
HPCの歩み50年記事一覧

スパコンリスト日本

記事寄稿について

最新プロセッサ動向 PCクラスタワークショップ in 柏
2021年6月18日に、PCクラスタコンソーシアム主催イベント「PCクラスタワークショップin柏2021」がオンラインで開催。インテル株式会社、日本AMD株式会社、エヌビディア合同会社、アーム株式会社の4社がPCクラスタプラットフォーム最新動向を紹介。本講演の模様をレポートする。
『最先端のパフォーマンスを実現するインテル XPU戦略』
 |
トップバッターとして、インテル株式会社データセンター・セールス・グループHPCテクニカル・ソリューション・スペシャリスト力 翠湖氏がインテル XPU戦略について講演。
冒頭、力氏は社会環境が大きな変革期を迎える中で「HPCの“今”」を紹介。現在、ワクチン開発や脱炭素化に伴う高効率化のバッテリー開発などが活発化し、HPCとAIを融合する取組みが進んでいる。
従来のHPC用途だけではなく、多岐にわたる問題解決に向け大規模な計算システムの重要性が高まっている。
■インテル XPUアーキテクチャー
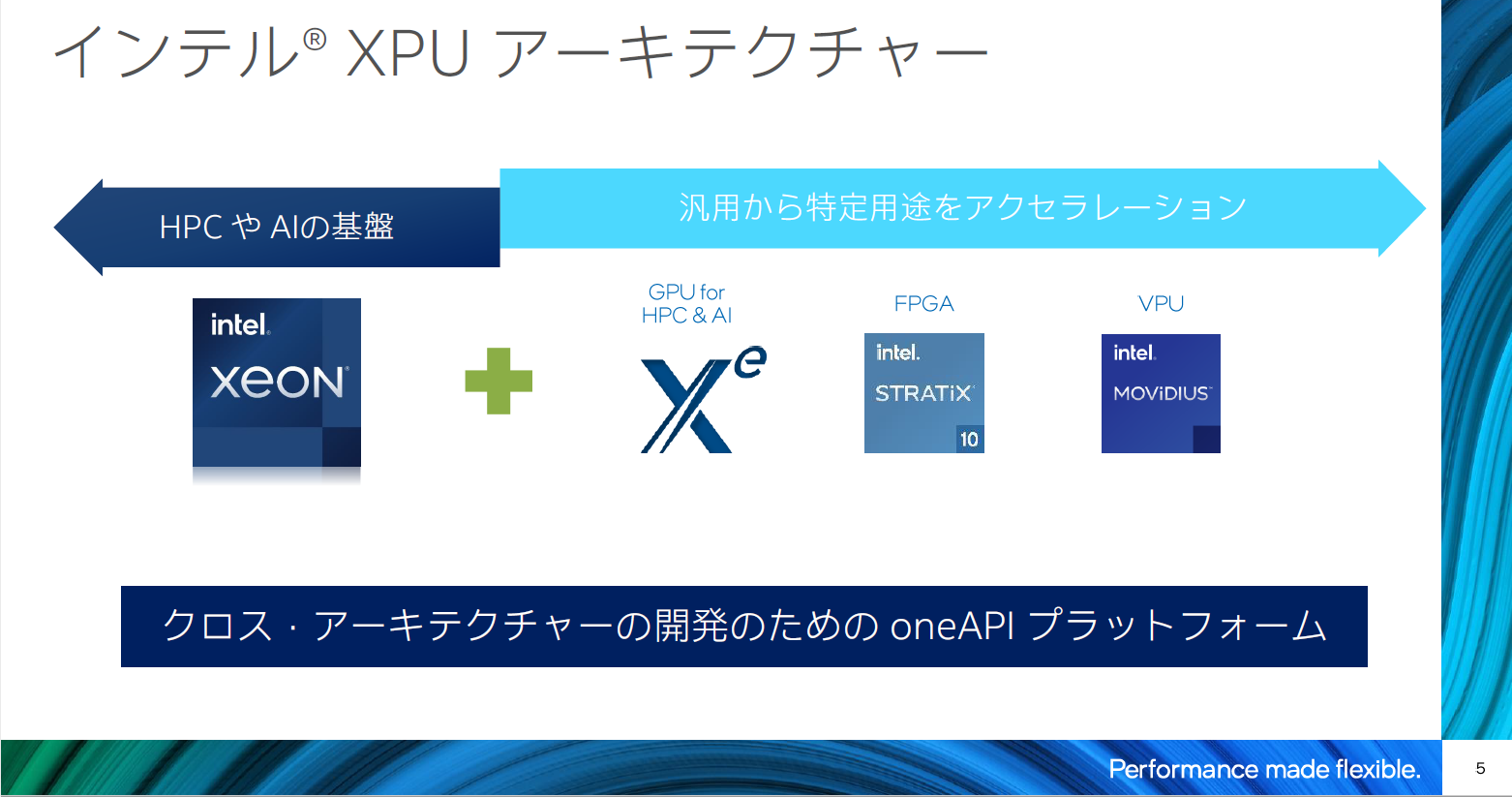 |
インテルはHPCやAIの基盤となるXeonプロセッサーのコアアーキテクチャー改善や、プロセス微細化で高い性能を提供し続けるだけでなく、AI命令の追加、アクセラレーション機能の搭載、ソフトウエアの最適化などにより、新しい需要に対応している。
CPUだけでは対応しきれない、多岐にわたるワークロード対応のため「Xeと呼ばれる
GPU」「書き換え可能なFPGAを提供するSTRATiX10」「MOVIDIUS」など、データセンターからエッジまで、特定用途に特化した製品を開発し「XPU戦略」として提供している。
■インテルXeonロードマップ
 |
