
HPCの歩み50年記事一覧

スパコンリスト日本

記事寄稿について

Aurora、Exascaleシステム:プログラミングに関するスライド
John Russell

2021年には、米国で最初に計画されているエクサスケールシステム「Aurora」がアルゴンヌ国立研究所で稼働する予定である。Cray(現在のHPE)とIntelが主要な契約先となっている。Auroraをはじめとするエクサスケールシステムのプログラムを作成するためには、その後どのようなことが必要になるだろうか。オンラインで開催されたIWOCL/SYCLcon 2020において、ANLのコンパイラ技術とプログラミング言語のリーダーであるHal Finkelは基調講演でこの話題に言及した。
Finkelは次のように述べている。「私がこの分野に入った数年前、スーパーコンピューティングの将来は、多くのコアを持つCPUベースのアーキテクチャに焦点を当てるのか、それともGPUやその他の種類の計算アクセラレータをベースにしたアーキテクチャに焦点を当てるのかという議論が続いていました。結論はまだ出ていませんが、ある意味で、今後のシステムはすべてGPUを使用することになるでしょう。つまり、より強力なGPUを駆動する強力なCPUを搭載したホットノードになるのです。」
異種混合性は、少なくとも今のところ、私たちがエクサスケールパフォーマンスを達成する方法である。
 |
|
| Hal Finkel、ANL | |
「少しの間、Auroraの計算ノードに注目する価値はあるでしょう」とFinkelは述べた。「GPUは、ノード上で低レイテンシの高帯域幅インターコネクトを使用して接続されています。さらに、このアーキテクチャは統一されたメモリサブシステムを特徴としており、CPUとGPUの両方でメモリをアドレス指定できるようになっています。これは私たちのプログラミングモデルにとって重要な意味を持ちます。それは、私たちのプログラムモデルが、高性能なユースケースにデータ移動機能を提供することに焦点を当てることができるようになる一方で、統合メモリシステムサブシステムがアプリケーションのデータ移動を可能にすることが重要な場合には、それを可能にすることができるようになることを意味するのです。」
ここで紹介するのは、Finkelのスライドとコメントのほんの一握りである(軽く編集されており、文字化けしていることをお詫びします)。彼のヒットリストには、並列処理、データマッピングと転送、レガシーコード(主にFortran)のサポート、プログラマの自由度とコンパイラ最適化の関係、データパラレルC ++(DPC ++)の台頭、Kokkos、Raja、SYCLなどが含まれている。Finkelの録画によるプレゼンテーションとスライド資料は、IWOCLのウェブサイトに掲載されている。この簡潔な概要はとても価値のあるものである。
Finkelのコメントやスライドに飛び込む前に、彼の結論を紹介する。
- 将来のスーパーコンピュータは、さまざまな分野で科学の進歩を進めていくことになるだろう。
- アプリケーションは、高性能ライブラリと並列プログラミングモデルに依存することになる。
- DPC++/SYCLは、将来のHPCプラットフォームにおいて重要なプログラミングモデルとなるだろう。
- コンパイラの最適化が、移植性の高いアプリケーションの開発をどの程度支援するのか、あるいはアルゴリズムの実装を明示的にパラメータ化して動的に構成する能力と比較して、どの程度理解していくことになるだろう。
- 並列プログラミングモデルは今後も進化を続け、データレイアウトやホスト中心ではないモデルのサポートが検討される。
Finkelは、スーパーコンピューティングを構成するものについて簡単に再確認することから始めた。
