
HPCの歩み50年記事一覧

スパコンリスト日本

記事寄稿について

DGX-2で実現する、リアルタイム風況解析への流れ
|
|
|
|
日本原子力研究開発機構 井戸村泰宏氏(左)と小野寺直幸氏(右) |
|

国立研究開発法人日本原子力研究開発機構(JAEA)システム計算科学センター高度計算機技術開発室の小野寺直幸氏、井戸村泰宏氏に、現在研究を進めている高精度な汚染物質拡散解析予測のリアルタイム計算を可能にする風況解析プログラムの開発の意義と、その実現を可能とした技術について話を伺った。
JAEAでは、数キロメートル四方の空間を数メートル解像度で計算する高解像度風況解析と環境モニタリングで得られる観測データを同化させる融合解析により、複数の観測・計算データを横断的に活用する汚染物質拡散解析手法の研究を行っている。
この分野のシステムは緊急時の避難計画策定のために即時利用する事を想定しているため、実際に事象が進行する時間(リアルタイム)よりも速い時間でシミュレーションを実行する事が必要とされており、HPCの技術的貢献が期待される分野として知られている。
開発プログラムはCityLBMコードと名付けられており、小野寺氏が東京工業大学在籍時に開発した風況解析プログラムをベースとして、これまでリアルタイム計算に向けた計算手法の改良が進められてきた。
このプログラムの特徴として、GPUに適した格子ボルツマン法(LBM: Lattice Boltzmann Method)と呼ばれる流体計算モデルの高効率な実装、および、乱流の風況解析に適した計算モデルの採用が挙げられ、2012年には約4,000台のTesla K20X GPUを搭載したTSUBAME2.5スーパーコンピュータ上で500億格子(東京都心部において10キロメートル四方、1メートル解像度)の風況解析を実現するなど、都市気流の解析に関して画期的な成果を上げている。
しかしながら、このような大規模風況解析を行うには大規模なメモリ空間が必要となり、100GPU以上が必要となることから、緊急時対応のリアルタイムシミュレーションとして用いるには計算機資源の規模と運用面での課題が多い。
このような課題を解決して比較的小規模なシステムでリアルタイムシミュレーションを実現するには、計算手法の工夫によって計算規模を削減することが不可欠だった。
そこで、地表面付近の人の生活に関わる建築物や道路などの構造物がある場所では、構造物によって発達する細かい流れを捉えるために計算格子を細分化し、比較的流れのスケールが大きい上空では粗い格子を用いるといった格子解像度の変更が可能な適合細分化格子(AMR: Adaptive Mesh Refinement)法を採用した。
これにより従来の一様格子の計算に比べて必要なメモリサイズなどの計算機資源を10分の1以下に削減し、さらにLBMの計算で必要となるGPU間の通信処理を削減する通信アルゴリズムを開発することで、4キロメートル四方、2メートル解像度のリアルタイム汚染物質拡散解析を1ノードのNVIDIA DGX-2において実現することができた。以下の図は米国オクラホマシティで実施された汚染物質拡散実験の解析例を示す。
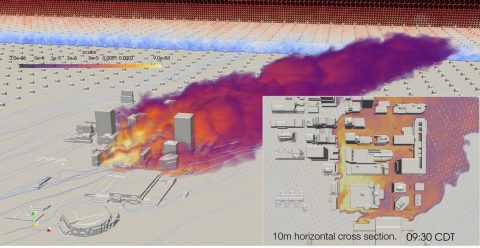 |
このリアルタイムシミュレーションにおけるDGX-2の役割は大きく、32GBメモリを搭載したTesla V100 GPU16基が1つの筐体に実装され、それらが非常に高速なNVSwitchにより完全相互結合されたシステム構成をとることで、実用上必要となる問題規模を1ノードに載せる事が可能となり、これにより従来の100GPU程度の処理で5割以上を占めていたノード間通信のボトルネックが解決し、16GPUで実時間まで計算を加速することが可能となった。
 |
|
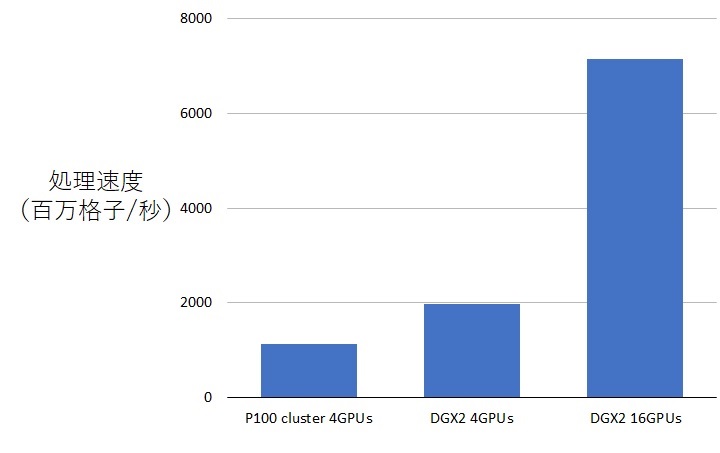
具体的な性能比較(上図)でも、Tesla P100 GPUを搭載したReedbushクラスタにおける4GPUでの計算時間と比べると、DGX-2では4GPUで1.73倍の高速化が実現されており、全16GPUを使った場合には6.27倍もの高速化が実現している。