続いてXeonのロードマップを紹介。力氏は「2021年4月に第3世代 インテル® Xeon® スケーラブル・プロセッサー(開発コード名: Ice Lake)を正式発表した。『Ice Lake』に続き『Sapphire Rapids』CPUを計画しており、更なるイノベーションを加速させる技術提供を予定。Ice Lakeは国内ユーザーの東京大学・大阪大学・産業技術総合研究所に先行提供しており、使用運転する中で好評を得ている」と述べた。
■第3世代インテル®Xeon® スケーラブル・プロセッサーのスペック
 |
第3世代 インテル® Xeon® スケーラブル・プロセッサーは、製造プロセスの微細化・メモリスピード・バンド幅の改善・セキュリティ機能強化の他、AVX-512動作周波数アップやメモリ立ち上がり機能改善など、さらなる技術革新を行っている。
CPUだけではなく、DDR4ソケットに対応した第2世代インテル®OptaneTMパーシステント・メモリ、PCIe 4.0に対応したインテル®OptaneTM SSD P5800X、イーサネット800シリーズ対応など、プラットフォームの足回りとなる製品も提供している。
力氏は「第3世代 インテル® Xeon® スケーラブル・プロセッサーはインテルとして自信を持っておすすめできる仕上がりとなっている。ユーザーの目的に合わせた、より良い性能やソリューションをインテルは提供します」と語った。
■第3世代インテルXeon スケーラブル・プロセッサーベンチマーク
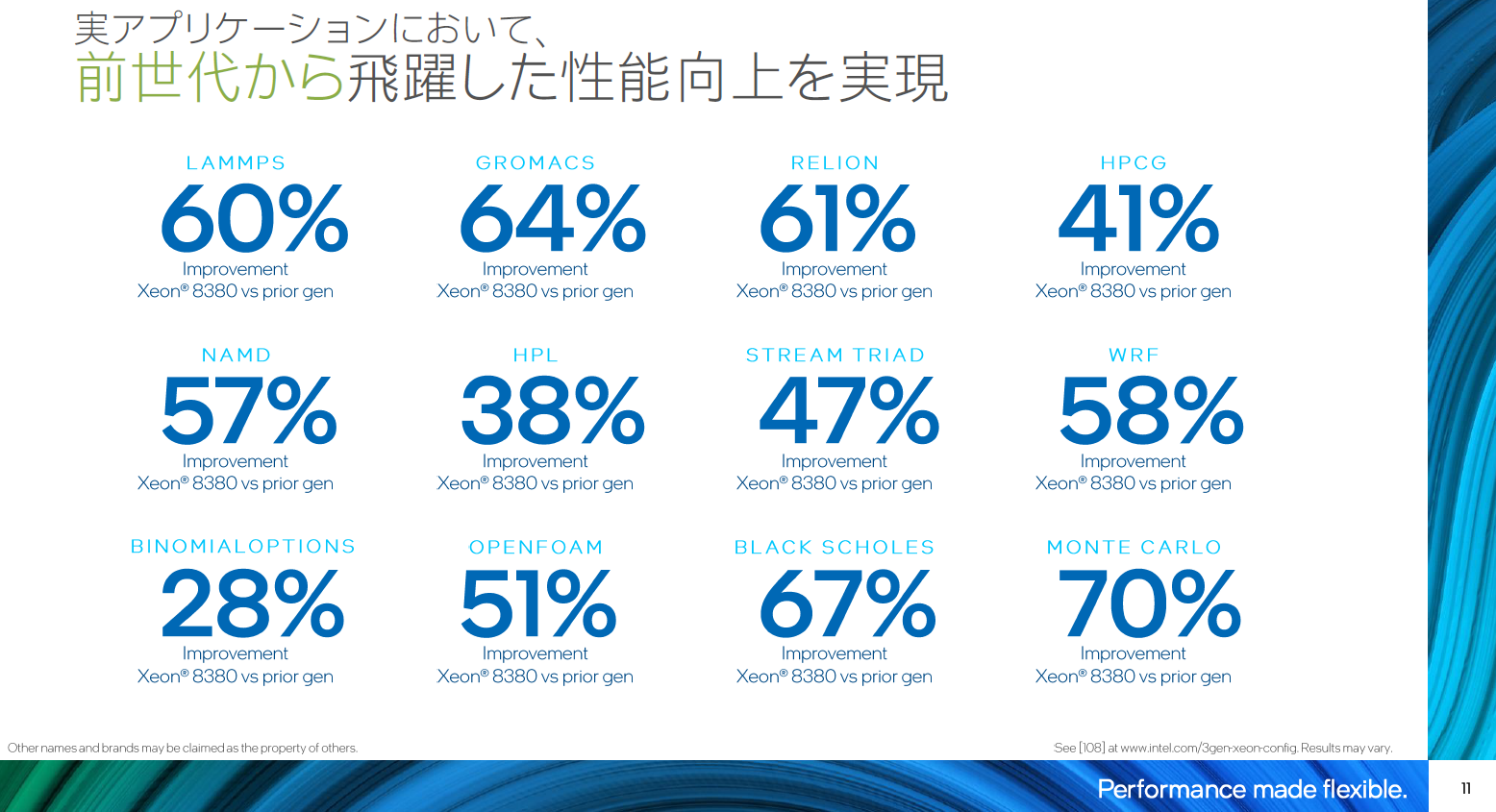 |
第3世代 インテル® Xeon® スケーラブル・プロセッサーは前世代の第2世代 インテル® Xeon® スケーラブル・プロセッサー(開発コード名:Cascade Lake)と比べ、同社ベンチマークにおいて38%~41%の性能向上を達成している。研究や業務に使われる実アプリケーションにおいても、飛躍的な性能向上を遂げている。