「従来の科学的スーパーコンピューティングは、大規模で緊密に結合された問題のためのコンピューティングです。大規模であることが重要です。この場合、大量の計算能力、大量のフロップス、高性能メモリの両方を意味します。しかし、緊密に結合されていることも重要です。それは、すべての異なる要素を高帯域、低遅延のネットワークで接続する必要があるため、計算密度が高くなければならないことを意味します。その結果、これだけの密度でこれだけの計算量を得るという、ユニークなアーキテクチャ上の課題に直面することになります」とFinkelは述べている。
「例えば、密な線形代数、スパース代数、高速フーリエ変換、粒子法などの、一般的なアルゴリズムクラスがあります。これらの手法のいくつかは、多くの異なる領域で使用されています。そして、これらの異なる手法が異なる方法でハードウェアにストレスを与えることを認識することが重要です。あるものは本当に高いフロップレートや高い計算能力を要求し、あるものは何よりもメモリサブシステムに本当に高い性能を要求し、またあるものは何よりもネットワークに高い性能を要求します。」
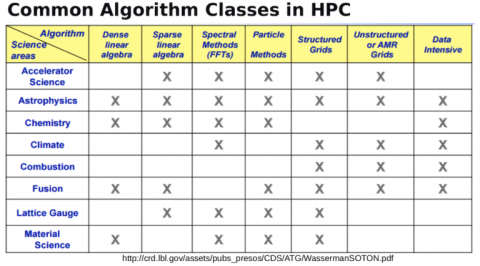
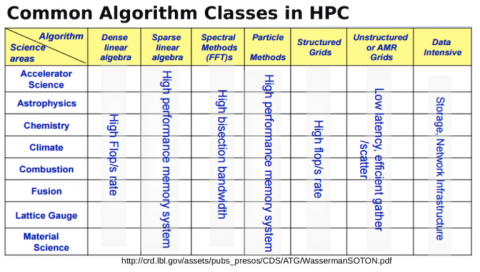
「ここでは、米国エネルギー省のコンピューティングエコシステム内のさまざまな研究所の今後のシステムのマップを見ることができます。Auroraは私たちが手に入れようとしているシステムであり、IntelとCrayによって提供されているのがわかりますが、他のベンダーも私たちのエコシステムの重要な部分である他のシステムを提供しています。重要なのは、これはIntel CPUとGPUを搭載したマシンであり、相互接続されている場合、すべてのノードを接続するために使用されるより大きなシステムメモリを持つことになります。さらに、最新のファイルシステムを搭載し、前例のない容量と性能をシステムに提供します」と彼は述べた。
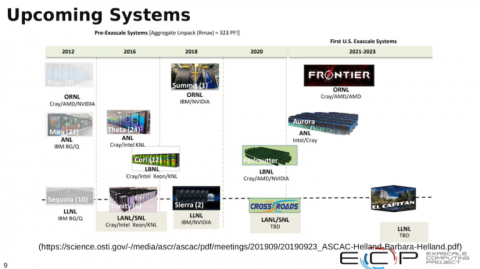
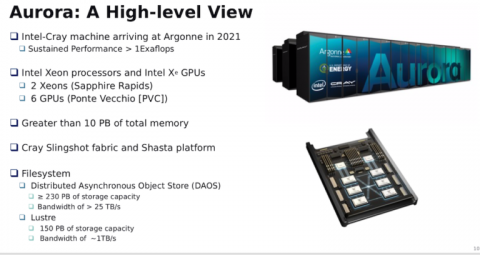
「ここで重要なことは、従来のシミュレーション、データ分析、大規模な機械学習など、当社が提供しているアプリケーションの様々な柱の上に、コンパイラ、サポートされているプログラミングモデル、オペレーティングシステム、ワークフロー、スケジューラ、オペレーティングシステムのカーネルなどに加えて、これらのアプリケーションはすべて、高性能なライブラリのセットの上に置かれているということを認識することです。これらすべてのシステム上のノード間プログラム、高性能ネットワークを利用するために使用されるモデルは、MPIを使用したプログラムに基づいていることを強調したいと思います」Finkelは述べている。
「MPI(メッセージ・パッシング・インターフェース)は、大規模なHPCシステムでノード間プログラミングを行うために選択されるモデルです。しかし、これはノード内並列処理のプログラミングには対応しておらず、特にGPUの並列処理には対応していません。私たちのワークロードの大部分がまだFortranでプログラムされていることを認めなければなりません。また、ほとんどの新しいコード開発が、C++を中心とした他の言語にシフトしているように見えるが、Pythonや他の様々な選択肢があるのも事実です。」

「私たちのシステムを提供しているIntelは、プログラムモデル、高性能ライブラリ、その他のインターフェイスをカバーしている、OneAPIと呼ばれるものをリリースしました。そして、それがAuroraをプログラミングするための主要なターゲットとなっています。先ほど、アプリケーションの多くが並列プログラミングモデルだけでなく、高性能な数学ライブラリに依存しているという話をしました。インテルはもちろん、最初にお見せした表にあったフーリエ変換や密な線形代数などのアルゴリズムを含む高性能な数学ライブラリを我々のシステムに提供します。さらに、データ分析や機械学習のワークロードをサポートするためのライブラリも提供されます」とFinkelは述べている。