この処理速度向上によりリアルタイム汚染物質拡散解析が1台のDGX-2で完結できた事は、応用面でも新たな可能性をもたらすと期待される。例えば、解析に必要となる計算機資源がこれまでの大規模なスーパーコンピュータから1ノードの計算機にサイズダウンしたことで、原子力サイトに汚染物質拡散解析専用の計算機を設置して、各サイトの環境モニタリングデータや気象データと常時データ同化を行いながら汚染物質拡散予測を実行し、緊急時には迅速にデータを引き出すといった使い方が将来的に期待される。
また、HPC分野におけるこれまでの研究の大きな方向性が、大規模なスーパーコンピュータ上で単一のシミュレーションの規模を拡大することであったのに対して、最近は、出来るだけ少ない数の高速な計算機ユニットに計算処理をおさめて、計算条件の異なるシミュレーションを多数同時に実行するアンサンブル計算によって高度なデータ同化や解析の不確実性の統計的評価を行うことが重要になりつつある。その意味においても、DGX-2のような高密度実装のGPUノードを同時に複数台利用した解析システムのニーズは大きいといえる。
参考記事:日本原子力研究開発機構、NVIDIA DGX-2の活用で汚染物質拡散シミュレーションの高速化を実現
【専門用語】
AMR
適合細分化格子法(Adaptive Mesh Refinement) 、等間隔格子の実行性能を維持しつつ、高解像度の計算が必要な部分に局所的に細かい格子を配置する手法
GPU
Graphics Processing Unit, 3Dグラフィックスなどの画像描写を行う際に必要となる計算処理を行うプロセッサ
LBM
格子ボルツマン法(Lattice Bolzmann method)、連続体である流体を、格子上を並進・衝突する仮想的な粒子の集合体として仮定し、格子上の粒子の速度分布関数について時間発展方程式を解く手法
Reedbush
東京大学情報基盤センターが運用する演算アクセラレータとしてGPUを搭載したスーパーコンピュータシステム
TSUBAME2.5
2013年9月にGPUのアップグレードを行いTesla K20Xを搭載し、理論演算性能5.7PFlops(倍精度)の能力を持つスーパーコンピューターシステム
Tesla K20X
第2世代Keplerと呼ばれるGPUコアを2688基集積し,235Wの消費電力で,単精度浮動小数点数演算のピーク性能は3.95 TFLOPS、倍精度浮動小数点数演算のピーク性能は1.31 TFLOPS
Tesla P100
Pascalアーキテクチャを採用するGPUコアを3584基集積し、250Wの消費電力で、単精度浮動小数点演算のピーク性能は、9.3TFLOPS、倍精度浮動小数点演算のピーク性能は4.7TFLOPS
Tesla V100
Voltaアーキテクチャを採用するGPUコアを5120基集積し、250Wの消費電力で、単精度浮動小数点演算のピーク性能は、14TFLOPS、倍精度浮動小数点演算のピーク性能は7TFLOPS。640基のTensorコアを搭載し112TFLOPSの演算性能を持つ。
NVLink
GPU間やCPU間を高速で低遅延で接続するインターフェース
NVSwitch
NVLink専用のクロスバースイッチ。DGX-2では16基のGPUが300GB/sの帯域で相互通信できる。
データ同化
(data assimilation)、数値シミュレーションに実測データを取り入れる手法
マルチスケール解析
数メートルから数キロメートルまでの解像度の変化に対応した解析
特別イベント

寄稿者
![]() 西克也
西克也
西克也はフェアチャイルド社、クレイ・リサーチ社、ベストシステムズ社など、30年以上に渡ってHPCに関する仕事に従事している。Hpcwire Japanの編集長として記事の作成と翻訳を行っている。
![]() 島田佳代子
島田佳代子
1999年~2007年まで英国在住。2001年よりスポーツ、旅、ビジネス、映画など幅広いジャンルで執筆活動を開始し、Hpcwire Japanでは主に日本のHPC業界が世界に誇る研究者、開発者の方々のインタビューを担当。
![]() 小柳義夫
小柳義夫
小柳義夫氏は40年以上に亘ってHPCに携わってきた研究者であり、日本のHPC業界における生き字引として有名。現在 高度情報科学技術研究機構に所属し、産業界のHPC推進にあたっている。
![]() 小西史一
小西史一
小西史一は、理化学研究所、東京工業大学においてHPCおよびバイオインフォマティクスに関する研究と教育に携わってきた研究者。2012年からフォトグラファーとしての活動を開始し、現在はIT技術・セキュリティのコンサルティング業務に携わっている。