
HPCの歩み50年記事一覧

スパコンリスト日本

記事寄稿について

産総研ベンチマーク、Intel Optane; HPCとAIへの利点
John Russell

昨年4月、Intelはメインメモリ容量を増やし、DRAM速度に近いパフォーマンスを提供するために、バイトアドレス指定可能な不揮発性メモリであるOptane Data Center Persistent Memory Module(DCPMM)をリリースした。特に、この技術はシステムメーカーの間で関心を呼んでいるが、現在互換性があるのは特定のIntelプロセッサーとのみである。先週、産業技術総合研究所(産総研、AIST)は、DRAMのパフォーマンスの強みと弱みを反映した、DCPMMのベンチマークとなる論文を投稿した。
Optaneは、もちろん、 もともとMicron Technologyと共同開発された3D XPointメディアのIntelによる実装である。大まかに言えば、3D XPointは、高速であるが揮発性でより密度の低いDRAM技術と、より低コストで不揮発性のNANDフラッシュとの間の機能的ギャップを埋めようとしている。Optaneは、スタック(3D)トランジスタレス技術を使用してスペースを節約し、パフォーマンスを向上させている。
産総研によると、これまでDCPMMの性能に関する報告が少なかったため、このプロジェクトに着手したという。DRAMとの性能のギャップは大きいものの、NANDと比較した場合の利益も大きくなる。以下は、論文の結論部分からの抜粋である。
「Intel Optane DCPMMに関する以前の性能報告を補完するために、独自の測定ツールを用いて実験を行った。そして、ランダム読み取り専用アクセスの待ち時間は約374 nsであることが分かった。ランダムライトバックを伴うアクセスの場合は391 nsである。インターリーブメモリモジュールの読み取り専用アクセスと、書き込みを伴うアクセスの帯域幅は、それぞれ約38GB/秒と3GB/秒であった。」
「特に大規模なHPCやAIワークロードなど、多くのアプリケーションは、DCPMMで拡張された大容量のメインメモリの恩恵を受けることになりますが、DCPMMとDRAMとの間に大きな性能差があるため、システムソフトウェアの研究に新たな課題があります。現在、アプリケーションプログラムを用いた実験を行っており、今後の発表で詳細を報告していく予定です」と、産総研の広渕崇宏氏と高野了成氏は記している。
より明確な比較は、テストされたシステムの説明とともに以下の表に示されている。
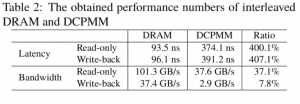
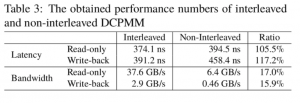

広渕氏と高野氏は、読み取り/書き込みレイテンシについて議論する際、ほとんどのCPU アーキテクチャではメモリのプリフェッチと順不同の実行が実行され、CPU コアで実行されているプログラムからメモリレイテンシが隠されることに注目している。彼らはこの問題を回避するための措置を講じた。
「待ち時間を正確に測定するために、ベンチマークプログラムは、これらの影響を抑制するように慎重に設計された。メインメモリの読み取りレイテンシを測定するには、次のように行う:
- 最初に、ターゲットメモリデバイスから一定量のメモリバッファを割り当てる。LLCミスを誘発するために、割り当てられたバッファのサイズをLLCのサイズよりも十分に大きくする必要がある。メモリバッファを64バイトのキャッシュラインオブジェクトに分割する。
- 2番目に、ランダムな順序でキャッシュラインオブジェクトのリンクリストを設定する。すなわち、リンクリストを横断することで、遠隔キャッシュラインオブジェクトへのジャンプを引き起こす。
- 3番目に、すべてのキャッシュラインオブジェクトをトラバースするための経過時間を測定し、キャッシュラインをフェッチするための平均待ち時間を計算する。ほとんどの場合、リンクリスト内の次のキャッシュラインオブジェクトのトラバーサル時に、LLC ミスが原因でCPU コアが停止する。このCPU ストールの経過時間は、メモリレイテンシである。」
詳細については、短いレポートを読むことをお勧めする。
産総研の論文へのリンク:https : //arxiv.org/pdf/2002.06018.pdf
特別イベント

寄稿者
![]() 西克也
西克也
西克也はフェアチャイルド社、クレイ・リサーチ社、ベストシステムズ社など、30年以上に渡ってHPCに関する仕事に従事している。Hpcwire Japanの編集長として記事の作成と翻訳を行っている。
![]() 島田佳代子
島田佳代子
1999年~2007年まで英国在住。2001年よりスポーツ、旅、ビジネス、映画など幅広いジャンルで執筆活動を開始し、Hpcwire Japanでは主に日本のHPC業界が世界に誇る研究者、開発者の方々のインタビューを担当。
![]() 小柳義夫
小柳義夫
小柳義夫氏は40年以上に亘ってHPCに携わってきた研究者であり、日本のHPC業界における生き字引として有名。現在 高度情報科学技術研究機構に所属し、産業界のHPC推進にあたっている。
![]() 小西史一
小西史一
小西史一は、理化学研究所、東京工業大学においてHPCおよびバイオインフォマティクスに関する研究と教育に携わってきた研究者。2012年からフォトグラファーとしての活動を開始し、現在はIT技術・セキュリティのコンサルティング業務に携わっている。