
HPCの歩み50年記事一覧

スパコンリスト日本

記事寄稿について

AIを活用したHPCと科学技術のインフレーション
Doug Eadline オリジナル記事「AI-augmented HPC and the Inflation of Science and Technology」

宇宙の体積が指数関数的に膨張し、その後減速するという初期宇宙のインフレーションモデルは、誰もが知っている。AIを活用したHPC(略してAHPC)は、従来のHPC数値計算手法ではアクセスできなかった(計算可能な)科学的宇宙に新たな空間を創造し、拡大を始めている。
数値計算の世界では、未来を予測する一つの方法は、過去に基づいて線を引くことである。常に完璧というわけではないが、将来スーパーコンピュータがHPCベンチマークをどの程度の速度で実行するかを予測することは、多くの場合、線の延長線上にある。これらの線は計算効率とボトルネックを反映し、最終的に将来の短期的な例外を形成する。他の多くのアプリケーションにも同じことが言える。コードをベンチマークし、線を引き、合理的な期待値を設定する。
HPCの線形宇宙は、インフレ期に入ろうとしている。HPCの能力と到達範囲は、生成AI(すなわちLLM)の使用によって加速するだろう。幻覚はともかく、よく訓練されたLLMは、科学者やエンジニアにとっては異質な関係や特徴を見つけることができる。LLMはデータの「特徴らしさ」を認識することができる。自動車、犬、コンピュータ、糖蜜といった異なる種類の物体に共通する「速度」のような特徴を考えてみよう。これらにはそれぞれ「速度らしさ」がある。LLMは「速度らしさ」を認識し、全く異なるデータ間の関連、関係、類推を行うことができる。(例えば、「車は犬より速い」とか、「このコンピューターは糖蜜のように遅い」とか)。
データには、我々が知らない「暗い特徴」がある。適切な訓練を受ければ、LLMはデータ中の「暗い特徴」を認識し、利用することに長けている。つまり、科学者やエンジニアには見えないが、それでもそこに存在する関係性や「特徴性」である。
AI拡張HPCは、HPCの計算領域を拡大するために、これらの暗黒機能を使用する。しばしば「代理モデル」と呼ばれるこれらの新しいツールは、最適な候補を提案することで、科学者やエンジニアに潜在的な解決策への近道を提供する。例えば、LLMは、解決策に至る1万通りの可能性のある経路の代わりに、実行可能な解決策の分野を数桁狭めることができ、かつては計算不可能な問題であったものを解決可能な問題にすることができる。
さらに、基礎モデルの使用はNP困難問題のように感じられる。モデルの作成には計算コストがかかるが、テスト結果は些細なものであることが多い(あるいは、少なくとももっと短時間で可能である)。AIは、より少ない計算量で解を提供したり、より扱いやすい最適化された解空間を推奨したりすることで、従来のHPC計算領域を支援するために使用される。
このような目覚ましいブレークスルーは、今まさに起こっている。ChatGPTやLlamaのような大規模で一般的なAIモデルを作ろうとするのではなく、AIを活用したHPCは、特定の科学的領域に対処するために設計された専門的な基礎モデルに焦点を当てているようだ。ここでは、そのような3つのモデルの例を説明する。
科学者やエンジニアは、基礎モデルが認識できる「暗黒機能性」を見ることができないため、AI拡張HPCの限界や影響は未知数である。進歩は直線的ではない。後述するように、初期の基礎モデルは、計算科学の領域が大きく拡大することを予見している。
