
HPCの歩み50年記事一覧

スパコンリスト日本

記事寄稿について

AMD/Xilinx、改良版 VCK5000 推論カードでNvidia を狙い撃ち
John Russell

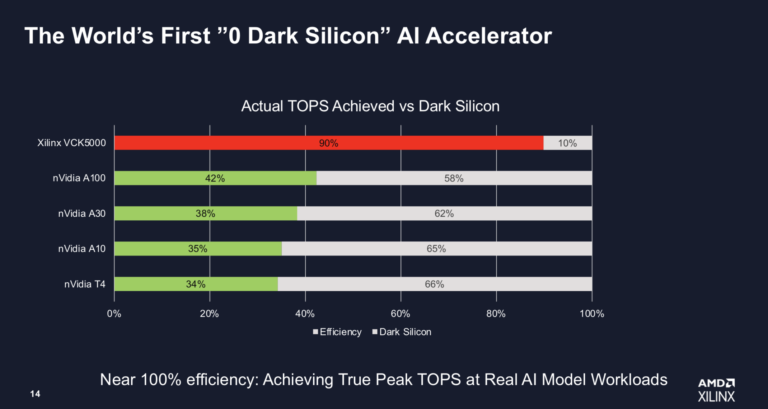
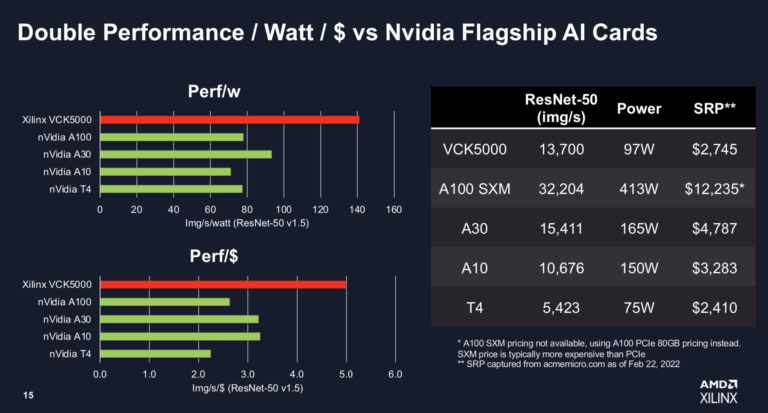
AMD/Xilinxは、NvidiaのGPUラインに直接狙いを定めた一連の競合ベンチマークとともに、AI推論カードVCK5000の改良版を発表した。AMDによると、新しいVCK5000は以前のバージョンよりも3倍性能が向上し、Nvidia T4よりも2倍のTCOを実現するという。また、AMDは複数のNvidia GPUに対して有利なベンチマークを示し、「リアルAIモデルのワークロード 」でNvidiaのA100、A30、A10、T4の34~42%に対して、同社のVCK5000は真のピークTOPSの90%を達成したと主張している。
このような強い姿勢で、Nvidiaの製品に対してTCOを強調することは、2017年にAMDがデータセンターから長い間姿を消していたEpyc CPUラインを発表したときの、AMDの対Intel戦略をどこか彷彿とさせる。もちろんAMDは、2020年に買収を発表し、先週Xilinxの買収を完了したばかりである。VCK5000は現在2745ドルで販売されており、AMDは特に 「現在のサプライチェーンの問題 」を考慮すると、非常に競争力のある価格であると述べている。
同社は、このニュースに関して正式なプレスリリースを発行していないが、先日のHPCwireとのブリーフィングのように非公式なブリーフィングを行っているという。
「VCK5000は、当社の7nm Versal ACAPシリコンを搭載した最初のPCIeカードです。AI推論に最適化されており、AIエンジンコアのものをFPGAに入れるのはこれが初めてです」と、AMDの新しいAdaptive and Embedded Computing GroupでAIとソフトウェアソリューションのプロダクトマーケティング担当ディレクターのNick Niは言う。「このカードは実は新しくはありませんが、変わったのはAI推論で3倍近く性能を向上させたことです。また、私たちはAI推論において世界初のゼロダークシリコンであると主張しています。私たちは、他の誰も近づかなかったデータシートのピークトップ100%近くを達成した唯一の存在です。」
AI推論カード「VCK5000」は、FPGAとArm CPUの要素を含んでおり(下図参照)、昨年5月に発表された。AMDの「Versal Adaptive Compute Acceleration Platform(ACAP)」の一部だ。AMDによれば、この全体的なデザインは、同社が「ダークシリコン」と呼ぶ問題、つまり基本的にメモリからのデータを待つアイドル状態の処理素子を解決するものだという。
 |
 |
 |
