
HPCの歩み50年記事一覧

スパコンリスト日本

記事寄稿について

ムーアの法則は健在であり、IntelのHPCの利用が存続させている
Mark Stettler and Shesha Krishnapura, Intel
編集者注:ムーアの法則が弱体化していることは、多くのHPCにとって既知の事実とされている。驚くことではないが、Intelは同意していない。SC15のIntelのDiane Bryantの基調講演で明らかだ。この解説ではIntelのシニア技術者が、進歩がムーアの法則と共に確固として残っていることを保証し、ムーアの法則を健全に維持する課題を克服するために着実にHPCを発展させることにIntelが依存していることを強調しようとしている試みにおいて遭遇した課題について検証している。それは終わりのない一方が他方を進展させると彼らが主張する高潔な共生サイクルなのだ。まあ、見てみよう。さらなる分析については、Tiffany Traderの記事、「TOP500 Reanalysis Shows ‘Nothing Wrong with Moore’s Law」を見て欲しい。John Russell
Moores Law diagram Intel
半導体の機能向上を推し進める経済における1965年のGordon Mooreの記事は、トランジスタのスケールの影響の面において乱暴な予言であることが分かっている。40年後の2004年に、Intelは単一チップ上に1億5千万個のトランジスタを搭載する90ナノメートルのプロセスを使ったマイクロプロセッサを構築した。現在では、最小で14ナノメートルの特性と持つプロセッサには、13億5千万個のトランジスタを積んでいる。これはたった11年間の技術開発で、6倍の精度で10倍の数のトランジスタを入れ込んだこととなる。そして、これはIntelが作る最大密度でさえないのだ。これを書いている時点での筆頭は、18コアのIntel XeonプロセッサE7-8890 v3で、22ナノメートルのプロセスで55億個のトランジスタを搭載し、すべてを52mm x 45mmの中にパッケージしている。さらに印象的なのは、この事実が単にトランジスタの個数であるということだ。52mm x 45mmのダイには多くの他の部品が入っている。ムーアの観測は50年後の技術躍進の後でも試練に耐え続けているのだ。
エンジニアの目を通してムーアの法則を見る
ムーアの法則(各技術世代毎に2倍のトランジスタになると言われる)を引用する多くは、実際にトランジスタを設計する人達にとって、Gordon Mooreの観測が何を意味するのか完全に理解はしていない。技術開発の外で、トランジスタを縮小する挑戦は見られていないが、それでも巨大なのだ。そして、それはサイズにおける縮小だけではないのだ。ムーアの法則を提供するために、エンジニアは、内部構造、材料、および全体的なデバイス・アーキテクチャさえ変更することを含んだトランジスタ設計そのものにおける複雑性を増やすように推し進めている。これらの変更は、より小さい寸法において高性能で高電力効率であり続けることができるデバイスを作るのに必要なのだ。
10年ほど前までは、トランジスタのエンジニアリングは概念的にはシンプルであった: 前世代のトランジスタの基本的にあらゆる面におけるスケールダウンであり、その設計の特徴はすべて単純な2次元のダイアグラム(下図参照)の中に表現することができたのだ。プロセス開発の重要な部分であるトランジスタの数値シミュレーションは、デバイスを小さなシリコンブロックに分解して古典的な半導体物理を提供することで容易に達成することができた。計算はデスクサイドのワークステーションでも実行することが可能で、数分から数時間で方程式を解いたのだ。しかし、特徴サイズがスケールダウンするにつれて、我々はデバイスの性能を提供し続けるために、3次元トランジスタのような新規のアーキテクチャやナノスケールの新素材を使用しなければならなかった。これらはトランジスタの表現に3次元を追加し、より複雑な物理を必要とし、シミュレーションの複雑さを非常に大きくしたのだ。
10年前の2次元平面型トランジスタ(左)と現在の3次元アーキテクチャ(右)の複雑さを比較した下図を参照。
 |
 |
大きさ、アーキテクチャ、そして材料の課題
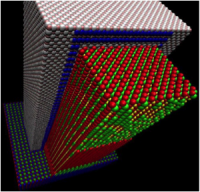
遠い未来を見る場合、次の数世代先のトランジスタを検証およびシミュレートしている。我々は顧客が望む性能と信頼性を持ったこの大きさの部品の開発を継続する必要のある技術を見ている。これらのより小さいサイズにおいては、我々がこれまで近似もしくは見落としていた物理的な影響がもはや無視できなくなってくるのだ。例えば、次の図は未来的なデバイスを示しており、赤と緑の球がそれぞれシリコンと金属の原子を表現しており、金属のゲートに囲まれたシリコンの「ワイヤ」でトランジスタが作られている。このサイズにおいては、ワイヤ内のシリコン以外の元素の単一原子(断面の隅に黄色の点で表示)がトランジスタの動作に影響を与えることができる。数値シミュレーション後に可視化されたように、この単一の浮遊原子は断面を通って移動する電子電流の均一性を歪ませ、所望の電気的動作を中断させる。数年前は、断面が大きいために、我々はこの効果を無視したであろう。未来のデバイスにとっては、その影響が深刻であるのでそれはできないのだ。
以下に示すナノワイヤ・トランジスタのシミュレーションは、どのように単一の浮遊原子が電子の挙動を歪ませているか示している。

