
HPCの歩み50年記事一覧

スパコンリスト日本

記事寄稿について

Top500: Frontierが92ペタフロップスを獲得し、Henriが少しグリーンに
Tiffany Trader オリジナル記事

ホメオスタシスとまではいかないが、近いものがある。ドイツ・ハンブルグで開催された国際スーパーコンピューティング会議(ISC)から本日発表された最新のTop500には、ほとんど動きがなかった。第61回のリストでは、トップ10に新しいシステムはなく、トップ50の集団の中に新しいシステムは3つしかなかった(それぞれ11位と14位にMicrosoft AzureとNvidiaのシステムが含まれている)ため、ほとんど変化がなかった。ここでは、これらのシステムについて詳しく説明し、2つの興味深いシステムのスピードアップ(FrontierとLUMI)を紹介し、Green500のランキングを含むその他のリストの傾向について説明する。
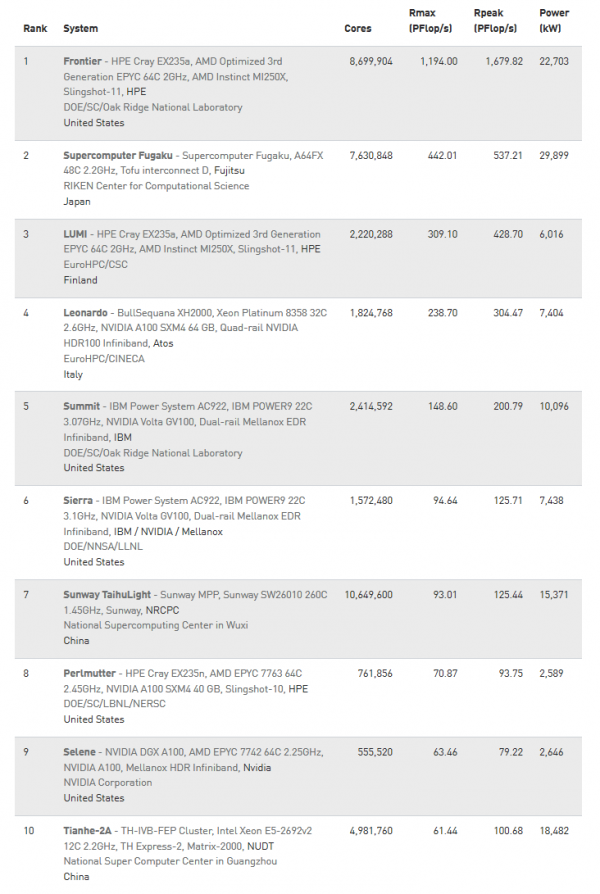
3度目の首位は、DOEのオークリッジ国立研究所がホストする、最初の「公式」エクサスケールシステムであるFrontierだ。HPE-AMDのシステムは、2022年11月のリストの1.102 Linpack exaflopsから、新しいリストの1.194 Linpack exaflopsへと、8.35%flopsがアップしている。これは92ペタフロップスの増加である。興味深いことに、このマシンのTop500構成のRpeakは、1.686エクサフロップスから1.680エクサフロップスへと、0.6%減少し、実際にわずかに減少している。このため、Linpackの向上はより印象的なものとなった。ORNLがFrontierを最適化した結果、Linpackの効率は以前の65.3%から71.1%に向上した。また、チューンナップされた新しい構成は、消費電力がわずかに増加しただけであり(前回のリストでは21.1MWに対して22.7MW)、Green500の指標も向上した(1ワットあたり52.23ギガフロップスに対して52.59ギガフループス)。
このリストに含まれていないのは、(すでに多くの人が予想していたように)Auroraスーパーコンピュータである。私たちは、アルゴンヌ国立研究所のシステムが、新マシンのLinpackの実行結果を提出するまでに「まともな」実行を達成したとしても(はっきり言って、達成したかどうかについての内部情報はない)、Auroraが「2エクサフロップス以上のピーク」を約束しており、Frontierよりも25〜50%大きいことを想定しているので、アルゴンヌとしては、Frontierの実行結果を超えられないのではリストに提出したくないのだろうと推測している。(なお、Auroraは長い運用期間を持ち、一時は米国初のエクサスケールシステムとなる予定だった)。この2つのマシンの相対的な大きさの違いについては、Dell HPC Communityのウェビナーシリーズの一環として行われた、アルゴンヌのリック・スティーブン氏の最近のプレゼンテーションがヒントになっている。スティーブン氏によると、Frontierは年間約7800万クアッドGPUノード時間を提供し、Auroraは年間約1億1800万クアッドGPUノード時間を提供するとのことだ。このことから、AuroraはTennesseeと比較して約50%大きくなることがわかる。Auroraについては、今日、Intel HPCチーフのジェフ・マクベイ氏が基調講演を行った後、さらに詳しく報告することになるだろう。
Frontierに関するもう一つの疑問は、正式な検収を経たのかどうかということだ。エクサスケールのシェイクアウトとブレークインが複雑なため、検収がやや遅れたという噂があったが、検収を通過したのではないかという話もある。オークリッジに問い合わせたところ、近日中に確認が取れるとのことだ。
 |
|
| 2023年5月Top500リスト 出典: Top500 | |