力氏は「性能が比較的バンド幅に依存する気象系シミュレーションWRFで58%向上、流体力学シミュレーションのOPENFOAMで51%向上、生命科学・物質科学のGRPMACSで64%向上と非常に良い性能が出ている。第3世代 インテル® Xeon® スケーラブル・プロセッサー以前のCPUをお使いのユーザー様は進化を実感して頂ける」と述べた。
講演の締め括りに「世界は変革期を迎えHPCやAIに対する期待は今後ますます高まっていく。より良い社会の実現に向け、インテルは技術的進歩に貢献し続けていくのでご期待ください」と抱負を語った。
『第3世代AMD 「EPYC 7003シリーズ」プロセッサー概要』
 |
続いて日本AMD株式会社コマーシャル営業本部 関根正人氏が、第3世代AMD EPYCプロセッサー技術である7003シリーズプロセッサーについて紹介。最新プロセッサーの概要ならびにベンチマーク結果など、第2世代からの性能向上について解説する。
冒頭、関根氏はZENコアのロードマップについて紹介。2017年に登場した初代ZENコアは、シンプルなデザイン・高性能・低消費電力・高密度化と高いスケーラビリティを実現している。小型ノートPCから大型サーバーまで、幅広く利用されているハイパフォーマンスCPUコアだ。
本CPUを進化させ、第3世代(ZEN3)EPYC「コードネーム“Milan”」を2021年3月15日にリリース。また第4世代(ZEN4) EPYC「コードネーム“Genoa”」の開発も順調に進んでいるという。
■ZENコアIPC性能強化の歴史
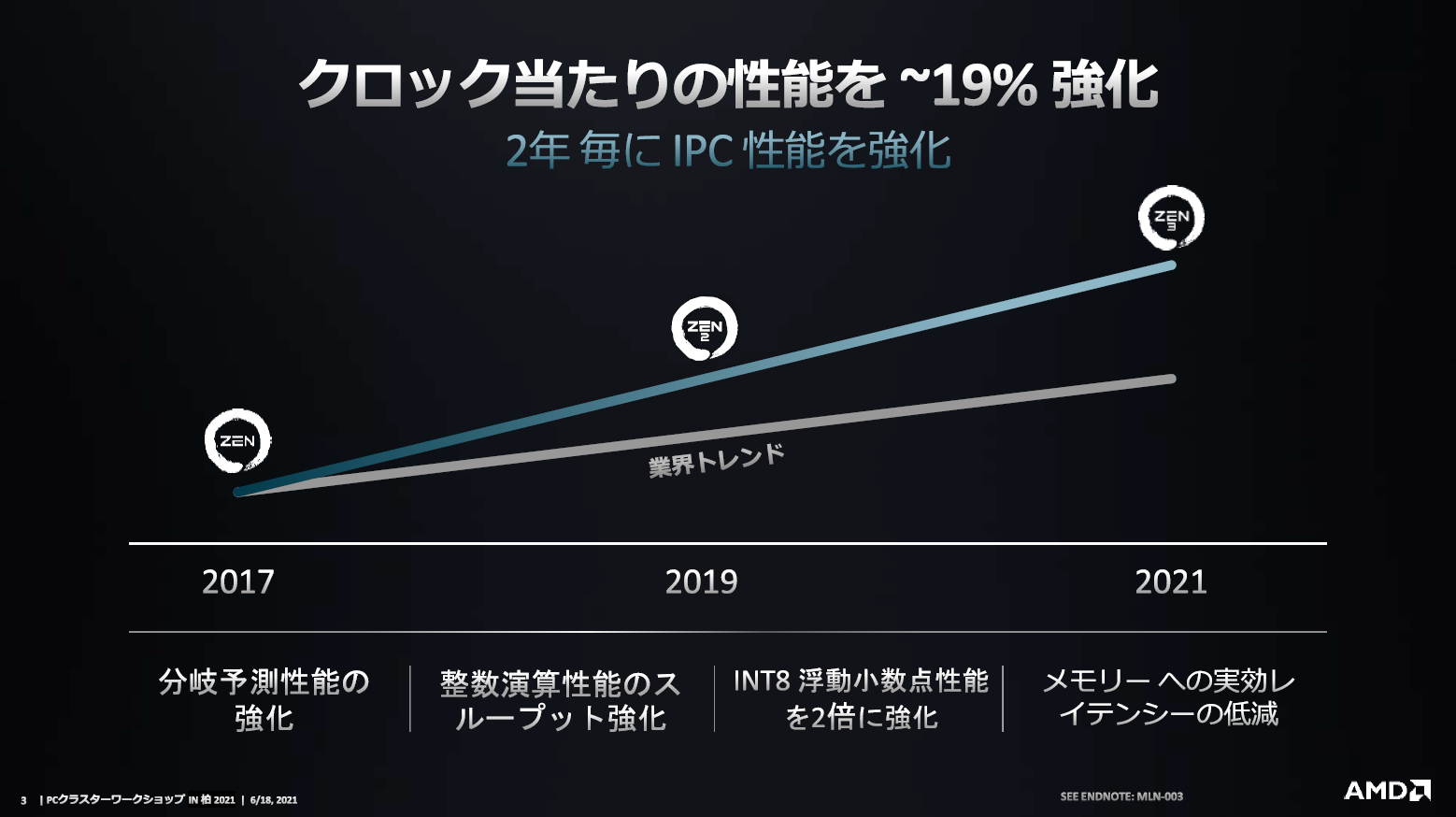 |
AMDは初代ZENコアをリリースしてから、およそ2年ごとにクロック当たりの処理性能を大きく強化してきた。
