
HPCの歩み50年記事一覧

スパコンリスト日本

記事寄稿について

AMD、3D V-Cache搭載CPU「Milan-X」とMultichip Instinct MI200 GPUを発表
Tiffany Trader

AMDのCEOであるLisa Suは、先日開催されたバーチャルイベントにおいて、待望の最新サーバ製品を発表した。AMDの新しい3D V-Cacheテクノロジーを採用した新CPU「Milan-X」と、Infinity Fabricで接続された2つのダイに最大220個の演算ユニットを搭載し、ピーク時に倍精度で47.9テラフロップスという驚異的な性能を実現した新GPU「Instinct MI200」である。
「現在、我々はハイパフォーマンス・コンピューティングのメガサイクルに突入しています。これは、現代の生活を定義するサービスやデバイスを強化するために、より効率的かつ大規模に演算性能を向上させる必要性が高まっていることが背景にあります。」とSuは述べている。
 |
AMDの新しい第3世代Epyc CPU(コードネーム:Milan-X)は、AMD 3D V-Cacheを搭載しており、3Dチップレットテクノロジーを採用した同社初のサーバCPUである。このプロセッサは、標準的なMilanプロセッサに比べて3倍のL3キャッシュを搭載している。Milanでは、各CCD(Complex Core Die)に32メガバイトのキャッシュが搭載されていたが、Milan-Xでは64メガバイトの3Dスタックキャッシュが追加され、CCDあたり96メガバイトとなった。CCDが8個の場合、L3キャッシュは768メガバイトにもなる。これにL2とL1のキャッシュを加えると、1ソケットあたり804メガバイトのキャッシュが搭載されている。
Milan-Xは、Milanと同じ7nmのZen 3コアを採用しており、最大コア数は64コアとなる。また、BIOSをアップグレードすることで、既存のプラットフォームにも対応する。
AMDによれば、3D V-Cacheを搭載したMilan-Xは、シリコン・バイア・アプローチを通して、ハイブリッドボンド+を採用しており、2Dチップレットの200倍以上のインターコネクト密度を実現し、既存の3Dスタッキングソリューションと比較して15倍以上の密度を実現している。ダイ・ツー・ダイのインターフェースには、銅と銅のダイレクトボンドを採用し、はんだバンプをなくして熱伝導、トランジスタ密度、インターコネクトピッチを向上させている。
AMDは、Milan-Xがターゲットとするテクニカル・コンピューティング・ワークロードにおいて、Milanプロセッサと比較して50%の性能向上を実現したと報告している。AMDは、シノプシスの検証ソリューション「VCS」を用いたEDAワークロードにおいて、Milan-Xのパフォーマンスの高速化を実証した。AMDの3D V-Cacheを搭載した16コアのMilan-Xは、V-Cacheを搭載していない標準的なMilanと比較して、RTL検証を66%高速化している。VCSは、世界のトップ半導体企業の多くで採用されており、チップがシリコンに投入される前の開発プロセスの初期段階で不具合を検出することができる。
Microsoft Azureは、Milan-Xの最初の顧客として発表されており、HBv3インスタンスのアップグレードが本日プレビューされており、HBv3全体の展開についても更新が予定されている。従来のOEMおよびODMサーバパートナーであるDell Technologies社、HPE社、Lenovo社、Supermicro社は、2021年の第1四半期に向けてMilan-X製品を準備しています。ISVのエコシステムパートナーには、Altair、Ansys、Cadence、Siemens、Synopsysが名を連ねている。