プログラム可能な生物学: EvolutionaryScale ESM3
生物科学の究極の目標は、配列(DNA)、構造(タンパク質)、機能(細胞、臓器)を理解し、ナビゲートする能力である。これらの各分野は、それぞれに活発な研究を行っている。これらのプロセスを組み合わせることで、プログラム可能な生物学の新時代が開かれるだろう。どのような新しい技術にもリスクはつきものだが、その見返りには、これまで不可能だった新薬や治療法、医薬品などが含まれる。
新会社EvolutionaryScale社は、機械やマイクロチップやコンピュータープログラムと同じように、生物学を第一原理からエンジニアリングできる可能性を秘めたライフサイエンス基礎モデルESM3(EvolutionaryScale Model 3)を開発した。このモデルは、生物と生物群からサンプリングされた約28億のタンパク質配列でトレーニングされ、以前のバージョンよりも大幅にアップデートされた。
生物工学の試みは難しい。ヒトゲノム(およびその他)に基づき、タンパク質フォールディングは、タンパク質が生物学的環境においてどのような形状をとるかを解明しようとする。このプロセスは計算集約的であり、最も成功した取り組みのひとつであるAlphaFoldは、ディープラーニングを用いてプロセスを高速化した。
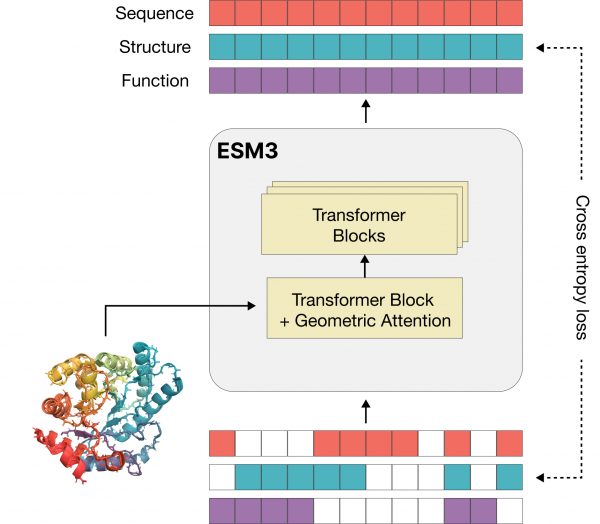 |
| ESM3は、タンパク質の配列、構造、機能を共同で推論するマルチトラックトランスフォーマーである。(出典:EvolutionaryScale) |
コンセプトの証明として、EvolutionaryScale社は、新しい緑色蛍光タンパク質(GFP)の生成について述べた新しいプリプリントを発表した(現在プレビュー中、bioRxivへの投稿待ち)。蛍光タンパク質は、クラゲやサンゴの光る色の原因であり、現代のバイオテクノロジーにおいて重要なツールである。ESM3で同定された新しいタンパク質は、最も近い既知の天然蛍光タンパク質と58%しか類似していない配列を持ちながら、天然のGFPと同様の明るさで蛍光を発する。このプロセスは同社のブログで詳しく説明されている。
膨大な数の配列と構造の中から、純粋な偶然(あるいは試行錯誤)によって新しいGFPを生成することは事実上不可能である。EvolutionaryScale社は、「自然界に見られるGFPの多様化率から、この新しい蛍光タンパク質の生成は、5億年以上の進化をシミュレートすることに相当すると推定している」と述べている。
EvolutionaryScale社の紹介ブログでは、安全性と責任ある開発について触れられている。実際、E3M3のような基礎モデルが、がんを治療するための新たな候補を作り出すよう求められることがあるのと同様に、致死性物質、つまり現在知られている物質よりも致死性の高い物質を作り出すよう求められることもある。AIの安全性は、基盤モデルが改良され、より普及し続けるにつれて、より重要になるだろう。
EvolutionaryScaleはオープンな開発を約束し、その重みとコードをGitHubに置いている。また、オープンなESMモデルを使用している8つの独立した研究活動もリストアップしている。
天気予報と気候予測 マイクロソフトClimaX
AIを活用したHPCのもう一つの例は、マイクロソフトのClimaXモデルだ。オープンソースとして提供されているClimaXモデルは、気象・気候科学のためにトレーニングされた最初の基礎モデルである。