関根氏は「前世代CPUコアに対して、52%性能強化したのが初代ZENコア。ZEN2はZEN1に対し15%向上し、ZEN3はZEN2に対し19%性能向上している。本IPC性能強化は業界トレンドを大きく上回る進化である」と語った。
■第3世代AMD EPYC プロセッサー新機能紹介
 |
次にAMD EPYC プロセッサー新機能を紹介。ZEN3コアを採用した第3世代EPYCは、同社の業界標準ベンチマークテストでトップスコアを達成。AMDは「世界最高性能のプロセッサー」と謳う。
メモリ性能強化も行っており、CPU内部バスとメモリクロック同期を実現しDDR4-3200を搭載した際に、メモリアクセス遅延が前世代より短縮されている。
セキュリティ強化・6チャネルメモリ搭載時のメモリインターリブ機能が新たに追加されており、第2世代EPYC7002シリーズと完全ソケット互換のため、第2世代・第3世代共に各OEMから併売している。
■第3世代AMD EPYCプロセッサーベンチマーク
 |
続いてEPYCプロセッサー性能について、商用HPCアプリケーションベンチマーク結果を紹介。同社で「AMD競合製品の第2世代28コア」と「EPYC第3世代32コア」の2ソケット1ノード環境での比較を、各商用HPCアプリケーションで実施。
コア数がほぼ同等であるものの、ベンチマーク結果は約4割からほぼ倍ほどEPYC第3世代32コアが上回る結果となっている。関根氏は「圧倒的な性能を提供するZEN3コア」と同社CPU性能の高さをPRした。
講演後のQ&Aで関根氏は「NDAを締結したお客様には、長期ロードマップや製品紹介が可能。将来に向けポジティブなお話ができるので、ご要望のお客様はぜひ問合せください。」の言葉で締め括った。
『次世代のデータサイエンスを加速するNVIDIAプロダクトの紹介』
 |
3番目の講演者として、エヌビディア合同会社HPC/AIネットワーク プロダクトマーケティングディレクター岩谷正樹氏が登壇。