次に、イタリア・ボローニャのCINECAがホストするEuroHPCのLeonardoシステムに注目する。このAtos(Eviden)のBullSequana XH2000システムは、32コアのIntel CPUとNvidia A100 GPUを搭載し、6ヶ月前の174.7 Linpackペタフロップスから、現在238.7 Linpackペタフロップスを実現 している。演算量が36.6%増加し、Leonardoがフル構成になったにもかかわらず、3位をキープしている。2位をキープしている富士通が開発した「富岳」の309.1Linpackペタフロップスを上回ることはできなかった。
「富岳」といえば、3年前(2020年6月)に1位になって以来、HPCG(High Performance Conjugate Gradients)のチャンピオンに君臨している日本のマシンである。11月には、Frontierが14.05ペタフロップス(HPCGの中でも特筆される難易度)という素晴らしい結果を残している。しかし、「富岳」はこのベンチマークで16.00ペタフロップスを達成し、首位を維持している。このベンチマークにおけるFraction-of-Rpeak効率は0.08%(「Frontier」)、2.98%(「富岳」)である。次に高いHPCGスコアは、CSCのLUMIが提出した3.4ペタフロップスで、ピークに対する割合は0.08%だ。(低スコアにもかかわらず、このベンチマークに参加したすべての人に賞賛を送ります)。HPCGは、Linpackのコンパニオンベンチマークとして、「重要なアプリケーションの異なる幅広いセットにより近い計算とデータアクセスのパターンを行使するように設計されている」と、その後援者は述べている。)
この2点を除き、トップ10の顔ぶれそのものは変わっていない(上図右参照)。代表的な国は、米国、日本、フィンランド、イタリア、中国。メーカーは、HPE、富士通、HPE、Atos(Eviden)、Sunway、Nvidia、IBM、そして中国政府機関のNRCPCとNUDTが含まれている。中国といえば、ゴードン・ベル賞で2台のエクサスケールマシンが公開されたものの、Top500には掲載されなかったため、中国からは新たな大規模システムの発表はない。
新しいシステム
新システムは43件掲載されている。トップ50のグループ分けに登場するのは3つだけだ。Microsoft AzureのExplorer-WUS3は11位にランクインしている。そして、NvidiaのEos、いや「Pre-Eos 128 Node DGX SuperPOD」は14位にランクインしている。次にランクインしたのは、50位と51位にランクインした富士通の無名機です。この最初のコホートでは、NCARのDerecho CPUパーティション(59位、10.3 Linpackペタフロップス)、PetrobrasのGaia(93位、7.0 Linpackペタフロップス)、NCARのDerecho GPUパーティション(#130, 4.7 petaflops)、AtosのBerzelius2(#147, 4.2 petaflops)、筑波大のPegasus(#190, 3.5 petaflops)などが注目されている。
Microsoft Azureの新システムExplorer-WUS3は、AMD第2世代(Rome)Epyc 7V12 48コアCPUとAMD Instinct MI250X GPUを搭載したND96_amsr_MI200_v4仮想マシン(AzureのNDv4シリーズ仮想マシンのMI200バージョン)上で動作する。AzureのサーバーはOAM(OCPアクセラレータモジュール)のフォームファクターを利用しているのに対し、Frontierはカスタムボードを採用している点を除けば、ハードウェアの設計はFrontierと同様である。このクラスタは、AzureのWest US3データセンターでスピンアップされ、Microsoftは、実際のHPCおよびAIワークロードを実行した、または実行する予定の恒久システムであることを確認している。Explorer-WUS3は、理論ピーク86.99ペタフロップスのうち、53.96Linpackペタフロップスを達成し、Linpack効率は62%になりました。マイクロソフトがTop500リストで最高位の新規エントリーを提供するのは今回が2度目で、前回は2021年11月に10位のシステムを提供している。
