
HPCの歩み50年記事一覧

スパコンリスト日本

記事寄稿について

AIにはデータの問題がある、アペンの報告書は指摘
Alex Woodie オリジナル記事「AI Has a Data Problem, Appen Report Says」

アペンが発表したレポート「2024年におけるAIの現状」によると、AIは米国企業にとって優先事項かもしれないが、データ管理やAIモデルを訓練するための高品質なデータを入手することの難しさが、AIの願望を達成するためのより大きなハードルになりつつあるという。
AIはデータに依存している。独自のAIモデルをトレーニングするにしても、他人のモデルをファインチューニングするにしても、あらかじめ構築されたモデルでRAGテクニックを使うにしても、AIの導入を成功させるにはデータを持ち込む必要がある。
データ・ラベリングとアノテーション・ソリューションのプロバイダーであるアペンは、組織がAIソリューションを構築または展開する際に直面するデータ・ソーシングの課題を最前線で見てきた。アペンは、今年で4年目を迎える年次レポート「State of AI(AIの現状)」において、これらの課題を文書化している。
同社がハリス・ポールに依頼し、今年初めに米国企業のIT意思決定者500人以上を対象に実施した調査に基づく「2024年におけるAIの現状」報告書によると、AIのデータ課題は新たな低水準に達している。
 |
|
|
Appen 2024年におけるAIの現状レポートはこちらからダウンロードできる |
|
例えば、調査対象者が報告したデータの平均精度は、過去4年間で9ポイント低下しているという。また、データの利用可能性の欠如は、同社が2023年の「AIの現状」レポートを発表して以来、6%上昇している。
品質と可用性の低下は、構造化データを基にした単純な機械学習プロジェクトから、非構造化データを基にしたより複雑な生成AIプロジェクトへと、過去2年間でシフトしたことが原因かもしれないと、アペンの戦略担当副社長シー・チェン氏は言う。
「われわれは現在、多くの非構造化データを目にしているが、あまり標準化されていません」とチェン氏はHPCwireの姉妹誌であるBigDATAwireに語っている。「これらのデータセットを実際に構築するには、多くの専門知識や専門知識が必要になります。それが、データ精度の低下の原因だと思います。現在、人々が必要とするデータは、以前よりもはるかに複雑なデータになっているからです。」
アペンはそのレポートの中で、AIデータパイプラインに関して新たに生じているボトルネックについても取り上げている。企業は、データにアクセスすること、データを適切に管理すること、データを扱う技術的リソースを持つことなど、複数のステップで成功するために苦労している。アペンは、2023年以降、データのソーシング、クリーニング、ラベリングに関するボトルネックが10ポイント増加すると予測している。
この減少の原因を1つに絞るのは難しいが、チェン氏は、組織が着手しているAIイニシアチブの種類が全般的に増加していることが、主要な原因の1つではないかと分析している。
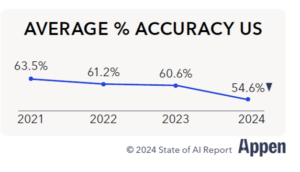 |
|
| データの質は低下している(グラフ提供:アペン『2024年のAIの現状』レポート) | |
「その多くは、設計・開発されるユースケースがより多様化しているという事実に関連している可能性があります」と彼女は言い、「企業が設計する各特定のユースケースには、実際にそのユースケースをサポートするためのカスタムデータが必要になります」と言う。
アペンはデータアノテーションとラベリング分野の巨人で、30年近い経験を持つ。現在、生成AIが高品質な学習データの必要性を急増させているが、アペンは、個々のプロジェクトには、同社の得意とする独自の学習用データセットが必要であることを認識している。アペンの「AIの現状」レポートから明らかになった数字は、多くの組織がそれに苦慮していることを示している。
「設計・開発されるユースケースは多様化しており、企業が設計する特定のユースケースごとに、そのユースケースを実際にサポートするためのカスタムデータが必要になります」と、テンセントとアマゾンでAIに携わった後、1年前にアペンに入社したチェン氏は言う。