GTC21で発表したデータサイエンス形態を変革させるインネットワーキングソリューションである「NVIDIA BlueField-3 DPU」、機械学習をより加速する全く新しい「NVIDIA Grace CPU」など、NVIDIA最新プロダクトを紹介。
冒頭、岩谷氏は「昨今、データサイエンスの世界が急速に変わりつつあり、データが加速度的に増え解析手法も複雑化・高度化している」と課題を述べる。本環境に対応するため、NVIDIAはGPUやCPUなどデータセンターを司る計算リソースに加え、より計算を高速する新しいプロセッサーとしてDPU(Data Processing Unit)を開発している。
■NVIDIA BlueField-3 DPU
 |
NVIDIA BlueField-3 DPUは、最速400Gb/sのスループットを持ったData Processing Unitが載ったインターフェースカードだ。Ethernet版・InfiniBand版の両方をリリース予定で、Ethernet版は400Gb/s 暗号化アクセラレーション機能を備え高速化を実現する。
従来のBlueField-2と比較し「Armコアが8から16コア」「スイッチがPCleGen4.0からGen5.0」に変更され、最新のDDR5メモリを搭載している。NVIDIA BlueField-3 DPUは、2022年1月~3月に発売を予定している。
BlueFieldの特徴として、CPU・GPUが搭載されたホストからセキュリティ機能を完全に分離することで、ホスト側に負荷を与えることなく高セキュア通信を実現する。従来のHPC計算ノードは、高セキュアかつ外部リスクから免れた状態でワークロードが実行可能だ。
■NVIDIA Grace CPU
 |
続いてNVIDIA Grace CPUについて紹介。AI解析で使われるパラメータモデルは年々増加しており、現在は約1750億個と言われている。今のペースでパラメータモデルが増加した場合、2023年までに100 兆個を超える規模となり、既存設計の限界を超える巨大モデルになるという。