Hyperion Research社のアナリストSteve Conwayは、次のように慎重な見方を示しています。「Nvidiaはほぼ独力でGPGPUの市場を作り上げ、今日それを支配していますが、どんな大きな市場でも競争相手を惹きつけるものであり、競争は良いことでです。AMD/Xilinxの新しい推論カードがどの程度の競争力を持つかを知るのは時期尚早ですが、推論にもっと注目が集まるのは素晴らしいことです。より高性能な推論によってAIにインテリジェンスが加わり、与えられたタスクの学習負担が軽減されるはずです」とConwayは述べている。
HPCコミュニティでは、SC21の頃に同社が発表し、FGPAベースの最強のアクセラレータカードとしてアピールした「Xilinx-Alveo U55C」の方が馴染みがあるかもしれない。この2枚のカードの区別を求められたAMDは、次のように回答した。
- 「Alveo U55Cは、AMD-Xilinxのプロダクションアクセラレータカードのポートフォリオに属し、特にHPCとビッグデータのワークロードをターゲットにしています。Virtex UltraScale+ FPGAをベースにしており、VCK5000とは異なるフォームファクタになっています。Xilinx RoCE v2 ベースのクラスタリング ソリューションにより、大規模な計算ワークロードを抱える幅広い顧客が、既存のデータ センター インフラとネットワークを使用して、強力な FPGA ベース HPC クラスタリングを実装できるようにします。」
- 「VCK5000 は、当社の7nm Versalポートフォリオをベースにした開発用カードで、高スループットのAI推論や信号処理の演算性能を必要とする設計向けに最適化されています。VCK5000は、ほぼゼロダークシリコンを達成した最初のAIチップであり、NvidiaのA100やT4 GPUなどの競合デバイスを、標準ベンチマークモデルを用いて性能/ワットで最大2倍上回っています 」と述べている。
FPGAをより広く使用するための長年の障害となっているのは、RTLレベルでのプログラミングを必要とするその長くて複雑な開発プロセスである。Alveo U55C と VCK5000 カードは、AMD/Xilinx Vitis Unified Software Platform を活用することで、この難題を回避しようと試みている。
 |
|
| AMD/Xilinx VCK5000 推論カード | |
Niは、最新のVCK5000でベンチマークを実行するためのプログラミングの苦労について、「ボトムアップ設計やRTLによる従来の設計を行った場合、GPUを使う場合と比較して(開発に)確実に時間がかかっていたはずです」と説明する。「しかし、我々は(Vitisによる)ソフトウェア抽象化を使っています。ここで紹介する成果は、すべてRTLの開発を伴わないものです。すべてTensorFlowとPytorchをベースにしているだけです。基本的にMLPerfが提供するTensorFlowとResNet 50のモデルを我々のコンパイラーに取り込みました。それを実行し、結果を得る。まさにGPUと同じような設計サイクルです。」
Niによると、AMD/Xilinxは、今後のMLPerfの推論演習でVCK5000の結果を提出する予定だそうだ。