「エクサスケールシステムで使用されることを期待しているプログラミングモデルには様々なものがあります。しかし、これらのモデルのすべてがすべての異なるシステムでサポートされるわけではありません。一方で、これらのモデルの中には、システム間での移植を考慮して特別に設計されたものもあります。そして、これらの様々なモデルが、構文的にも性能的にも、どの程度まで移植性があるのか、また移植性がないのかを探ることは興味深いことでしょう。」
「システム上にある重要なモデルの一つがOpenMPで、私はこれを2番目に重要なモデルと呼ぶことにしましょう。OpenMPを使用するアプリケーションは、ベースとなるプログラミング言語が異なります。CやC++、Fortranなどです。そして、すでに述べたように、Fortranをサポートすることが重要です。OpenMPはFortranでサポートされている主要な並列化モデルですが、CやC++コード、特にC++コードでは、さらに多くの選択肢があります。」



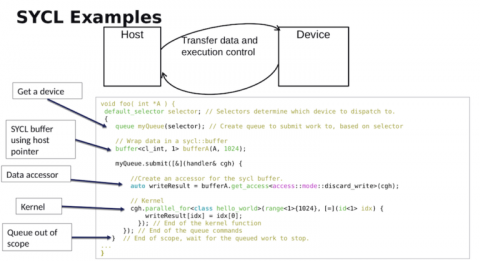
「重要なことは、私たちのシステムはデータ並列C++をサポートする予定で、これはKhronosグループの標準規格であるSYCLに基づいたプログラミングモデルです。SYCLには多くの異なる実装があり、今日の様々なCPUやNvidiaやAMDのGPUでSYCLを実行することが可能です。DPC++はSYCLの上に構築され、エクサススケールのスーパーコンピュータをプログラミングする上で非常に重要な多くの機能が追加されています。これには、名前付きラムダのリダクションのサポートに加え、統一されたメモリが含まれており、多くのシステムでより良いパフォーマンスを得るために、より高いレベルの抽象化レイヤーとサブグループを使用してSYCLとDPC++をラップすることができるようにするために重要となっています。」
「比較のために、OpenMPをカーネルとして並列化し、GPU上で実行するための簡単な例(下のスライド)を示します。ここでは、OpenMPの構文がそれほど単純ではないことがわかります。OpenMPを知っている人なら、ループを並列化するのはCPU上では簡単だということを知っているかもしれませんが、OpenMPをGPU上で動作させるためには、多くの追加の構文要素が必要です。これには、GPU 自体のためのさまざまな種類の並列化分解に加えて、データの動きを処理するためのデータマッピング句が含まれます。」
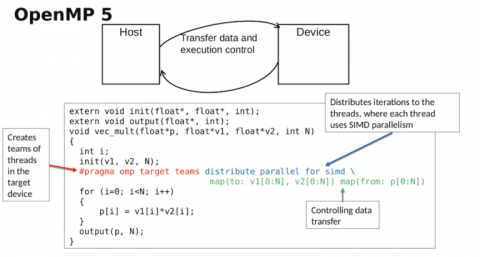
「ここに SYCL の対応するカーネルがあります。ここでは、作成されたさまざまなオブジェクトがいくつかあることがわかります。ここでは、作成されるオブジェクトの数が多いことがわかります。実行されているカーネルに加えて、コード内で明示されているワークキューがあり、ラムダとして渡され、最新の C++ の機能であり、このアクセサを使用することで、動的な依存関係グラフが構築され、カーネルが実行とデータ依存関係を持つことを可能にします」とFinkelは述べた。
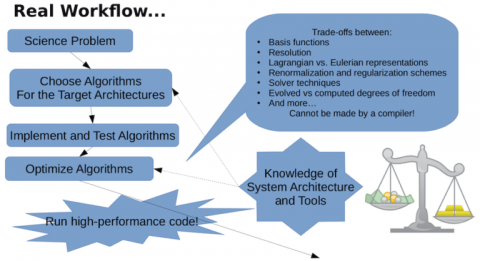
「性能の移植性についてお話したいと思います。特に、様々なアーキテクチャに対応したパフォーマンスポータブル並列プログラミングモデルとして設計されたSYCLの話をしているので、これは重要なトピックだと思います。パフォーマンス・ポータブル・アプリケーションの開発において、私たちの経験が何を示しているのかを理解することが重要だと思います。アプリケーションの開発は次のように考えるかもしれません。まず、科学的な問題を持ち、その問題を解決するために使用するアルゴリズムを選択し、アルゴリズムを実装してテストし、アルゴリズムを最適化し、最適化の過程でアーキテクチャやツールの知識を活用します。そして、それが終わったら、高性能なコードを作り、それを実行するのです。」