最先端の数値気象・気候モデルは、地球上のさまざまなシステムの既知の物理学に基づき、エネルギーと物質の流れを関連付ける大規模な微分方程式系のシミュレーションに基づいている。一般的なように、このような膨大な計算には、大規模なHPCシステムが必要となる。このような数値モデルは成功しているが、基盤となるハードウェアが最新であるため、解像度に限界があることが多い。機械学習(ML)モデルは、データと計算の両方のスケールから恩恵を受ける代替手段を提供できる。最近、短・中距離気象予報のためにディープラーニングシステムをスケールアップする試みが成功した。しかし、ほとんどのMLモデルは、特定のデータセットにおける特定の予測タスクのために訓練されたものであり、気象や気候のモデリングに必要な汎用的な有用性に欠けている。
多くのテキストベースの変換器(LLM)とは異なり、ClimaXはGoogle Researchの修正Vision Transformer(ViT)モデルに基づいている。ViTはもともと画像データを処理するために開発されたものだが、気象予測用に改良されている。
ClimaXは、様々な用途に対応するため、様々な予測タスクに対して微調整が可能であり、いくつかのベンチマークにおいて、最先端の予測システムよりも優れた性能を発揮する。例えば、同じERA5データを使用した場合、中解像度であっても、ClimaXはIFS(The Integrated Forecasting System 全球数値気象予測システム)と同等かそれ以上の性能を発揮する。
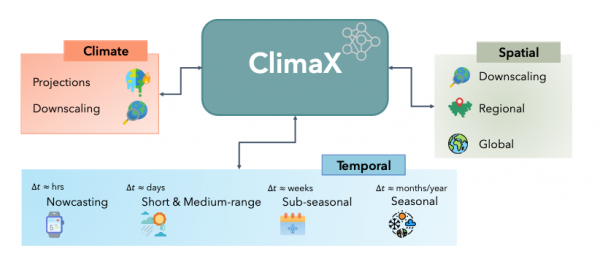 |
| ClimaXは、あらゆる気象・気候モデリングタスクの基礎モデルとして構築されている。気象面では、地球規模でも地域規模でも、さまざまな解像度で、さまざまなリードタイム地平線の標準的な予測が含まれる。気候面では、長期予測や、低解像度モデル出力からのダウンスケーリング結果の取得が標準的なタスクである。(出典:マイクロソフト) |
ClimaXは、あらゆる気象・気候モデリングタスクの基礎モデルとして構築されている。気象面では、これらのタスクには、さまざまな解像度で、さまざまなリードタイム地平線の標準的な予測が含まれる。気候面では、長期予測や、低解像度モデル出力からのダウンスケーリング結果の取得が標準的なタスクである。
アルゴンヌにおけるCOVID-19バリアント探索
米国エネルギー省(DOE)のアルゴンヌ国立研究所の科学者と共同研究者チームによって、領域固有の基礎モデルのもう一つの成功した利用法が実証された。このプロジェクトでは、SARS-CoV-2の変異体発見に役立つLLMを開発した。
COVID-19のように、すべてのウイルスは(宿主細胞の機械を使って)繁殖しながら進化する。世代を重ねるごとに突然変異が起こり、新しい変異体が生まれる。しかし、中には元のウイルスよりも致死性や感染力が強いものもある。特定の変異体がより危険または有害とみなされる場合、それは懸念変異体(VOC)として表示される。このようなVOCを予測することは、起こりうる変異が非常に大きいため難しい。実際、鍵となるのは、厄介な可能性のある変異体を予測することである。
研究チームは、アルゴンヌ研究所のスーパーコンピューティングとAIのリソースを利用して、LLMモデルを開発・適用し、ウイルスがどのように変異して、より危険な変異型やより伝播性の高い変異型になるかを追跡した。アルゴンヌの研究チームと共同研究者は、COVID-19遺伝子を解析し、VOCを迅速に特定できる初のゲノムスケール言語モデル(GenSLM)を作成した。このモデルは、1年分のSARS-CoV-2ゲノムデータで訓練され、このウイルスの様々なウイルス株の違いを推測することができる。さらに、GenSLMは、VOC同定と同様の他の予測タスクに変更・適用可能な最初の全ゲノムスケール基礎モデルである。
