
HPCの歩み50年記事一覧

スパコンリスト日本

記事寄稿について

GPCNeTは有効か
スポンサー記事

Gilad Shainer(Mellanox Technologies)
新しいデータの世界が幕を開け、これまでは解決できなかった問題を解決に導く高度な科学シミュレーションや、私たちの生活をより良くする高度なディープラーニングエンジンの開発に道を開いています。データセンターのアーキテクチャもこうした活動を支援するように変化し、旧来のCPUセントリックなアーキテクチャからデータセントリックなアーキテクチャへの移行を支える新しいテクノロジーが開発されてきました。このような移行の実現に重要な役割を果たす新しいコンピューティングオプションの1つが、スマートでプログラマブルなインターコネクトソリューションです。
InfiniBandは、ハイパフォーマンスコンピューティングやディープラーニングの分野で長い間広く採用されているインターコネクト規格であり、近年は演算インテンシブなアプリケーションやデータインテンシブなアプリケーションを処理するクラウドプラットフォームにおいても採用が進んでいます。現在、世界中の主要なクラウドプラットフォームやハイパースケールプラットフォーム、多くのスーパーコンピュータシステムで、無数の計算ノードが相互に接続されています。演算・データインテンシブなアプリケーションの高速でスケーラブルな実行を可能にするインターコネクト技術として、世界中で選ばれているのがInfiniBandです。HPC、AI、ビッグデータなどの分野において、従来のイーサネットインフラストラクチャ内に構築し、高速ゲートウェイを介してイーサネットに接続する大規模なInfiniBandアイランドが増えています。しかも、InfiniBandはコストパフォーマンスに優れ、同等データスループットのイーサネットより低コストです。
InfiniBandは、ネットワーク機器で演算を処理する革新的なIn-Network Computingエンジンを提供し、これにより、ネットワークを通過するデータに対するデータ削減やデータマッチングなどの算術演算を実行できます。また、他のデータ関連操作の実行を簡単にプログラムできる標準の計算コアを搭載するInfiniBand機器があります。こうした利点を備えたInfiniBandは、イーサネットや他の明示的、非明示的イーサネット系独自規格ネットワークより推奨されるソリューションとして地位を確立しています。
革新的なIn-Network Computingでは、ネットワーク自体が伝送中データの“コプロセッサ”の役割も果たすことができます。これは、データセンターのインターコネクトの重要なミッションである効果的かつ効率的なデータ伝送や、他のコンピューティングリソースによる遅延のないデータ受信を強化します。この分野では長年にわたってさまざまな技術や機能が開発されており、RDMA、GPUDirect® RDMA、Quality of Service、アダプティブルーティング、輻輳制御などがあります。これらはいずれも標準的なInfiniBandで採用されていますが、アダプティブルーティングと輻輳制御は他の新しい独自規格ネットワークではまだ新しい機能です。
ネットワークの輻輳を例にご説明しましょう。ネットワークの輻輳が発生する原因は主に2つあります。1つはポイントツーポイント通信が同一のネットワークパスを共有し、それ以外のパスを使用しない場合、もう1つは多対1通信で多数の送信元から同時に届くデータを1つの受信側で受信しきれない場合です。
アダプティブルーティングは、ポイントツーポイント通信で負荷の分散の不均衡から発生するネットワークの輻輳を解消するメカニズムです。InfiniBandのアダプティブルーティングは、オークリッジ国立研究所がMPIGraphベンチマークを使用して実施した測定で96%のネットワーク使用率を実現することが立証されています(出典:“The Design, Deployment, and Evaluation of the CORAL Pre-Exascale Systems”、Sudharshan S. Vazhkudai、Arthur S. Bland、Al Geist他)。InfiniBandではきめ細かいアダプティブルーティングが可能で、複数のアダプティブルーティングスキームをサポートします。これにより、システム設計と使用状況に基づいて最適なスキームを使用し、最適なパフォーマンスを実現することができます。