「しかし、一般的にはそうはいきません。問題なのは、アルゴリズムを最適化する自由度であり、それが完全に固定化されてしまえば、一般的には問題を最高の性能で解決するためには十分ではないということです。アルゴリズムと実装を採用する際には、基底関数や表現の選択、正則化のスキームやソルバーのテクニックなど、様々なトレードオフがあります。」
「これらはコンパイラではできない選択であり、少なくとも C++ や Fortran レベルで動作するコンパイラではできません。したがって、パフォーマンスの高いポータブルアプリケーションを作成することは確かに可能ですが、それらのアプリケーションは高度にパラメータ化されている傾向があり、様々なアルゴリズムの選択を公開してチューニングプロセスの一部として使用できることを理解することが重要です」とFinkelは語った。
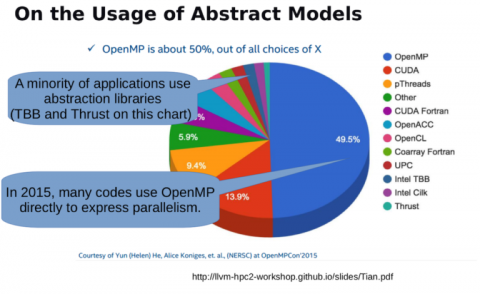
Finkelは、アプリケーションの提供方法が変化していることを認識することが重要だと強調した。「5年前の2015年頃にさかのぼって、私たちのシステムで使用していた並列プログラムを見てみると、ほとんどの人がCPU用の並列化を行っていて、OpenMPを直接使用していたことがわかるでしょう。何らかの抽象化ライブラリを使っていた人の割合はもっと少なかったのです」とFinkelは述べた。
「これは変わりつつあります。OpenMPの採用はさらに進んでいますが、多くのアプリケーションではOpenMPを直接使用しておらず、抽象化ライブラリの人気が高まっています。エネルギー省では、これらのうち少なくとも2つを開発しましたが、ここでは2つを明示しておきます。1つはRajaで、もう1つはKokkosと呼ばれます。1つはRajaで、もう1つはKokkosと呼ばれるものです。どちらもGPUを含む並列実行の抽象化を提供しています。これらは、生産的なプログラミング体験を提供するために、C++のラムダやその他の最新のC++の機能を利用しています。また、OpenMPや他のコンパイラディレクティブベースのスキームを使用することもできますが、DPC++やHIP、CUDAなど、各システムのバックエンドを実装するために、各システムの基礎となるプログラミングモデルを直接使用している可能性があります。」
「これらのモデルの開発は、標準C ++自体の開発にも影響を与えています。また、C ++ 17では、標準ライブラリに並列アルゴリズムが追加されました。これは、通常の標準逐次アルゴリズムを使用するのと同じ方法で使用できますが、アルゴリズムを並列またはベクトル化して実行するかどうかを指定する機能を備えています。」

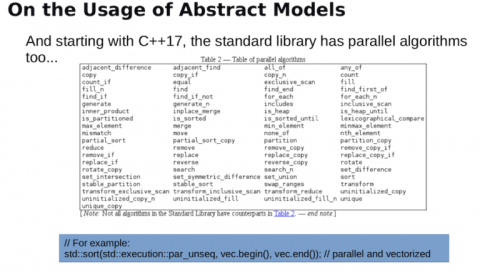
「異なるアーキテクチャ間で最適なコードを作成するのはプログラマの責任であると考えるかもしれません。ある程度プログラマはこれを試みようとします。ただし、制約があることを認識することが重要です。プログラマは抽象化レイヤーを使用して、大規模なチームにまたがって開発を管理しているので、最適なコードを直接作成できない場合があります。また、並行して実行するコードで、一緒に実行した方がメリットがありそうなコードは、別々のライブラリコンポーネントに含まれている場合があります。コンパイラが並列構成に対して実行する最適化には、さまざまな種類があります。例えば、ループを分割したり、融合したりすることが考えられます。カーネルについても同様に、カーネルの起動オーバーヘッドを最小化するために最適化したり、レジスタ圧を最小化したりするために、カーネルを分割したり融合したりしたいと考えるかもしれません。」
「プログラムやプログラムの流れが異なるカーネル間で分断されているという事実は、コンパイラがそうでなければ実行するであろうコンパイラの最適化を妨げる可能性があります。コンパイラが並列性を十分に理解して、カーネル外のコードからのデータに基づいて、カーネル内のエイリアシング結果をより良いポイントで得ることができるようにすることは、大きな利益をもたらします。」
