
HPCの歩み50年記事一覧

スパコンリスト日本

記事寄稿について

NvidiaのAmpere A100 GPU:HPCで2.5倍、AIで20倍
Tiffany Trader

Nvidiaの最初のAmpereベースのグラフィックスカードであるA100 GPUは、826mm2のシリコンに驚異的である540億個のトランジスタを搭載し、世界最大の7ナノメートルチップである。 Ampereアーキテクチャは、Nvidiaの責任者Jensen Huangが録音した「キッチン基調講演」の中で発表されたもので、先代のVoltaを踏襲しており、トランジスタのダイヤルを上げるメガGPU、AIへの特化、そして全体的なパフォーマンスを提供する。 12nm Voltaと7nm Ampereの両方がTSMCによって製造されている。
 |
|
| Jensen Huangは、「キッチン基調講演」の最中に新しいAmpere A100 GPUを掲げた。 COVID-19のため、オンサイトでのGPUテクノロジカンファレンス(GTC)は開催されなかった。 | |
Ampereを活用するHPCワークロードは、HPC処理用の新しいIEEE準拠のTensorコア命令により、兄のVoltaに比べてピークでの倍精度浮動小数点性能が250%向上している。 Nvidiaが実施したベンチマークでは、Voltaの1.5倍から2.1倍の範囲でHPCワークロードのスピードアップを実現した(ページの下の方にある「HPCの加速」チャートを参照)。ピーク単精度演算性能は、TensorFloat-32(TF32)Tensorコアを追加することで、理論的に10~20倍向上する。
その他の新機能は次のとおり。
- 単一のA100 GPUを最大7つの個別のGPUに分割できるようにするマルチインスタンスGPU(別名MIG)
- GPU間の高速接続を2倍にする第3世代Nvidia NVLinkファブリック
- 構造的スパース性、Tensorコアでスパース行列演算のサポートが導入され、2倍に高速化
以下は、Volta V100とAmpere A100 GPUの比較表である。
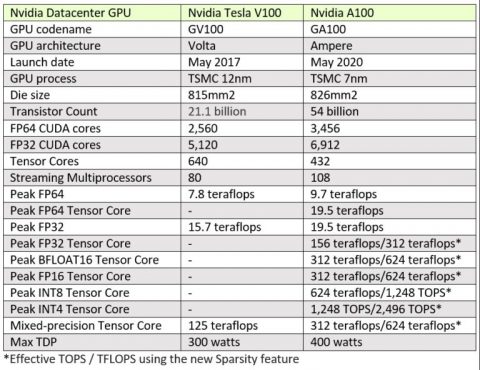
Ampere(フランスの物理学者で数学者にちなんで名付けられた)は、HPC、AI、およびグラフィックスをサポートするVoltaアーキテクチャを導入されたNvidiaの単一ユニバーサルGPU戦略を倍増している。 「[Ampere A100を使用する場合]、Volta GPUサーバ、T4 GPUサーバ、およびCPUサーバで実行していたすべてを1つの統合されたAmpereサーバで実行できるようになったのです。」とHuangはメディア・ブリーフィングで述べている。「これは間違いなく、データセンター全体の高速化ワークロードを単一のプラットフォームに統合した初めてのことです。」とHuangは付け加えた。 「ご存知のように、ビデオ分析から画像処理、音声、トレーニング、データ処理への推論まで、すべてが1つの統合サーバ上にあります。」
ここでHuangは、今日本日発売された新しいDGXマシンについて言及している。 DGX A100は8つのA100 GPUを搭載しており、320 GBのメモリと12.4 TB /秒の帯域幅を提供する。第3世代のNVLinkファブリックを備えた6つのNVSwitchがGPUを接続し、毎秒4.8TBの双方向帯域幅を提供する。各DGX 100システムは、9つのMellanox ConnectX-6 200Gb / sネットワークインターフェイスと15TB Gen4 NVMeストレージを提供している。
 |
| ほぼ5ペタフロップスのFP16ピークパフォーマンス(156 FP64 Tensorコアパフォーマンス)を備えたNvidia DGX A100 |
第3世代の「DGX」により、Nvidiaはもう1つの注目すべき変更を行った。デュアルBroadwell Intel Xeonの代わりに、DGX A100は2つの64コアAMD Epyc Rome CPUを搭載している。この動きは、Intelの新興GPU戦略に対するNvidiaの反発を示唆している可能性があり、AMDの価格パフォーマンスのストーリーに動機付けられている可能性がある。
Arm CPUオプションも登場し、GPUアクセラレーションされたArmに関する強力な開発活動が続いているため、第4世代のDGXで別のCPUの大変動が見られても驚くことではないだろう。 Nvidiaは、MarvellまたはAmpereからArmサーバーチップを選択するか(共同ブランド化の機会を想像してみる)、もしくは全力で内製で開発されたArm CPUを増え続けるスタックに追加することを決定できるかもしれない。 CUDA 11は、完全なArm64サポートでデビューしている。
Nvidiaのスタックと言えば、4年前のDGX-1の発表からMellanoxの買収だ。Nvidiaは、OEMパートナーとの潜在的な競合を認識して、システムメーカーの名称から遠ざかった。その抵抗は減少したようだ。
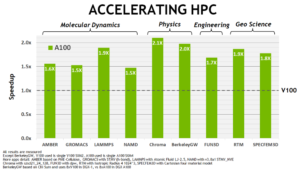 |
|
| NVIDIA Tesla V100と比較したA100 GPU HPCアプリケーションの高速化(出典:Nvidia) | |