現在NVIDIAがリリースしているA100ではメモリに搭載しきれず、ホスト側のメモリを使うことになるが、PCleを利用するためボトルネックが生じる。本ボトルネック解消のため、NVIDIAは新しいCPUであるGraceを開発した。
Graceは巨大なスケールのAIやHPCのアクセラレーテッドコンピューティングのために設計されたCPUだ。AIとデータサイエンスのための新しいコンピューティングアーキテクチャで、ネクストGPUと一緒に利用することで高速なAI解析ワークロードが実現可能となる。
■NVIDIA Graceオーバービュー
 |
GPU・Grace・ホスト側につながるメモリを高速なバスで接続可能となり、4個のGraceに対し2000GB/秒のスループット性能を実現。システムメモリからGPUへの帯域が、30倍に高速化された性能を発揮する。
大規模な AI や HPC のワークロードに対応するCPU Graceは2023年にリリースを予定だ。同年にスイスの国立スーパーコンピューターセンターで、Graceを使ったシステム導入が既に予定されているという。
■NVIDIAのロードマップ
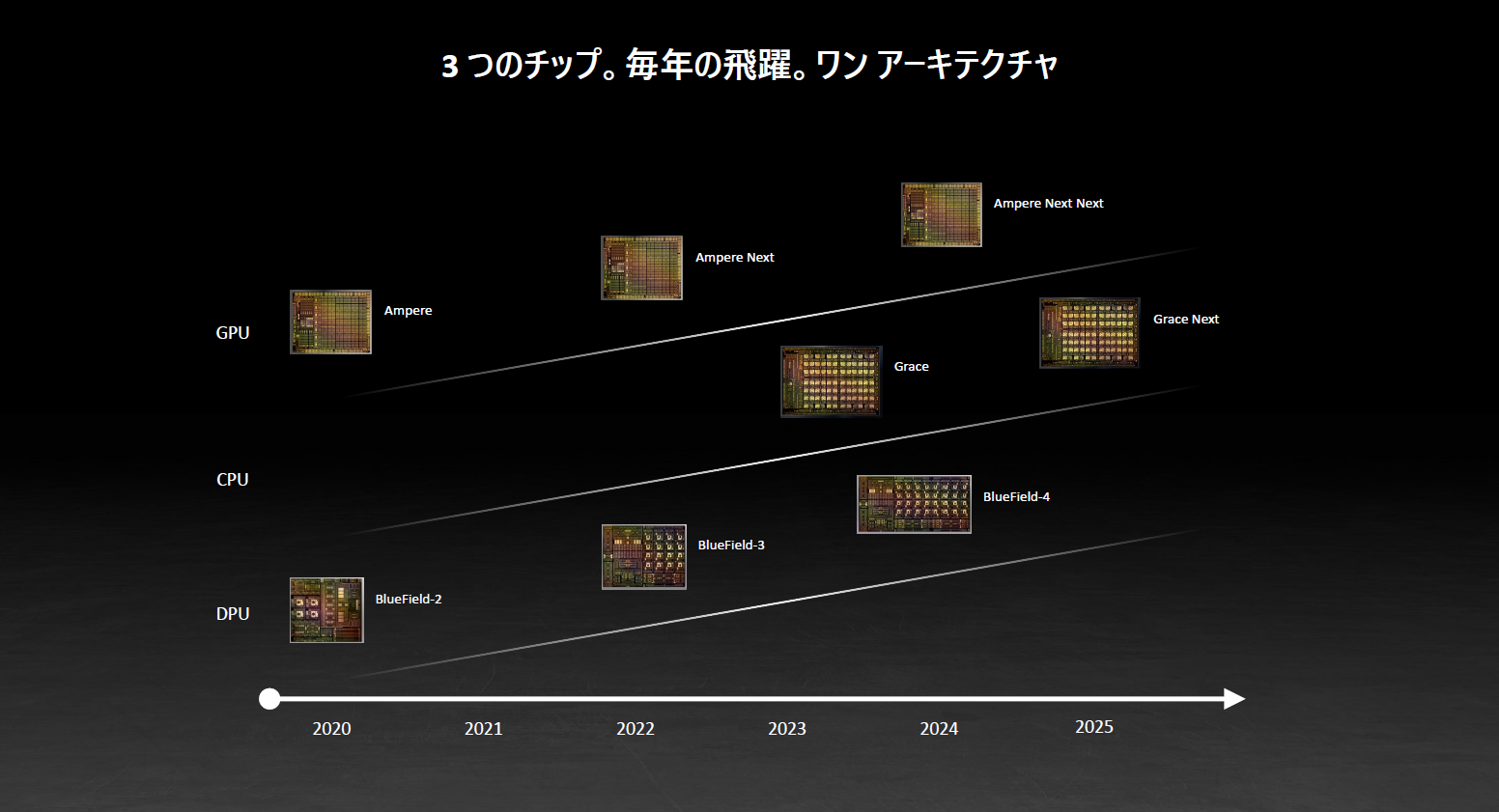 |
講演の最後にロードマップを紹介。岩谷氏は「NVIDIAはGrace CPU・BlueField ・GPUについて、2年に1回アーキテクチャーを一新する予定で開発を進める」と計画を紹介し、講演を締め括った。
『次世代Armアーキテクチャー「Armv9」』
 |
]最後の講演者として、アーム株式会社 鯨岡俊則氏が次世代Armアーキテクチャーである「Armv9」を紹介。
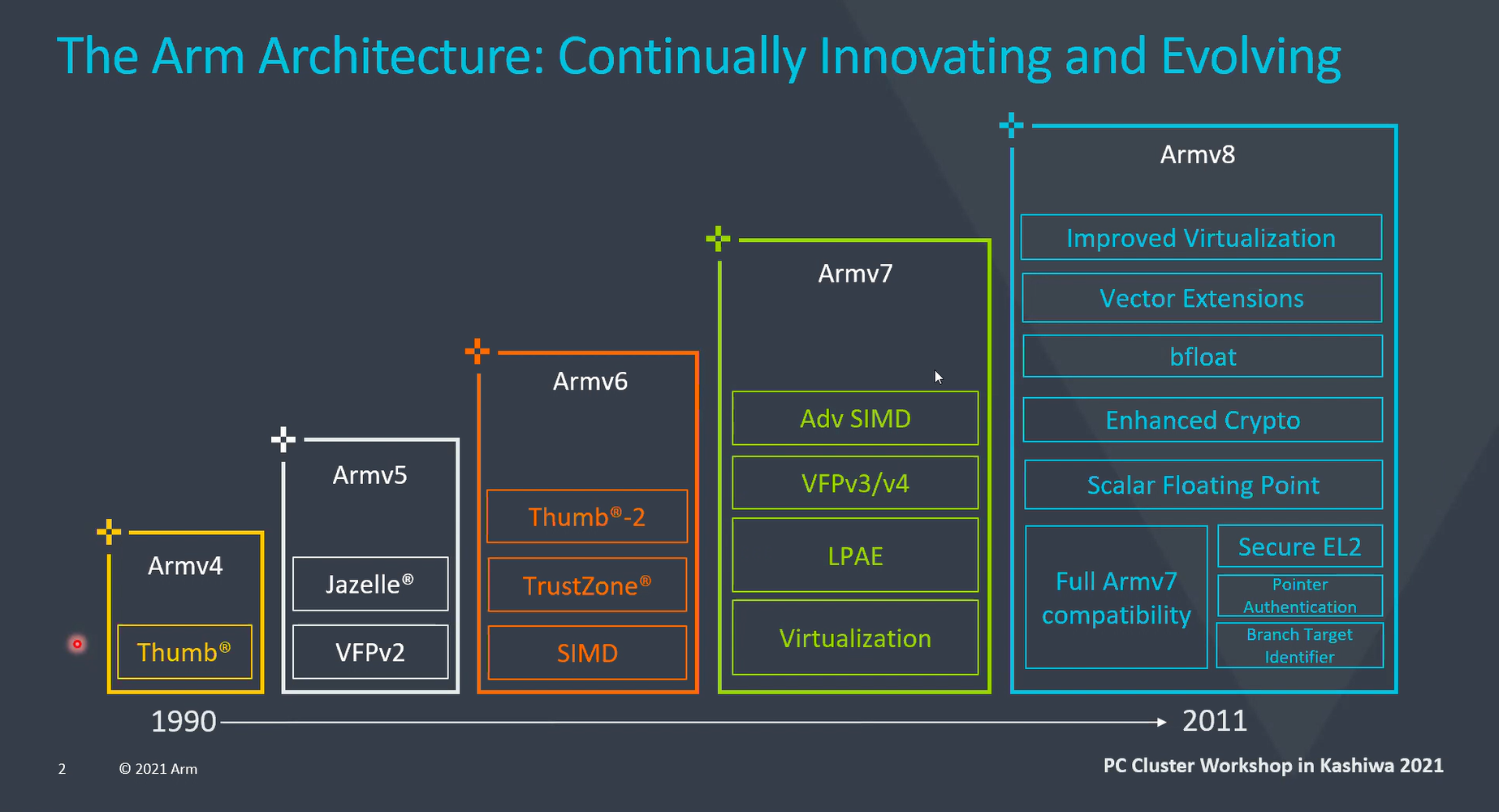