最近、FPGAベースのソリューションが注目されていることは、簡単に触れておく必要があるだろう。ちょうど前日、インテルはIntel 7プロセスで作られたAgilex M-Series FPGAを発表した。インテルは、この新しいFPGAの特徴を次のように報告している。「FPGAとしては業界最高のメモリ帯域幅、HBM対応FPGAとしては業界最高のDSP演算密度、競合の7nm FPGAと比較してワット当たり2倍以上のファブリック性能」だという。インテルは2015年にAlteraを買収し、FPGAゲームに参入した。
FPGAへの関心が再び高まっている背景には、AIモデルの規模が急速に拡大していること、これらのモデルへのデータの出し入れを加速する必要があること、ソフトウェア定義アーキテクチャの進化が続いており、それに伴ってスマートコントローラが分散していること、FPGAプログラミングツールが向上していることなど、多くの原因がある。FPGAベースのソリューションは、特殊性と柔軟性、そして性能をコスト効率よく融合させることができると擁護者たちは主張している。これは常に約束されていることだが、その実現はしばしば困難なものとなっている。
現在、FPGA は単体でも、他のプロセッシングやメモリ コンポーネントと組み合わせて SoC としてパッケージ化されたものでも、注目を集めている。FPGA は、データセンターからエッジに至るまで、AI ソリューションの一部であるとするベンダーの意見が多く聞かれるようになっている。
 |
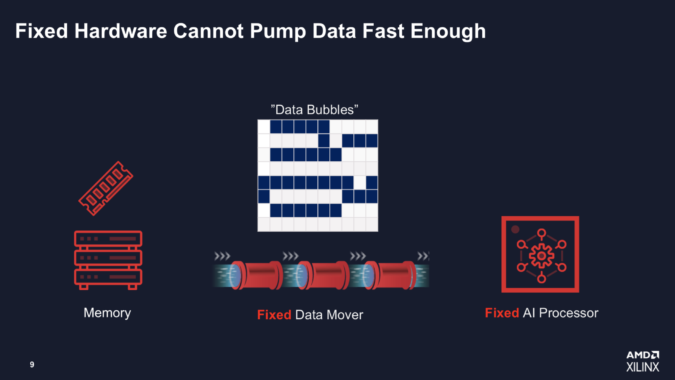
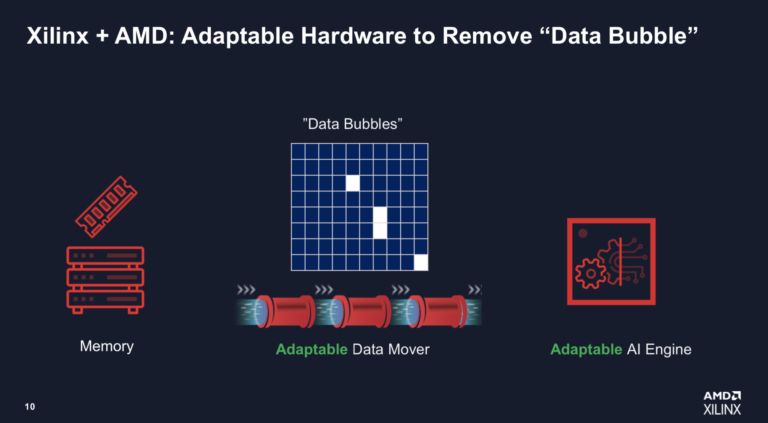
AMDは、固定アーキテクチャのGPUと異なり、より柔軟なFPGAベースのシステムは、AIモデルの特定のニーズ、特にデータフロー要件に合わせて設計することができると主張している。この主張は、AMDの「ダークシリコンの解決」問題の核心であり、一部のワークフローでNvidia GPUがピークTOPSの50%を大きく下回っているという。
「コアAIプロセッサが固定されているため、Nvidiaの場合はTensorコアGPU用で、特定のモデル用に設計されており、固定されている上に、100%の効率を得るためにエンジンに送り込まなければならないデータも固定されています。今日のような大規模なモデルを実行すると、共有キャッシュで大量のキャッシュミスが発生するため、巨大なデータバブル(下のスライド)が発生するのです。例えば、Nvidia A30エンジンは330TOPSの処理能力がありますが、データを取り込むのは40%に過ぎないと言われています。そこで、FPGAのような適応性のあるシリコン(デバイス)が必要になってくるのです。」
「Xilinx社のアプローチと異なるのは、2つの点です。1つは、当社のエンジンです。ASICと同等の性能を持ちながら、ちょっとしたプログラマビリティを内蔵しています。VLIWコアでは、さまざまなタイプのデータパッシングが可能で、たとえばブロードキャストもできます。しかし、最も重要なのは、その基本コアにFPGAファブリックを装着していることです。キャッシュレスで、システム内にキャッシュもありませんから、キャッシュミスもありません。完璧な内部メモリ(フロー)を作ることができるので、毎クロックのデータをエンジンに送り込むことができます。そうすれば、データバブルを大幅に減らすことができ、100%あるいは100%に近い効率を得ることができます。」