「垂直方向に完全に統合されたシステムを開発して、コンピュータの新しいフォームファクターを開拓しました。」と、同じメディアブリーフィングでNvdiaのデータセンターおよびクラウドプラットフォームの製品管理責任者であるParesh Kharyaは述べている。 「私たちはシステム全体を開き、それらを基本的なビルディングブロックに変えます。したがって、私たちのエコシステムは、業界全体において一部または全体を購入できるのです。」
「Nvidiaは実際にはデータセンター規模のコンピューティング企業です。 30年前はPCの会社でしたが、その後ワークステーションの会社になり、次にサーバの会社になり、最終的にはデータセンターに参入しました。しかし、コンピューティングの未来:データセンターはコンピューティングユニットです。コンピューティングの未来は本当にデータセンターの規模となります。アプリケーションはデータセンター全体で同時に実行されるのです。」とHuangは後に付け加えた。
Nvidiaはまた、140台のDGX A100システム(1,120 GPU)、170台のMellanox Quantum 200G IBスイッチ、280 TB / sのネットワークファブリック(15 km以上の光ケーブル)、および4ペタバイトのオールフラッシュ・ネットワーク・ストレージで構成されたDGX A100 Superpodを発表した。Nvidiaによると、システム全体は、約22ペタフロップスのピーク倍精度性能(700ペタフロップスの「AIコンピューティング」)を実現しており、3週間足らずで構築されたとNvidiaは述べている。
Nvidiaは、Saturn-Vと呼ばれる内部スーパーコンピュータに4台のSuperpodを追加し、「AIスーパーコンピューティング」の総性能を約5エクサフロップスに高めた。これにより、Saturn-Vは世界で最も高速なAIスーパーコンピュータになる。これらすべてのGPUの合計倍精度性能は約93ピーク・ペタフロップスになるが、Huangは、Saturn-Vが実際には1つのシステムではないことを明らかにした。 1つの管理インターフェイスの下の4つの異なる場所にある。 Nvidiaは、コンピュータグラフィックス、ロボット工学、自動運転車、ヘルスケア、および新しい推奨システムであるMerlinに適用されるソフトウェア開発にこのシステムを使用する。
 |
|
| DGX A100クラスタ。写真提供:アルゴンヌ国立研究所 | |
しかし、Nvidiaには、Saturn-Vを構築するもう1つの理由がある。 「私たちがデータセンター規模の企業で、チップ、システム、ソフトウェアをデータセンター規模で開発している場合、私たちが自分たちでそれを構築する必要があるのは当然のことです。」とHuangは述べている。
DGX A100の価格は$ 199,000で、現在出荷中だ。最初のオーダーは、クラスタを使用してCOVID-19をよりよく理解して戦う米国エネルギー省のアルゴンヌ国立研究所に向けられた。 HPC研究コミュニティの他の早期採用者には、インディアナ大学、ユーリッヒスーパーコンピューティングセンター、カールスルーエ工科大学、マックスプランクコンピューティングおよびデータファシリティ、DOEのバークレー国立研究所のNERSCなどがある。
強力なパートナーサポートもある。 A100を統合する予定のクラウドサービスプロバイダーとシステムビルダーのリストには、Alibaba Cloud、Amazon Web Services(AWS)、Atos、Baidu Cloud、Cisco、Dell Technologies、Fujitsu、GIGABYTE、Google Cloud、H3C、Hewlett Packard Enterprise、Inspur、 Lenovo、Microsoft Azure、Oracle、Quanta / QCT、Supermicro、Tencent Cloudがある。
DGX A100のバックボーンであるHGX A100リファレンスデザインは、4 GPU構成と8 GPU構成で提供される。 4 GPU HGX A100は、NVLinkを使用してGPU間の完全な相互接続を提供し、8 GPUバージョンは、NVSwitchを介してGPUからGPUへの完全な帯域幅を提供する。新しいマルチインスタンスGPU(MIG)アーキテクチャにより、アンペールサーバは、Huangがそれらを呼び出すと聞いたように、推論用に56個の小さなGPUとして、またはトレーニングまたはHPCワークロード用に連携して動作する8つのGPUとして構成できる。
特別イベント

寄稿者
![]() 西克也
西克也
西克也はフェアチャイルド社、クレイ・リサーチ社、ベストシステムズ社など、30年以上に渡ってHPCに関する仕事に従事している。Hpcwire Japanの編集長として記事の作成と翻訳を行っている。
![]() 島田佳代子
島田佳代子
1999年~2007年まで英国在住。2001年よりスポーツ、旅、ビジネス、映画など幅広いジャンルで執筆活動を開始し、Hpcwire Japanでは主に日本のHPC業界が世界に誇る研究者、開発者の方々のインタビューを担当。
![]() 小柳義夫
小柳義夫
小柳義夫氏は40年以上に亘ってHPCに携わってきた研究者であり、日本のHPC業界における生き字引として有名。現在 高度情報科学技術研究機構に所属し、産業界のHPC推進にあたっている。
![]() 小西史一
小西史一
小西史一は、理化学研究所、東京工業大学においてHPCおよびバイオインフォマティクスに関する研究と教育に携わってきた研究者。2012年からフォトグラファーとしての活動を開始し、現在はIT技術・セキュリティのコンサルティング業務に携わっている。