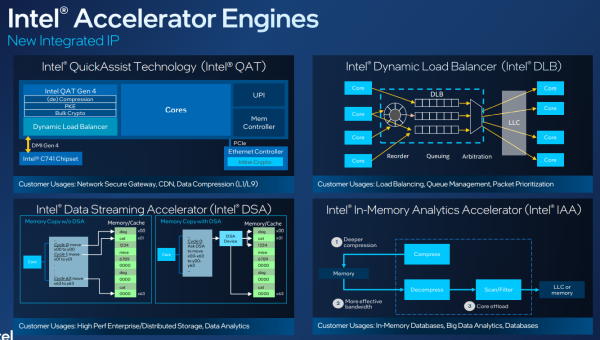
Intel Advanced Matrix Extensions(Intel AMX)は、自然言語処理(NLP)、推薦システム、画像認識などの深層学習(DL)推論およびトレーニングワークロードを加速さ せるものである。
インテル® データ・ストリーミング・アクセラレータ(インテル® DSA)は、ストリーミング・データの移動と変換処理を改善することにより、ストレージ、ネットワーキング、およびデータ集約型ワークロードのパフォーマンスを向上させることができる。
インテル・インメモリー・アナリティクス・アクセラレーター(インテルIAA)は、CPUコアからタスクをオフロードしながら分析性能を向上させ、データベース・クエリー・スループットとその他のワークロードを加速させる。
Intel Dynamic Load Balancer (Intel DLB)は、システム負荷の変化に応じて複数のCPUコアにネットワークデータを動的に分散させることにより、効率的なハードウェアベースのロードバランシングを提供する。
 |
 |
Intel On Demand(旧称:Software-Defined Silicon、SDSi)と呼ばれる新しいサービスでは、購入後にこれらのアクセラレータの一部をオンにしたりアップグレードしたりするオプションが提供さ れる予定だ。インテルは、「オンデマンドにより、エンドユーザーは、フル機能のプレミアムSKUを選択したり、Xeonプロセッサーのライフサイクルを通じていつでも機能を追加したりする柔軟性を得ることができます」と述べている。価格はライセンスモデルによって異なる。オンデマンドは現在、以下の機能に適用さ れる。インテル・ダイナミック・ロードバランサー、インテル・データ・ストリーミング・アクセラレーター、インテル・インメモリアクセラレーター、インテル・クイックアシストテクノロジー、インテル・ソフトウェアガード・エクステンション。MaxシリーズCPUおよびソケットスケーラブル(-Hタグ付き)SKUには、オンデマンド機能はない。また、8コアのシングルソケット品(3408U)にもオンデマンド機能はない。
Sapphire Rapidsのエコシステムパートナーには、AWS、Cisco、Dell Technologies、富士通、Google Cloud、HPE、IBM Cloud、Inspur、Lenovo、Microsoft Azure、Nvidia、Oracle、Supermicro、VMware、その他が含まれている。インテルによると、30以上のMaxシリーズCPUシステムデザインが市場に投入され、MaxシリーズGPUをベースにした15のシステムデザインも開発中である。
特別イベント

寄稿者
![]() 西克也
西克也
西克也はフェアチャイルド社、クレイ・リサーチ社、ベストシステムズ社など、30年以上に渡ってHPCに関する仕事に従事している。Hpcwire Japanの編集長として記事の作成と翻訳を行っている。
![]() 島田佳代子
島田佳代子
1999年~2007年まで英国在住。2001年よりスポーツ、旅、ビジネス、映画など幅広いジャンルで執筆活動を開始し、Hpcwire Japanでは主に日本のHPC業界が世界に誇る研究者、開発者の方々のインタビューを担当。
![]() 小柳義夫
小柳義夫
小柳義夫氏は40年以上に亘ってHPCに携わってきた研究者であり、日本のHPC業界における生き字引として有名。現在 高度情報科学技術研究機構に所属し、産業界のHPC推進にあたっている。
![]() 小西史一
小西史一
小西史一は、理化学研究所、東京工業大学においてHPCおよびバイオインフォマティクスに関する研究と教育に携わってきた研究者。2012年からフォトグラファーとしての活動を開始し、現在はIT技術・セキュリティのコンサルティング業務に携わっている。