 |
 |
Niはブリーフィングでビデオ分析アプリケーションを強調し、AMD/Xilinxはビデオ分析SDKとプラグインを持っていることを明らかにした。しかし、このプラットフォームはより柔軟性がある。
「ドメインスペシフィックアーキテクチャ と呼んでいます。非常に領域に特化した、この場合はAI推論に特化した、これらのモデルをすべて実行できるFPGAプログラミングを慎重に設計していると考えてください。私たちは、一発芸のようなものを作りたくなかったんです。Resnet50でしか使えないようなIPは作りたくなかったのです」とNiは言う。推論処理エンジンは、コンパイルされた命令に基づいて異なるモデルを調整する二次的な「小型プロセッサ」を内部に持つことができるという。
AMDは、FPGAベースのプラットフォームのポートフォリオに期待を寄せているのは確かだ。
この買収が完了したとき、AMDのCEOであるLisa Suは、「Xilinxの買収により、製品、顧客、市場が高度に補完され、差別化されたIPと世界レベルの才能が組み合わされて、業界の高性能および適応型コンピューティングのリーダーが誕生しましや」と述べている。Xilinxは、業界をリードするFPGA、アダプティブSOC、AIエンジン、ソフトウェアの専門知識を提供しており、AMDは、ハイパフォーマンスおよびアダプティブ・コンピューティング・ソリューションの業界最強ポートフォリオを提供し、クラウド、エッジ、インテリジェントデバイス全体で我々が見ている約1350億ドルの市場機会でより大きなシェアを獲得できるようになります。」と述べている。
 |
 |
ご期待ください
特別イベント

ISC 2026
6月 22 - 6月 26
International Conference for High Performance Computing, Networking, Storage & Analysis (SC26)
11月 15 - 11月 20
寄稿者
![]() 西克也
西克也
西克也はフェアチャイルド社、クレイ・リサーチ社、ベストシステムズ社など、30年以上に渡ってHPCに関する仕事に従事している。Hpcwire Japanの編集長として記事の作成と翻訳を行っている。
![]() 島田佳代子
島田佳代子
1999年~2007年まで英国在住。2001年よりスポーツ、旅、ビジネス、映画など幅広いジャンルで執筆活動を開始し、Hpcwire Japanでは主に日本のHPC業界が世界に誇る研究者、開発者の方々のインタビューを担当。
![]() 小柳義夫
小柳義夫
小柳義夫氏は40年以上に亘ってHPCに携わってきた研究者であり、日本のHPC業界における生き字引として有名。現在 高度情報科学技術研究機構に所属し、産業界のHPC推進にあたっている。
![]() 小西史一
小西史一
小西史一は、理化学研究所、東京工業大学においてHPCおよびバイオインフォマティクスに関する研究と教育に携わってきた研究者。2012年からフォトグラファーとしての活動を開始し、現在はIT技術・セキュリティのコンサルティング業務に携わっている。