 |
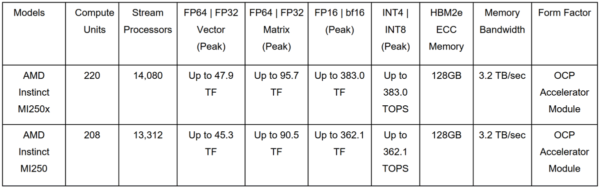
TSMCの6nmプロセスで製造されたMI200は、世界初のマルチチップGPUで、1つのパッケージで計算とデータのスループットを最大化するように設計されている。MI200シリーズは、2つのCDNA 2 GPUダイを搭載し、580億個のトランジスタを使用している。最大220個の演算ユニットと880個の第2世代マトリックスコアを搭載している。8スタックのHBM2eメモリは、合計128ギガバイトのメモリを3.2TB/sで提供し、MI100に比べて4倍の容量と2.7倍の帯域幅を実現している。2つのCDNA2ダイをつなぐInfinity Fabricリンクは25 Gbpsで動作し、合計400 GB/sの双方向帯域を実現している。
 |
|
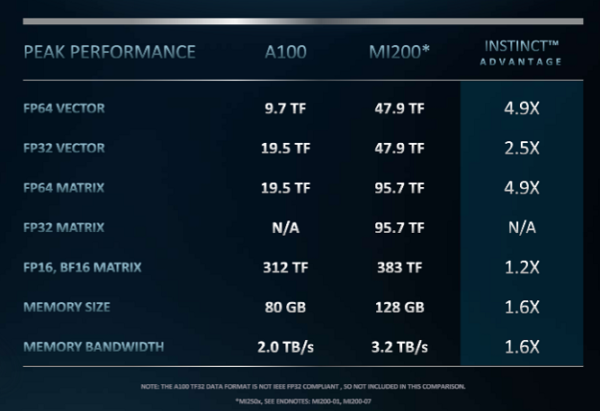
MI200アクセラレータは、ピーク時の倍精度演算が最大47.9テラフロップスで、「もしもチップ設計者が倍精度(FP64)性能のためにGPUアーキテクチャを劇的に最適化したとしたら」という問いに対する答えを表向きに示している。MI250Xは、1年間でMI100の4.2倍(11.5テラフロップスに対して47.9テラフロップス)のピーク倍精度を達成した。これに対してAMDは、Nvidiaがサーバ用GPUの従来の倍精度FP64のピーク性能を2014年から2020年までに3.7倍に伸ばしたと指摘している。並べて比較すると、MI200 OAMは、NvidiaのA100 GPUと比べて、FP64のピーク性能では約5倍、FP32のピーク性能では2.5倍の速度を実現している。
さらに、Instinct MI250Xは、AIワークロードにおいて、ピーク単精度(FP32)性能で47.9テラフロップス、ピーク理論半精度(FP16)性能で383テラフロップスを実現する。この高密度な演算能力は、電力コストを伴わないものではない。最上位機種であるOAM MI250Xの消費電力は最大560Wだが、空冷式などの構成であれば、必要な電力は多少少なくなる。しかし、TDPが500~560ワットということは、実質的に2つのGPUを1つのパッケージに収めていることになり、公開されているシステムのスペック(Frontierなど)を見る限り、1ワットあたりの処理能力の目標値は非常に高いものとなっている。
 |
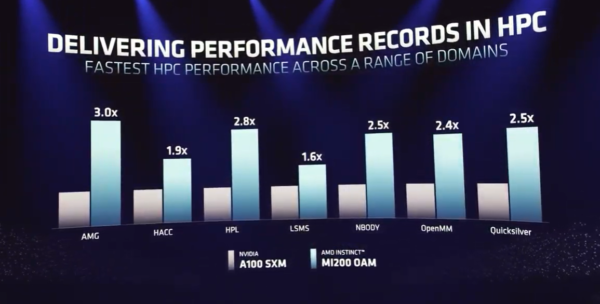
今回の発表会では、AMDのデータセンター・組み込みソリューション事業グループの上級副社長兼ゼネラルマネージャーであるForrest Norrodが、さまざまなHPCアプリケーションにおいて、MI200 OAMとNvidiaのA100(80GB)GPUのヘッド・ツー・ヘッドの比較を行なった。AMDのテストでは、シングルソケットの第3世代AMD EypcサーバにAMD Instinct MI250X OAM 560ワットGPUを1基搭載した場合、High Performance Linpackベンチマークで中央値42.26テラフロップスを達成した。
 |
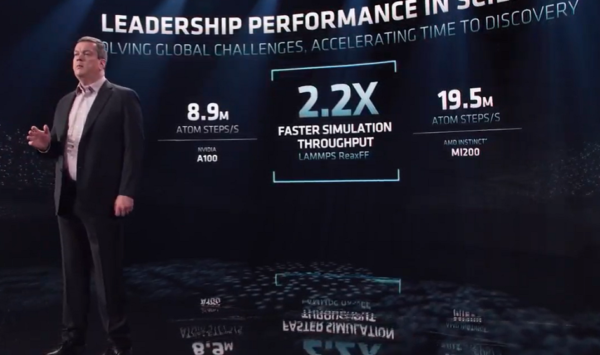
またNorrodは、分子シミュレーションコードLAMMPSで、炭化水素分子の燃焼シミュレーションを行い、MI200 OAMとNvidia A100(80GB)の競合比較を行なった。シミュレーションのタイムラプスでは、4つのMI250X 560ワットGPUが、4つのA100 SXM 80GB 400ワットGPUの半分以下の時間で作業を完了しているのがわかる。
 |