Nvidiaの新しい「Pre-Eos 128 Node DGX SuperPOD」は、Nvidiaが最新のGTCプロシーディングスでEosについて特筆されたように沈黙していたため、我々がその情報を得るのを待ち望んでいたものである。Intel製CPUとNvidia H100GPUを搭載し、NvidiaのConnectX-7 NDR 400G InfiniBandファブリックでネットワーク化されたSuperPod統合Nvidia DGX H100システムを使って、潜在的Rpeak 58.05 (Linpack efficiency 70.0%) に対して40.66 Linpack petaflopsが集約されているのが、Eosフルシステムの前触れのように見える。
 |
|
| Eosのシステムレンダリング Nvidia提供 | |
Nvidiaは、14カ月前の春のGTC 2022で、ギリシャ神話の夜明けの女神の名を冠したEosシステムを発表した。Eosは、Nvidia独自の高速NVLinkインターコネクトを使用して8つのGPUをフックする第4世代DGXシステム(DGX H100)をベースにしている。Eosは、完全な構成では、18個の32-DGX H100 Pods、合計576個のDGX H100システム、4608個のH100 GPU、500個のQuantum-2 InfiniBandスイッチ、360個のNVLinkスイッチを搭載している。
現在、31~127台のDGX H100システムを、NVLinkスイッチを使ってSuperPod(Nvidiaの言い回し)にまとめることができる。127ノードと128ノードの間の不一致については、Nvidiaからの回答を待っているところだ。Nvidiaの製品仕様書(2023年5月発行)は、「NVIDIA Unified Fabric Manager(UFM)アプライアンスのペアは、DGX SuperPODの展開パターンで1つのDGX H100システムを置き換えるため、フルDGX SuperPODあたり最大127台のDGX H100システムを実現します」と記している。完全に構成され、配置された127ノードのSuperPodは、ピークFP8コンピューティングの3.2エクサフロップス、ピークトラディショナルFP64ペタフロップス、またはピークFP64テンソルコアペタフロップスの68.1ペタフロップスをもたらす。
Eosは、ギリシャ神話の月の女神の名を冠し、Eosの妹であるSeleneの後継機として企画された。Seleneは2020年6月にTop500の7位でデビューし、現在は9位にランクインしている。DGX A100の280台で構成されるこのシステムは、Rpeak 79.22ペタフロップスのうち63.46ペタフロップスを実現し、Linpack効率に換算すると80.1%になる。[注:NvidiaのRpeakは、マーケティングピークとは異なる構成になっている。]
Green500のハイライト
Green500は、Top500と同様に横ばいで推移している。NvidiaのH100 GPUを搭載したFlatiron InstituteのHenriシステム(このシステムは、昨年11月にチップのリストデビューを果たした)が、その座を維持した。Henriの効率は65.09ギガフロップス/ワットから65.40ギガフロップス/ワットへとわずかに向上したが、興味深いことに、ピークペタフロップスは減少(ピーク5.42からピーク3.58)し、リンパックぺタフロップスは増加(リンパック2.04からリンパック2.89)した。これは、Linpackの効率が37.62%から80.52%へと2倍以上になったことに相当する。Henriが初めてリストに載ったときにも、これくらいの効率の向上が見られると予測されていた。