「多様性があるということは、実際にこれらのモデルを構築するためには、それをセットアップするための堅牢なデータ・パイプラインが必要だということです」と彼女は続ける。「個々のユースケースごとに、データにまつわる一連のステップがあります。そして、より多くの人々がこれらのモデルを導入するにつれて、既存のデータパイプラインではこれらのすべてが必ずしも成熟していないという事実に出くわすかもしれません」と彼女は続ける。
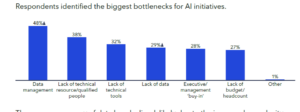 |
|
| データのボトルネックはますます大きくなっている(グラフ提供:アペン『2024年のAIの現状』レポート) | |
構造化データで従来の機械学習アプリケーションを開発するために、このようなデータパイプラインとスキルを開発した組織は、非構造化データを使用して生成AIアプリケーションを開発するには、異なるタイプのデータパイプラインと異なるスキルが必要であることに気づいている、とチェン氏は言う。
「ちょっとした移行期になると思います」と彼女は言う。「しかし、それは非常にエキサイティングなことです。」
アペンの調査では、生成AIユースケースの採用は2023年から2024年にかけて17%増加したと結論づけている。今年、調査した組織の56%が生成AIユースケースを持っていた。最も人気のある生成AIユースケースは、社内のビジネスプロセスの生産性を高めるためのもので、53%のシェアがあり、41%はビジネスコストを削減するために生成AIを使用していると回答している。
生成AIが拡大するにつれて、AI導入の成功率は低下することがアペンで明らかになった。例えば、2021年のAIの現状レポートでは、平均55.5%のAIプロジェクトが導入に至ったが、2024年には47.4%に減少した。また、「意味のある」投資収益率(ROI)を達成したAIプロジェクトの割合も、2021年の56.7%から2024年には47.3%に低下している。
アペンのライアン・コルンCEOは最近、ビッグデータ報告会に出演した。
この数字はデータの課題を反映しているとチェン氏は言う。「多くの関心が寄せられ、多くの人々が様々なユースケースに取り組んでいるにもかかわらず、導入に至るまでにはまだ多くの課題があります。そしてデータは、何かがうまく展開できるかどうかという点で、かなり中心的な役割を果たしているのです」と彼女は言う。
報告書によると、組織がAIに使用しているデータには3つの種類がある。アペンによると、27%のユースケースが事前にラベル付けされたデータを使用しており、30%が合成データ、41%がカスタム収集データを使用している。
誰も見たことのないカスタム収集データを採用する能力は、強力な競争優位性をもたらすと、アペンのライアン・コルン最高経営責任者(CEO)は最近のビッグデータ報告会に出演した際に述べた。
「世の中には一般に入手可能なデータが大量にあり、それはすべてのモデルビルダーによって消費されています」「しかし、生成AIにおける本当の競争優位性は、特注データにアクセスする能力です。我々が見ているのは、どうやってオーダーメイドのデータを見つけるかという点で、非常に競争力のあるアプローチだということです。そして、現実世界の、人間が収集したデータが、そのデータコーパスの重要な一部になっていると見ています。」
アペンの「2024年のAIの現状」はこちらで読める。
関連項目
Appen CEO Ryan Kolln Discusses the Data Annotation and Labeling Biz on the Big Data Debrief
特別イベント

寄稿者
![]() 西克也
西克也
西克也はフェアチャイルド社、クレイ・リサーチ社、ベストシステムズ社など、30年以上に渡ってHPCに関する仕事に従事している。Hpcwire Japanの編集長として記事の作成と翻訳を行っている。
![]() 島田佳代子
島田佳代子
1999年~2007年まで英国在住。2001年よりスポーツ、旅、ビジネス、映画など幅広いジャンルで執筆活動を開始し、Hpcwire Japanでは主に日本のHPC業界が世界に誇る研究者、開発者の方々のインタビューを担当。
![]() 小柳義夫
小柳義夫
小柳義夫氏は40年以上に亘ってHPCに携わってきた研究者であり、日本のHPC業界における生き字引として有名。現在 高度情報科学技術研究機構に所属し、産業界のHPC推進にあたっている。
![]() 小西史一
小西史一
小西史一は、理化学研究所、東京工業大学においてHPCおよびバイオインフォマティクスに関する研究と教育に携わってきた研究者。2012年からフォトグラファーとしての活動を開始し、現在はIT技術・セキュリティのコンサルティング業務に携わっている。