冒頭、鯨岡氏はArmアーキテクチャーの歴史について説明。Armアーキテクチャーはx86やRISC-Vと比較されるようにArm CPUの命令セットだ。時代のコンピューティングやイノベーションに合わせ、1990年から約10年スパンで機能拡張を繰り返してきた。
現在入手できるチップはArmv8世代であり、Armv7とフルの互換性を持ちながら仮想化の強化、富岳にも使われている富士通と共同開発したベクター演算の強化、機械学習の強化などを行い現在に至っている。
鯨岡氏は「富岳やAWSで利用されているサーバーグレードCPUのGravitonもArmv8世代である」と補足した。
■全てのワークロードに対応するセキュアなアーキテクチャー「Armv9」
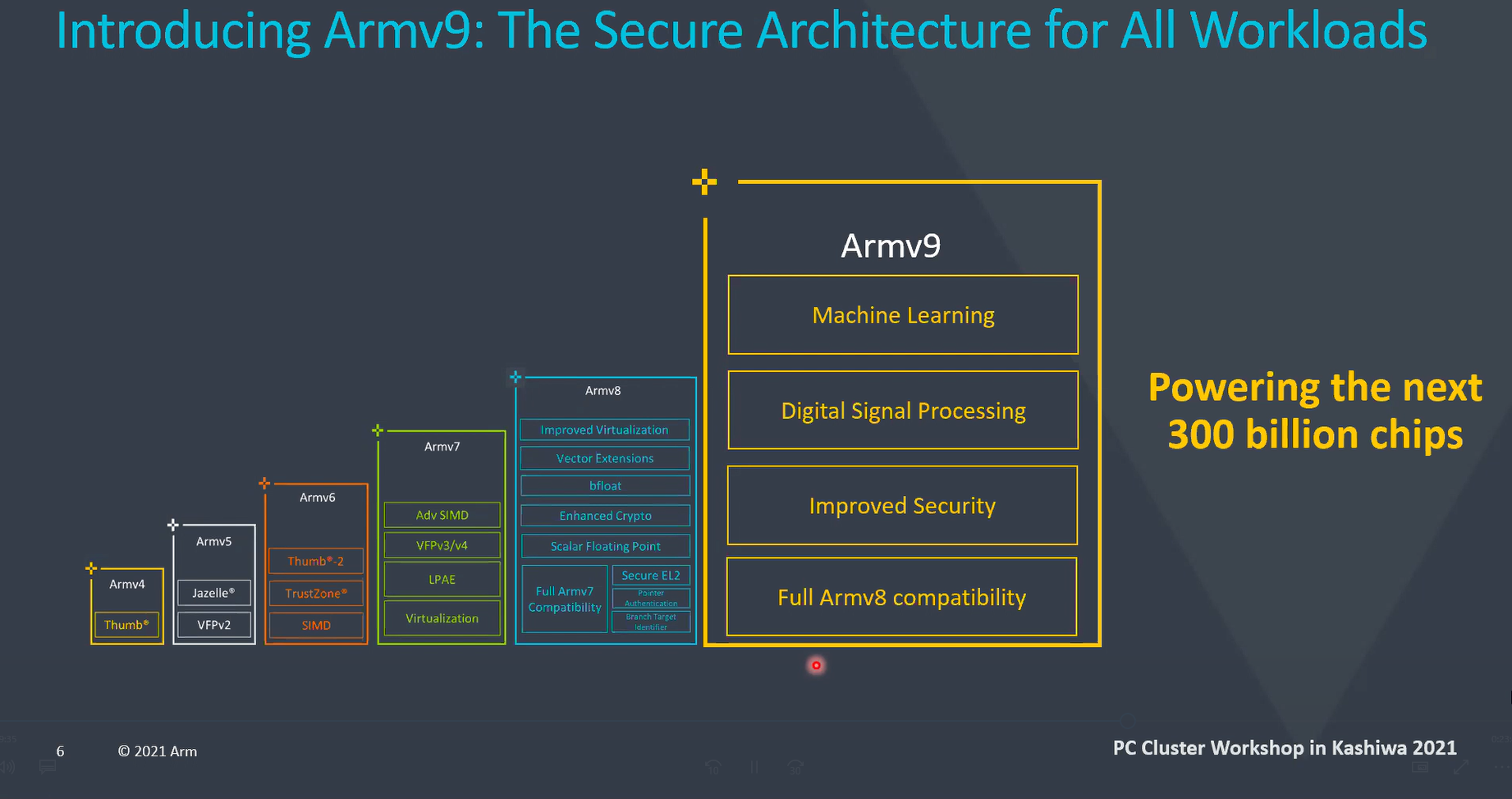 |
Armv9はArmv8の機能とフルの互換性を保ち、機械学習やAI・スマートシティで要求されるデジタル信号処理にセキュアに対応するアーキテクチャーだ。
Armv9は今後10年間でArmエコシステムから提供される3,000億個のチップに対応し、信頼性の高いコンピューティングプラットフォームとなる。鯨岡氏は「Armのチップは過去30年間で、世界中に1,900億個が出荷されている。今後10年間で更に出荷が加速していく」と述べた。
■ベクター演算の重要性
 |
昨今、機械学習やAIが人気となっているが、ArmもマイクロコントローラーからスパコンまでをカバーするCPUのほか、Mali GPU、Ethos NPUなどのIPを提供している。さまざまな局面で専用デバイスとして組合せ、各パートナーが開発できるよう準備を進めている。
DSP、機械学習、xRなどのワークロードが次世代コンピューティングとして採用されていくが、その中でベクター演算が重要となる。富士通と共同開発した「SVE」と呼ばれるベクター演算を高速化するコンポーネントは、Armv9でも「SVE2」として強化し採用されるという。