このナノスケールのサイズにおいては、各原子の電子軌道を含むすべての原子をシミュレートすることが重要となる。古典的物理学は遠くに取り残され、我々は量子物理学の領域に入り、さらに複雑でシミュレートの計算が要求されるのだ。
この種の問題はワークステーションでは実行することができない。少なくとも、Intelが毎年もしくは2年毎に革新的な製品を出すことを可能にするタイムフレームにおいては。例えば、少なくとも曲線上の10ポイントにおける電流電圧相関(I-V特性)の計算はシミュレーションとトランジスタ解析の中心だ。以下の表は単一プロセッサコアを使って、様々なデバイスの単一のI-Vポイントを計算するのに必要なメモリ量と経過時間を示している。

これらのシミュレーションの大きさでは、電子の波動性が重要となり、シュレーディンガー方程式を解く必要がある。れらのシミュレーションはパデュー大学でGerhard Klimeck教授のグループが開発したコードであるNEMO5を使用して行われた。
典型的なエンジニアのデスクにおいても、今日の強力なワークステーションを使っても、この問題が計算能力より大きくなるのに時間は掛からない。ケース3の場合、典型的な10ポイント曲線は計算にほぼ15年かかるだろう。これらの大きさの経過時間は、企業が競合し、事業をし続けるためのこの種の開発スケジュールを維持するのにおいて、現実的ではないのだ。
ムーアの法則とHPC
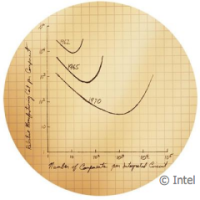
では、プロセス設計者として、我々はどのようにムーアの法則を推進する変化を維持するのだろうか?如何に我々はシミュレーションの中心にある縮小する技術、新しいアーキテクチャ、そして新素材と取り組むのか?我々はムーアの法則が性能向上の提供を助ける極限のコンピュータに目を向ける、非常に大規模なハイパフォーマンス・コンピューティング(HPC)クラスタだ。下図は如何に計算需要が歳月を掛けて技術の進歩を成長させたかを示し、その需要を形作ってきた主要な変曲点をマークしている。今日の問題は世界最速のスーパーコンピュータのTop500.orgリストを作る種類のマシンである非常に大規模なシステムで解決されている。
これらのHPCシステムが時代を設計するために何を意味するか示すために、ケース3に戻ってみる:20,000コアを使って、case 3の10個のI-V点を計算するは約1日で完了する。