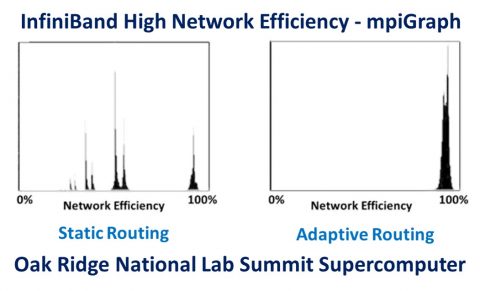 |
| 図1 – Summitスーパーコンピュータで測定したスタティックルーティングとアダプティブルーティングのmpiGraphパフォーマンス結果。InfiniBandのアダプティブルーティングがポイントツーポイントの輻輳を解消し、96%のネットワーク使用率を実現することを示しています(出典:“The Design, Deployment, and Evaluation of the CORAL Pre-Exascale Systems”、Sudharshan S. Vazhkudai、Arthur S. Bland、Al Geist他)。 |
多対1の輻輳の問題は、輻輳管理や輻輳制御のメカニズムによって解決できます。輻輳制御では、ネットワークスイッチを使用して多対1のシナリオを検出し、送信側に高速ネットワーク通知をトリガーします。輻輳制御から通知を受け取った送信側は、受信側がデータを正常に受信できるように、発信するデータ量を減らします。これにより、ネットワークにデータが充満せず、スイッチバッファを空の状態に維持して多対1の輻輳のシナリオを回避できます。輻輳通知の発行と受信が高速であるほど、輻輳制御の効率は高まります。
2010年、ノルウェーのSimula研究所チームと共同でInfiniBand輻輳制御メカニズムの実証を行ったことがあります。7台のサーバーと2台のスイッチで構成する小規模なネットワークを構築しました。DDR 20Gb/s InfiniBandリンクで各サーバーをスイッチに接続し(3台のサーバーを1台のスイッチに、4台のサーバーを別の1台のスイッチに接続)、2台のスイッチ同士をQDR 40Gb/s InfiniBandリンクで接続しました。そこに多対1ネットワークの輻輳状態による被影響フローが発生するケースを作りました(被影響フローとは、多対1通信自体には含まれず、多対1通信の輻輳の影響を受けてパフォーマンスが低下してしまうデータフローです)。このケースではInfiniBandの輻輳制御がネットワークの輻輳を解消し、被影響フローの発生を防ぐことが立証されました。
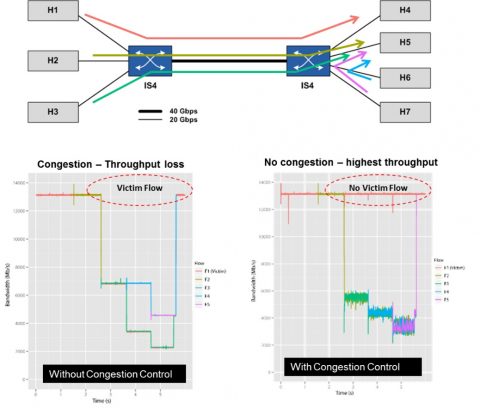 |
| 図2 – InfiniBandの輻輳制御ありの場合となしの場合のネットワークパフォーマンス。InfiniBandの輻輳制御がある場合は、多対1通信の輻輳と被影響フローの発生が解消されています(出典:“first experiences with congestion control in InfiniBand hardware”、2010年)。 |
2010年当時と比べ、現在のInfiniBandの輻輳制御ハードウェアメカニズムにさまざまな改良と強化が加えられていることは言うまでもありません。たとえば、最新のHDR 200Gb/s InfiniBandスイッチとアダプタは、効果的で効率的な輻輳制御を実現する高速検出・通信メカニズムをサポートしています。 最近、Global Performance and Congestion Network Test(GPCNeT)という新しいネットワークベンチマークが登場しました。このGPCNeTベンチマークは、バックグラウンドトラフィックがランダムリングの遅延と帯域幅、およびスモールデータMPI Allreduceオペレーションに及ぼす影響を測定するMPIレベルのテストです。なぜ急にこのようなベンチマークが必要になり、10年前ではなく今作られることになったのでしょうか。その主な理由は、これまでの独自規格ネットワークでは輻輳制御をサポートしておらず、新しく開発する独自規格ネットワークで輻輳制御の導入が始まったことです。
かいつまんで説明すると、GPCNeTベンチマークは2つのシナリオで3つのMPIオペレーションを個別に測定します。1つは、一部のクラスタノードがMPIオペレーションの1つを実行している間、残りのノードはアイドル状態であるシナリオです。もう1つは、一部のノードが同じMPIオペレーションを実行している間、残りのノードはノイズデータをファブリックに注入し、多対1通信とネットワークの輻輳を発生させるシナリオです。この両方の結果をオペレーションごとに比較して、GPCNeTベンチマークスコアを算出します。