鯨岡氏は「富岳で動いているアプリケーションは、そのままスマートフォンやその他デバイスでネイティブに動く。またArmデバイス同士でセキュリティを高められる機能も付いている。開発者の観点からすると、チップレット構成におけるアプリケーションのユーザービリティがArmアーキテクチャーの利点である」と語った。
■次世代Armアーキテクチャー「Armv9」まとめ
 |
最後に鯨岡氏は「Armはそれぞれのコンピューティングに将来必要となるビルディングブロックを提供しながら標準化を進める。各パートナー様が『尖ったデバイス』を作れるようサポートし、高度なデータセキュリティを高める機能を提供していきたい」と抱負を述べた。
特別イベント

寄稿者
![]() 西克也
西克也
西克也はフェアチャイルド社、クレイ・リサーチ社、ベストシステムズ社など、30年以上に渡ってHPCに関する仕事に従事している。Hpcwire Japanの編集長として記事の作成と翻訳を行っている。
![]() 島田佳代子
島田佳代子
1999年~2007年まで英国在住。2001年よりスポーツ、旅、ビジネス、映画など幅広いジャンルで執筆活動を開始し、Hpcwire Japanでは主に日本のHPC業界が世界に誇る研究者、開発者の方々のインタビューを担当。
![]() 小柳義夫
小柳義夫
小柳義夫氏は40年以上に亘ってHPCに携わってきた研究者であり、日本のHPC業界における生き字引として有名。現在 高度情報科学技術研究機構に所属し、産業界のHPC推進にあたっている。
![]() 小西史一
小西史一
小西史一は、理化学研究所、東京工業大学においてHPCおよびバイオインフォマティクスに関する研究と教育に携わってきた研究者。2012年からフォトグラファーとしての活動を開始し、現在はIT技術・セキュリティのコンサルティング業務に携わっている。