以前は、GenSLMがなければ、VOCの同定は、すべてのタンパク質を個別に調べ、興味のある変異があるかどうかを確認するために、それぞれの変異をマッピングする必要があった。このプロセスは膨大な労力と時間を消費するが、GenSLMはこのプロセスを容易にするのに役立つはずである。
図はGenSLMモデルが様々なウイルス株の区別を推測できることを示している。
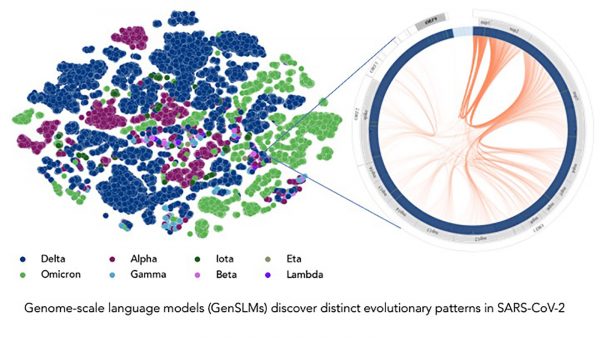 |
| このモデルは、1年分のSARS-CoV-2ゲノムデータに基づいて、様々なウイルス株の区別を推測することができる。左の各ドットは、配列決定されたSARS-CoV-2ウイルス株に対応し、変異型ごとに色分けされている。(画像:Argonne National Laboratory/Bharat Kale, Max Zvyagin and Michael E. Papka) |
計算生物学者アルビンド・ラマナサンが率いるこの研究チームは、アルゴンヌの同僚に加え、シカゴ大学、エヌビディア社、セレブラス社、イリノイ大学シカゴ校、北イリノイ大学、カリフォルニア工科大学、ニューヨーク大学、ミュンヘン工科大学の共同研究者から構成されている。研究内容の詳細は彼らの論文を参照されたい: GenSLMs: ゲノムスケールの言語モデルからSARS-CoV-2の進化ダイナミクスが明らかになった。なお、このプロジェクトは、ウイルスがどのように進化するかを迅速に特定する新しい手法により、2022年ゴードン・ベル特別賞(ハイパフォーマンス・コンピューティングに基づくCOVID-19研究部門)を受賞している。
膨張する科学
この3つの例はすべて、それぞれの領域を大幅に拡大した見方を提供する。現在のところ、LLM基礎モデルの構築と実行は、まだ専門的な作業である。ハードウェアが利用可能になったにもかかわらず、新しいモデルや拡張されたモデルの作成は、ドメインの実務家にとって容易になるだろう。これらの基礎モデルは、特定のドメインの「暗黒機能性」を認識し、科学と工学が新たな展望へと拡大することを可能にする。科学技術の宇宙は、もっともっと大きくなろうとしている。
特別イベント

寄稿者
![]() 西克也
西克也
西克也はフェアチャイルド社、クレイ・リサーチ社、ベストシステムズ社など、30年以上に渡ってHPCに関する仕事に従事している。Hpcwire Japanの編集長として記事の作成と翻訳を行っている。
![]() 島田佳代子
島田佳代子
1999年~2007年まで英国在住。2001年よりスポーツ、旅、ビジネス、映画など幅広いジャンルで執筆活動を開始し、Hpcwire Japanでは主に日本のHPC業界が世界に誇る研究者、開発者の方々のインタビューを担当。
![]() 小柳義夫
小柳義夫
小柳義夫氏は40年以上に亘ってHPCに携わってきた研究者であり、日本のHPC業界における生き字引として有名。現在 高度情報科学技術研究機構に所属し、産業界のHPC推進にあたっている。
![]() 小西史一
小西史一
小西史一は、理化学研究所、東京工業大学においてHPCおよびバイオインフォマティクスに関する研究と教育に携わってきた研究者。2012年からフォトグラファーとしての活動を開始し、現在はIT技術・セキュリティのコンサルティング業務に携わっている。