GPCNeTベンチマークは、絶対的パフォーマンスの指標ではなく、負荷を加えたときの相対的パフォーマンスの指標です。そのため、GPCNeTではネットワーク同士を比較してどちらが速くどちらが遅いかをランク付けすることはできません。GPCNeTの測定では、輻輳なしのときのMPI Allreduceの遅延が2マイクロ秒、輻輳ありのときは3マイクロ秒のネットワークの方が、輻輳なしで100マイクロ秒、輻輳ありで110マイクロ秒のネットワークより劣ると誤判定されてしまいます(周知のとおり、ネットワークは遅延が低い方が優れています)。これはGPCNeTベンチマークの欠点であり、ネットワークの実際の遅延のパフォーマンスそのものを示すものではありません。
また、GPCNeTベンチマークでは8バイトを重要なデータサイズと見なしますが(MPI Allreduceの場合)、輻輳ノイズにはラージメッセージが影響します。8バイトのMPI Allreduceは重要でないとは言いませんが、ディープラーニングなどのアプリケーションのパフォーマンスには、より大きなデータサイズ削減や他の集合体の方がはるかに大きな影響を及ぼします。ディープラーニングは多くのHPCアプリケーションで重要な役割を果たし、HPCシミュレーションの精度を高めるために使われるようになります。8バイトデータの交換も実際に使われるとしても、はるかに大きなデータメッセージ(数百から数百万バイト)の方がずっと高い頻度で使用され、アプリケーションのパフォーマンスに及ぼす影響も大きくなります。
上記以外にもさまざまな理由から、GPCNeTは不完全なベンチマークであってその利点は限定的であり、現実のシナリオにおけるネットワークを比較するには十分な信頼性がないと言えるでしょう。
最後に、HDR 200Gb/s InfiniBandのパフォーマンスをGPCNeTベンチマークで測定するとどうなるでしょうか。テストした結果、HDR InfiniBandの世界最高水準のパフォーマンスと、ゼロジッタまたは超低ジッタが立証されました。InfiniBandの輻輳制御メカニズムは、GPCNeTベンチマークで生成される輻輳を解消し、ほぼ1のGPCNeT輻輳係数を達成することが示されました。1はこのベンチマークで達成可能な最良の係数値です。
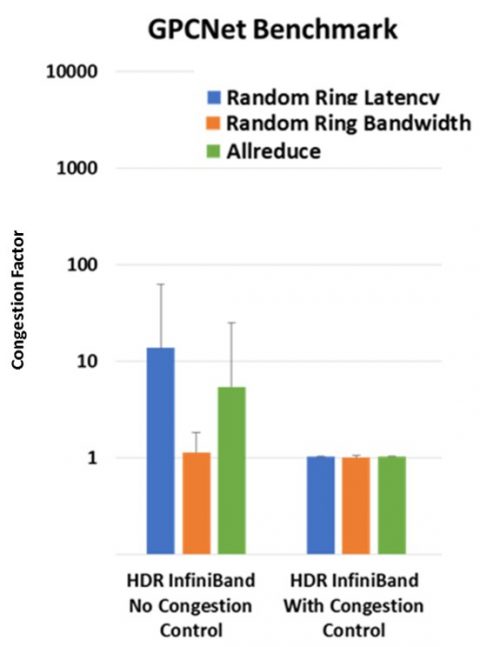 |
| 図3 – 輻輳制御ありの場合となしの場合のHDR 200Gb/s InfiniBandのGPCNeTベンチマーク結果。輻輳制御ありの場合、InfiniBandは世界最高水準のパフォーマンス結果を示しました。 |
ハイパフォーマンスコンピューティングシステムやインターコネクトを評価するには、GPCNeTよりはるかに優れたベンチマークがあります。また、システムやインターコネクトのパフォーマンスと能力を判定する場合、実際のワークロードのベンチマークを測定できるアプローチの方が優れていることは明らかでしょう。GPCNeTベンチマークは利点より欠点の方が大きいように思いますが、いかがでしょうか。
特別イベント

寄稿者
![]() 西克也
西克也
西克也はフェアチャイルド社、クレイ・リサーチ社、ベストシステムズ社など、30年以上に渡ってHPCに関する仕事に従事している。Hpcwire Japanの編集長として記事の作成と翻訳を行っている。
![]() 島田佳代子
島田佳代子
1999年~2007年まで英国在住。2001年よりスポーツ、旅、ビジネス、映画など幅広いジャンルで執筆活動を開始し、Hpcwire Japanでは主に日本のHPC業界が世界に誇る研究者、開発者の方々のインタビューを担当。
![]() 小柳義夫
小柳義夫
小柳義夫氏は40年以上に亘ってHPCに携わってきた研究者であり、日本のHPC業界における生き字引として有名。現在 高度情報科学技術研究機構に所属し、産業界のHPC推進にあたっている。
![]() 小西史一
小西史一
小西史一は、理化学研究所、東京工業大学においてHPCおよびバイオインフォマティクスに関する研究と教育に携わってきた研究者。2012年からフォトグラファーとしての活動を開始し、現在はIT技術・セキュリティのコンサルティング業務に携わっている。