MI200アクセラレータは、第3世代のAMD Infinity Fabricアーキテクチャを導入している。最大8本のInfinity Fabricリンクが、AMD Instinct MI200を第3世代Epyc Milan CPUやノード内の他のGPUと接続し、最大800GB/sのアグリゲート帯域幅を実現するとともに、CPUとGPUのメモリコヒーレンシーを統合することができる。
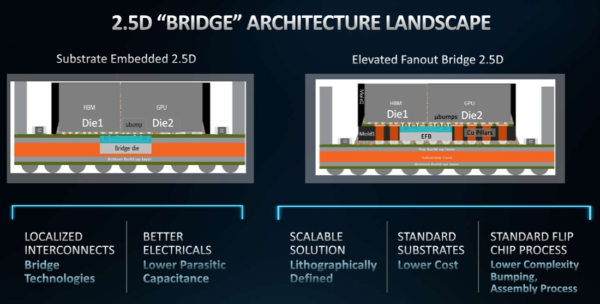
また、AMDはElevated Fanout Bridge(EFB)テクノロジーを導入する。「基板内蔵型のシリコンブリッジ・アーキテクチャとは異なり、EFBは標準的な基板とアセンブリ技術の使用を可能にし、高い性能を維持しながら、より優れた精度、スケーラビリティ、歩留まりを提供します。」とNorrodは述べている。
 |
新しいMI200シリーズのフォームファクタとしては、オープンハードウェアのコンピュートアクセラレータモジュールまたはOCPアクセラレータモジュール(OAM)フォームファクタで提供されるMI250XおよびMI250、そしてPCIeカードフォームファクタのAMD Instinct MI210の3種類が発表された。
AMD MI250Xアクセラレータは、現在HPEが提供するHPE Cray EXスーパーコンピュータに搭載されている。PCIeフォームファクタを含むその他のMI200シリーズアクセラレータは、ASUS、ATOS、Dell Technologies、Gigabyte、HPE、Lenovo、Supermicroなどのサーバパートナーから2022年第1四半期に提供される予定だ。
 |
MI250Xアクセラレータは、現在、HPEと共同で米国DOEのオークリッジ国立研究所に設置されている次期エクサスケール・スーパーコンピュータ「Frontier」の主要な計算エンジンとなる。Frontierの9,000台以上のノードには、Milan-Xではなく「最適化された第3世代AMD Epyc CPU」が1つずつ搭載され、AMDのコヒーレントなInfinity Fabricを介して4台のAMD MI250Xアクセラレータに接続される。
今回の会議で、ORNL所長のThomas Zachariaは、1台のMI250X GPUが、現在米国で最速のシステムであるORNLのスーパーコンピュータ「Summit」のノード全体よりも強力であると述べた。Frontierは、1.5倍のピーク倍精度エクサフロップスを目標としているが、GPUだけで1.72エクサフロップス以上(9,000×4×95.7テラフロップス)のピーク性能を達成することができる。
先日お伝えしたように、MI200は3つの大陸の3つの巨大なシステムに搭載される。MI200は、来年稼働予定の米国初のエクサスケール・コンピューター「Frontier」に加え、欧州連合(EU)のプレエクサスケール・システム「LUMI」、オーストラリアのペタスケール・システム「Setonix」にも採用される。
 |
| AMD Instinct MI200 OAMアクセラレータ |
Suは、「我々の勢いが増すにつれ、Milanの採用率はRomeを大幅に上回っています。」と述べている。ロードマップを見ると、次世代Epycプラットフォーム “Genoa “は、最大96個の高性能5nm “Zen 4 “コアを搭載し、次世代メモリとIO機能であるDDR5、PCIe Gen5、CXLをサポートする。AMDによると、Genoaは現在、顧客へのサンプリングを行っており、来年には生産・発売される予定である。
「我々はTSMCと協力して5nmをハイパフォーマンス・コンピューティング向けに最適化しました。」とSuは述べている。「この新しいプロセスノードは、現在の製品で使用している7nmプロセスと比較して、2倍の集積度、2倍の電力効率、1.25倍のパフォーマンスを提供します。」と述べている。
 |