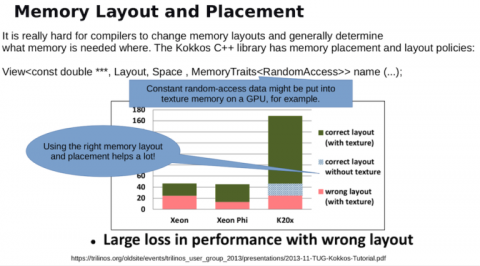
「また、コードやカーネルの最適化は、ループのネスト構造を変更するなど、単純に限定されるものではないことを認識しておくことが重要です。データのレイアウトも非常に重要です。データのレイアウトは、カーネルの構造やデータへのアクセス効率に大きな影響を与えます。そして、ここ(下のスライド)でわかるように、前述のC++の抽象化ライブラリの一つであるKokkosは、抽象化されたパフォーマンスポータブルな方法でデータレイアウトをカスタマイズする方法を提供しています。これが重要です。最適なデータレイアウトを使用して達成できるパフォーマンスは、異なるアーキテクチャ用にチューニングされたデータレイアウトを使用した場合のパフォーマンスよりも、はるかに優れたものになる可能性があります。」
Finkelのプレゼンテーションには、他にも多くのことが含まれている。最後に、彼は高性能ライブラリ、抽象化、パラメータ化の重要性を強調した。
「コンピューティング技術の限界を押し広げるために、アプリケーションはシステム上で高性能を達成するために、並列プログラミングモデルだけでなく、高性能なライブラリにも依存するようになるでしょう。DPC++は、将来のHPCシステムにおいて重要なプログラムモデルとなるでしょう。特に、私たちの次期システムであるAuroraではそうです」と彼は述べた。
「コンパイラの最適化が、ある意味ではアルゴリズムの実装を明示的にパラメータ化して動的に構成する能力と比較して、移植性の高いアプリケーションの開発をどの程度支援するかを理解していきます。そこにはトレードオフがあります。プログラマにプログラムの実行方法を明示的に選択する自由を与えれば与えるほど、コンパイラにそれを変更する自由が減り、その逆もまた然りです。これは、プログラミング言語やライブラリの設計における基本的なトレードオフです。並列プログラムモデルはデータレイアウトを提供するために進化し続け、将来的にはホスト中心ではないモデルが検討されるでしょう。そして、大きな進展が見られると期待しています。」
少なくともFinkelのスライド資料からは、来るべきエクサスケール・ビーストのためのプログラミング開発の方向性を素早く見て取ることができる。
Finkelの基調講演へのリンク:https : //www.youtube.com/watch?time_continue=1&v= oYWAJU-berw &feature=emb_logo
Finkelの基調講演スライドへのリンク:https : //www.iwocl.org/wp-content/uploads/iwocl-syclcon-2020-finkel-keynote-slides.pdf
IWOCL / SYCLcon 2020:https ://www.iwocl.org/#
特別イベント

寄稿者
![]() 西克也
西克也
西克也はフェアチャイルド社、クレイ・リサーチ社、ベストシステムズ社など、30年以上に渡ってHPCに関する仕事に従事している。Hpcwire Japanの編集長として記事の作成と翻訳を行っている。
![]() 島田佳代子
島田佳代子
1999年~2007年まで英国在住。2001年よりスポーツ、旅、ビジネス、映画など幅広いジャンルで執筆活動を開始し、Hpcwire Japanでは主に日本のHPC業界が世界に誇る研究者、開発者の方々のインタビューを担当。
![]() 小柳義夫
小柳義夫
小柳義夫氏は40年以上に亘ってHPCに携わってきた研究者であり、日本のHPC業界における生き字引として有名。現在 高度情報科学技術研究機構に所属し、産業界のHPC推進にあたっている。
![]() 小西史一
小西史一
小西史一は、理化学研究所、東京工業大学においてHPCおよびバイオインフォマティクスに関する研究と教育に携わってきた研究者。2012年からフォトグラファーとしての活動を開始し、現在はIT技術・セキュリティのコンサルティング業務に携わっている。