ということで、ムーアの法則がHPCにおける益々大きな需要を推進し、より強力なHPCの創造を支援するムーアの法則を生かすデバイスを設計し続けることができるようにしており、そうすることで、ムーアの法則の状態をより小さく複雑なデバイスに持ち込むことができるのだ。もしそれがスーパーコンピュータのためでなければ、ムーアの法則の継続は不可能となるだろう。これは少なくとも近い将来において終わることがないシリコンで表現される共生サイクルなのだ。
トランジスタ設計のためのHPCを実現
電子設計とシミュレーションにおけるテクニカル・スーパーコンピューティングは、競争力を維持し、提供する製品におけるリーダーシップの地位を保持するために、Intelにとって絶対に必要なものである。2004年から今日において、Intelのチップ設計用の計算容量は上記の理由のために4,600パーセント(46倍)に増えている。Intelのチップ設計の時計算ニーズに適応するために、我々はIntel Xeonプロセッサで駆動する百万コアの約130,000台のサーバを持っている。
Intelのプロセス・シミュレーション・チーム(aka TCAD)が将来の世代のデバイス・シミュレーションに必必要とされる計算需要を持ってIntelのIT部門にアプローチしており、1,296ノードで2,592台のIntel XeonプロセッサE5-2680 v3、合計31,104コアと324TBのメモリをもったソリューションを設計した。SCD2P4(場所で名付けており、Santa Clara D2-P4 Data Center)と識別されるこのシステムは15台のエクストラ・トールの60Uのラック(標準は42U)に収容され、0.6MWの電力を消費する。
このスーパーコンピュータはいくつかの側面においてユニークである。1) ほとんどの世界クラスのスーパーコンピィータがカスタム部品を使っているのに比べて、コモディティ・ハードウェア/COTS(Common Off-the Shelf)の部品で設計されている; 2) 従来のラックサーバや特殊サーバではなく、ブレードサーバを活用しており、1.6倍の高密度を提供している(全体システムで26ラックに対して15ラック); 3) 現実世界のベンチマークを基に選択された部品、InfiniBandアーキテクチャのソリューション間で31%の違いがあった; 4) ユニークな複層チェックポイント・アーキテクチャを開発し、各サーバのIntel SSDを活用し、プロセスのチェックポイントとリストアの信頼性を向上させ、複雑な並列ストレージ・ソリューションの必要性を排除した。
 |
|
2015年6月に、SCD2P4システムは833.92 TFLOPSでTop500.orgのリストの81位にランクされた。11月のリストでも世界のトップ100内にはいっている。
クールなHPCマシン
このマシンは非常に大規模なシステムではあるが、トランジスタや回路設計専用の大規模クラスタなわけではない。Intelは少なくとも他に3つのHPCシステムを持っており、4,000コア以上搭載し、ここ数年間のTop500の中にランクされているのだ。設計の問題は、デバイスの複雑性と縮小するプロセス、そしてシリコンに追加される付加機能によって、ますます大きくなっている。すべてはより大規模なニーズに対応しているのだ。
SCD2P4のような大規模システムでは、データセンターが直面する問題のひとつは、電気代が高額であるために、電力の管理と電力効率の利用だ。
このクラスタはIntelのサンタクララにある非常にエネルギー効率に優れたフリーエア冷却のD2データセンターで動いており、電力利用効率(PUE)は1.06だ。業界における平均PUEは1.80である。これにより、SCD2P4は世界で運用されている最も電力効率に優れたスーパーコンピュータのひとつとなっている。我々はすべてを冷凍装置にするよりもフリーエア冷却を使うことができるので、このように高効率で大部分を動作させることができ、データセンターの温度を華氏60から91度の間に維持しているのだ。2014年には、年間8,760時間におよび運用時間において、このデータセンターは外気温が91度を超えたたたった39時間のみ冷凍装置による冷却を必要とした。このサンタクララ・データセンターは年間電気代で190万ドル、水を4千4百万ガロン分節約したと伝えられている。このように、Intelがトランジスタ設計でのみリードしているのでなく、これらの設計の取り組みをサポートするデータセンターが最適な利用率と電力効率で構築され、管理されているのだ。
プロセス設計のためのエキサイティングな時間