Suはまた、クラウドネイティブコンピューティングのためのZen 4の新バージョン、”Bergamo “を発表した。Bergamoは、最大128個の高性能な “Zen 4 C “コアを搭載し、Genoaのその他の機能も備えている。Bergamoは、最大128個の高性能「Zen 4 C」コアを搭載し、DDR5、PCIe Gen 5、CXL 1.1、Infinity Guardのセキュリティ機能など、Genoaのその他の機能を備えている。さらに、Genoaと同じZen 4命令セットでソケット互換性がある。Bergamoは、2023年前半の出荷開始に向けて順調に進んでいるとSuは述べた。
Suは、「複数世代にわたるCPUコアのロードマップへの投資と、高度なプロセスおよびパッケージング技術を組み合わせることで、当社は汎用のテクニカル・コンピューティングとクラウド・ワークロードにおいてリーダーシップを発揮することができます。今後もハイパフォーマンス・コンピューティングの可能性を追求していきます。」と述べている。
また、AMDは、複数のアクセラレータベンダーやアーキテクチャにまたがる環境をサポートするオープンソフトウェアプラットフォーム「ROCm」のバージョン5.0を発表した。「ROCm 5.0では、MI200のサポートと最適化を追加し、ROCmのサポートをRadeon Pro W6800ワークステーションGPUにまで拡大し、エンドユーザの生産性を向上させる開発者ツールを改善しています。」と、AMDのGPUプラットフォーム担当コーポレート・バイス・プレジデントのBrad McCredieはメディアブリーフィングで述べている。
また、AMD Infinity Hubは、開発者がHIPやOpenMPに関するドキュメント、ツール、教育資料にアクセスできるオンラインポータルで、システム管理者や科学者は、AMDプラットフォームに最適化されサポートされているコンテナ型HPCアプリケーションやMLフレームワークをダウンロードすることができる。
今回のニュースラフトについて、マーケットウォッチャーであるIntersect360 Research社のCEO、Addison Snellは、「AMDは、CPU、GPU、そしてその両方をパッケージ化することで、HPCにおけるパフォーマンスの新たな基準を設定しました。」と述べている。「Milan-XとMI200のどちらを使っても、それだけで十分な性能を発揮します。また、ベンチマークによれば、複数の性能を発揮します。Infinity Fabric上にコヒーレントなメモリを持つことは、IntelもNvidiaもすぐには追いつけないほどの画期的なことです。」と述べた。
特別イベント

寄稿者
![]() 西克也
西克也
西克也はフェアチャイルド社、クレイ・リサーチ社、ベストシステムズ社など、30年以上に渡ってHPCに関する仕事に従事している。Hpcwire Japanの編集長として記事の作成と翻訳を行っている。
![]() 島田佳代子
島田佳代子
1999年~2007年まで英国在住。2001年よりスポーツ、旅、ビジネス、映画など幅広いジャンルで執筆活動を開始し、Hpcwire Japanでは主に日本のHPC業界が世界に誇る研究者、開発者の方々のインタビューを担当。
![]() 小柳義夫
小柳義夫
小柳義夫氏は40年以上に亘ってHPCに携わってきた研究者であり、日本のHPC業界における生き字引として有名。現在 高度情報科学技術研究機構に所属し、産業界のHPC推進にあたっている。
![]() 小西史一
小西史一
小西史一は、理化学研究所、東京工業大学においてHPCおよびバイオインフォマティクスに関する研究と教育に携わってきた研究者。2012年からフォトグラファーとしての活動を開始し、現在はIT技術・セキュリティのコンサルティング業務に携わっている。