前述のとおり、Frontierも52.59ギガフロップス/ワットから52.23ギガフロップス/ワットへと、ほんの少し増している。
Green500のトップ10には、こうした効率性の向上とは別に、いくつかの新しい項目が含まれている。8位は、デュイスブルグ・エッセン大学(UDE)のamplitUDEシステムのGPUパーティションで、1ワットあたり51.34ギガフロップス。1.95LinpackペタフロップスのamplitUDEは、Intel Xeon CPUとNvidia H100 GPUをベースにしているが、483位でTop500のリストに入った。amplitUDEのすぐ後、9位にランクインしたのはフランクフルト大学のGoethe-NHRだ。AMD Epyc CPUとAMD Instinct MI210 GPUをベースにしたGoethe-NHRは、46.52ギガフロップス/ワットを実現し、9.09 LinpackペタフロップスでTop500リストの70位にランクされている。前回上位にランクインしたMN-3は、今回11位となり、トップ10からは外れた。
トップ10はすべてアクセラレーションによるもので、これまで5回にわたって発表されてきたとおりだ。今回のリストでは、AMDが7つ、Nvidiaが3つアクセラレーションされている。トップ10のうち8つが50ギガフロップス/ワットを超える性能を発揮しており、これは20メガワット以下でエクサフロップを実現することになり、これまで非現実的とされていた閾値に相当する。
Top500の追加動向
リストのエントリーポイントは1.87ペタフロップス(半年前の1.73ペタフロップスから上昇)となり、現在500位のシステムは前回(2022年11月)のリストでは456位を保持しており、その詳細はSC in Dallasで発表されている。第61回Top500リストの全500システムが提供するLinpack性能の合計は5.24エクサフロップスで、半年前の4.86エクサフロップス、12ヶ月前の4.40エクサフロップスから上昇した。
Top100セグメントのエントリーポイントは、6.31ペタフロップスとなり、半年前の5.78ペタフロップス、1年前の5.39ペタフロップスから増加した。上位100システムのLinpack性能は、5.66理論エクサフロップスのうち4.07エクサフロップスで、Linpack効率は71.88%であった。上位10システムのLinpack効率は73.88%とやや高く、リスト全体のLinpack効率は66.94%となっている。
特別イベント

寄稿者
![]() 西克也
西克也
西克也はフェアチャイルド社、クレイ・リサーチ社、ベストシステムズ社など、30年以上に渡ってHPCに関する仕事に従事している。Hpcwire Japanの編集長として記事の作成と翻訳を行っている。
![]() 島田佳代子
島田佳代子
1999年~2007年まで英国在住。2001年よりスポーツ、旅、ビジネス、映画など幅広いジャンルで執筆活動を開始し、Hpcwire Japanでは主に日本のHPC業界が世界に誇る研究者、開発者の方々のインタビューを担当。
![]() 小柳義夫
小柳義夫
小柳義夫氏は40年以上に亘ってHPCに携わってきた研究者であり、日本のHPC業界における生き字引として有名。現在 高度情報科学技術研究機構に所属し、産業界のHPC推進にあたっている。
![]() 小西史一
小西史一
小西史一は、理化学研究所、東京工業大学においてHPCおよびバイオインフォマティクスに関する研究と教育に携わってきた研究者。2012年からフォトグラファーとしての活動を開始し、現在はIT技術・セキュリティのコンサルティング業務に携わっている。