現代のHPCシステムの機能によって、デバイス・エンジニアリングは10年前よりもさらにもっとエキサイティングになっている。我々は信じられないほど面白いシミュレーション、我々が夢見たことがない詳細レベルの仮想実験を行っている; 我々は今や新しいデバイス・アーキテクチャや新材料を探索し、電子の挙動や原子レベルでのプロセス物理学を可視化している。
業界の一部の反対者がムーアの法則の終わりを告げる鐘を鳴らしてる間に(彼らが太古からそうしているように)、これを継続するのがIntelの仕事である。各世代が自分達の課題が一番難しいと考えるのはエンジニアリングにおける不文律である。新しい技術課題が常に出現を続けるが、最初のVLSIチップが作られてから各世代があるように、ムーアの法則の見通しは20年前のそれと同じままである。; 次の数世代への道筋は見えており、その先は、我々が先に進むまでかすんでいるのだ。
エクサスケールに向けたHPC業界の進展はムーアの法則に依存している。スケーラブルで、バランスの取れた、効率的なHPCシステムである、この新しいIntelのスケーラブル・システム・フレームワーク(Intel SSF)は、念頭において設計されている。プラス、Intel SSFは、IntelのOmni-Pathアーキテクチャ・ファブリックや、プロセス設計者がムーアの法則を進歩させ続けるようにする課題に対処できるようにするスーパーコンピュータを強化するような3D XPointのようなイノベーションのメリットを利用している。
イノベーションは定義によって障壁に悩まされている。Intelの仕事は探索や発見でこれらの障壁を克服することである。トランジスタ設計の場合には、これは新素材、デバイス・アーキテクチャ、製造プロセスなどの創造を意味している。消費者にこれらに進歩を提供することは、チップの製造以前に多くのシミュレーションを行うことを意味している(下記を参照) 。スーパーコンピュータ無しでは、ムーアの法則を何が継続していくのか理解することとはできないし、そしてこの理解無くしては、より強力なスーパーコンピュータを創造することはできないのだ。この共生は、ムーアの法則とHPCにおける関係の中心にある。
 |
|
ここに示されるように、数値シミュレーションとHPCの活用で、プロセス設計者は新しい材料とプロセス技術、および実際に実験を行う前にデバイスの挙動における影響について可視化することができるのだ。上図は、製造プロセスにおいて発生する化学反応のシミュレーションを示している。個々の粒子は原子である。
 |
|
| Mark Stettler |
著者について:
 |
|
| Shesha Krishnapura |
Intelのプロセス技術とモデリングのディレクターで、技術と製造グループの副社長であるMark Stettlerと、Intelの最高技術責任者で上級主席エンジニアであるShesha Krishnapuraによる。SCD2に関する詳細については、Intel Data Center Design Reaches New Heights of Efficiency (http://datacenterfrontier.com/intel-data-center-new-heights-efficiency/)および、ライバルであるGoogle、Facebookの取り組み対するIntelのCIO
が構築する効率化データセンター(http://blogs.wsj.com/cio/2015/11/09/intel-cio-building-efficient-data-center-to-rival-google-facebook-efforts/).を見て欲しい。
特別イベント

寄稿者
![]() 西克也
西克也
西克也はフェアチャイルド社、クレイ・リサーチ社、ベストシステムズ社など、30年以上に渡ってHPCに関する仕事に従事している。Hpcwire Japanの編集長として記事の作成と翻訳を行っている。
![]() 島田佳代子
島田佳代子
1999年~2007年まで英国在住。2001年よりスポーツ、旅、ビジネス、映画など幅広いジャンルで執筆活動を開始し、Hpcwire Japanでは主に日本のHPC業界が世界に誇る研究者、開発者の方々のインタビューを担当。
![]() 小柳義夫
小柳義夫
小柳義夫氏は40年以上に亘ってHPCに携わってきた研究者であり、日本のHPC業界における生き字引として有名。現在 高度情報科学技術研究機構に所属し、産業界のHPC推進にあたっている。
![]() 小西史一
小西史一
小西史一は、理化学研究所、東京工業大学においてHPCおよびバイオインフォマティクスに関する研究と教育に携わってきた研究者。2012年からフォトグラファーとしての活動を開始し、現在はIT技術・セキュリティのコンサルティング業務に携わっている。