
HPCの歩み50年記事一覧

スパコンリスト日本

記事寄稿について

新しいAI代替モデル: GPUは10-100倍削減されるが、結果は同じ
Doug Eadline オリジナル記事 「New Alternative AI Model: 10-100x Less GPUs, but Same Results」

市場がサウロンの目を生成AI(ChatGPTなど)に向ける前、伝統的なニューラルネットワークが最も注目されていた。この種のニューラルネットワークは、ある程度の “短期 “記憶を持つことが特徴で、リカレント・ニューラル・ネットワーク(RNN)と呼ばれている。アップルのSiriやGoogle翻訳のような多くの “スマート “テクノロジーで使われ続けており、決して時代遅れではない。
最近、「RWKV: Reinventing RNNs for the Transformer Era(RWKV:トランスフォーマー時代のRNNの再発明)」と題された論文が新たに発表され、10倍から100倍低い計算要件でGPTトランスフォーマーのように(並列化可能な)直接学習も可能な、GPTレベルのLLM性能を持つRNNについて述べられている。(つまり、GPUを少なくできる)。
この論文では、ChatGPTのようなトランスフォーマーが、ほとんどすべての自然言語処理(NLP)タスクに革命をもたらしたが、シーケンスの長さによって二次関数的にスケールするメモリと計算の複雑さに悩まされていることを説明している(つまり、モデルに多くのものを追加すると、計算により多くのものの二乗が必要になり、計算リソースが増える)。対照的に、リカレント・ニューラル・ネットワーク(RNN)は、メモリと計算要件に線形スケーリングを示す(つまり、モデルに多くのものを追加すれば、それに比例/線形量の計算リソースが必要になる)。しかし、RNNは並列化とスケーラビリティに限界があるため、トランスフォーマーと同等の性能を発揮することは難しい。本稿では、トランスフォーマーの並列化可能な効率的な学習とRNNの効率的な推論を組み合わせた、新しいモデルアーキテクチャ、Receptance Weighted Key Value(RWKV)を提案している。
| RWKVのロゴ (出典 https://wiki.rwkv.com) | |
最初の結果はかなり印象的だった。ポジティブな面では、RWKVアプローチは以下を提供する;
- 実行時およびトレーニング時のリソース使用量(VRAM、CPU、GPUなど)が少ない
- 大きなコンテキストサイズを持つトランスフォーマーと比較して、10倍から100倍低い計算要件
- どのようなコンテキスト長にも線形にスケールする(変換器は2次関数的にスケールする)
- 解答の品質と能力という点では同等である
- 他の言語(例:中国語、日本語など)では、既存のモデルよりも一般的によく訓練されている
RWKVモデルの現在の課題は以下の通りである:
- プロンプトの書式に敏感であるため、プロンプトの出し方を変える必要があるかもしれない。
- ルックバックを必要とするタスクには弱いので、プロンプトの順序を適宜変更する(例えば、「上の文書について、Xを実行しなさい」と言う代わりに、「下の文書について、Xを実行しなさい」と言う。
RWKV (wiki)は、Linux Foundationの下で、オープンソースでスポンサーがサポートする非営利の取り組みでもある。RWKVは、優れたパフォーマンス、高速推論、学習、VRAM、”無限 “の文脈長、自由な文埋め込みなど、RNNとトランスフォーマーの技術の長所を組み合わせることを目指している。さらに、LLMとは異なり、RWKVは100%アテンションフリーである。
RWKVのようなプロジェクトの意味は大きい。LLMモデルを訓練するために100個のGPUを購入(レンタル)する必要がある代わりに、RWKVモデルは10個以下のGPUコストで同様の結果を出すことができる。
HuggingFaceでは、事前学習され、微調整された7Bワールドモデル(100以上の言語のサンプルを含む、より大規模で多様なデータで学習され、部分的に命令学習されたベースモデル)が公開されている(モデルファイルのリンクはこちら HF Repoのリンクはこちら)。
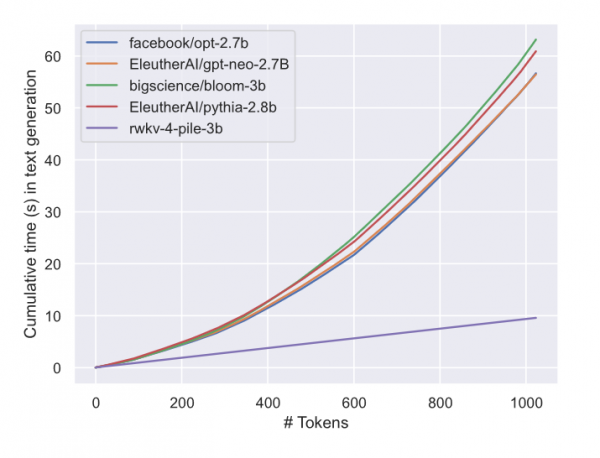 |
LLMのテキスト生成の累積時間。変換器とは異なり、RWKVは線形スケーリングを示す。(ソース https://arxiv.org/pdf/2305.13048.pdf)
特別イベント

寄稿者
![]() 西克也
西克也
西克也はフェアチャイルド社、クレイ・リサーチ社、ベストシステムズ社など、30年以上に渡ってHPCに関する仕事に従事している。Hpcwire Japanの編集長として記事の作成と翻訳を行っている。
![]() 島田佳代子
島田佳代子
1999年~2007年まで英国在住。2001年よりスポーツ、旅、ビジネス、映画など幅広いジャンルで執筆活動を開始し、Hpcwire Japanでは主に日本のHPC業界が世界に誇る研究者、開発者の方々のインタビューを担当。
![]() 小柳義夫
小柳義夫
小柳義夫氏は40年以上に亘ってHPCに携わってきた研究者であり、日本のHPC業界における生き字引として有名。現在 高度情報科学技術研究機構に所属し、産業界のHPC推進にあたっている。
![]() 小西史一
小西史一
小西史一は、理化学研究所、東京工業大学においてHPCおよびバイオインフォマティクスに関する研究と教育に携わってきた研究者。2012年からフォトグラファーとしての活動を開始し、現在はIT技術・セキュリティのコンサルティング業務に携わっている。