
HPCの歩み50年記事一覧

スパコンリスト日本

記事寄稿について

NVIDIA HPC WEEK シミュレーションと深層学習 – Preferred Networks 岡野原大輔 氏
 |
2021年10月18日 エヌビディア合同会社が主催するNVIDIA秋のHPC Weeks 2週目では、HPC + Machine Learning をテーマとして、HPCと機械学習の融合や、その最新の手法、そして、大規模分散学習などの分野で、最前線で活躍されている著名な講演者による5つのセッションが行われた。その中で、基調講演としてAIとHPCの両分野で広く知られているPreferred Networks社(以下PFN)の代表取締役COO 岡野原 大輔氏による「シミュレーションと深層学習」のタイトルの講演で、深層学習がどの様にAIに融合していくのかについて分かりやすく解説していただいたので、ここで紹介したい。
「今後シミュレーションが重要になる」
岡野原氏は、まず講演の冒頭で、現在の深層学習の成功事例は、大きなデータと、大きく複雑なモデル、そして、大量の高性能な計算リソースを使って学習させると成功するという事が分かってきていると切り出した。したがって、このような深層学習による学習が成功している分野の特徴として、データが比較的入手可能な分野であるとも指摘する。
例えば、自然言語処理の分野でよく知られているGPT3などは、Web上で自然言語データをクロールする事で入手できたことで、大きな深層学習用のデータを構築する事が出来たとされ、データがまだ足りない分野では、深層学習の導入には、まだまだ時間がかかるようだ。このような学習用に利用できるデータ構築の現状は、最近のDXの波もあり、AI関連を扱う企業や、サイエンス的な見地からも、データ自身を作れるようなシミュレーションを作っていく事が、今後ますます重要になっていくとの見解を示した。
また、シミュレーション自体に対しても、深層学習と融合させる事で、劇的な実行速度の高速化や、多様な応用に広げる貢献が、実現可能になってきているとし、具体的な事例も出て来ているなど、最新のシミュレーションと深層学習の双方向の関わりについて説明があった。
現在のAIなどの深層学習を利用した手法は、大きな成功を収めているが、世の中の全ての問題に対して、うまく適用できるわけではない。これまでの成功事例から、深層学習が成功する条件として、以下の2つの必要条件を満たしている事が必要と話す。
現在の深層学習(機械学習)が成功する条件:
1. 大量の教師データが利用できる。
数万から数百万サンプルある事が望ましい
2. 学習時のデータ分布は利用時のデータ分布と同じである。
現在の深層学習は内挿問題を解けるが外挿問題は解けない
得られたモデルが利用時に実際使えるかの検証も難しい
まず、1つ目の条件として、大量の教師データが利用できる点はとても重要で、1つの問題あたり数百万サンプル程度あると良い結果が出るという。また逆に数万サンプルぐらいしかないと、学習に対して、少しこころもとないと感じる。
2つ目にあげる条件は、現状も、まだ難しい項目である事は知られていて、学習時のデータ分布と、利用時のデータ分布が同じである事が必要という意味になる。これは、いまのほとんどの統計的機械学習では、独立同分布(independent and identically distributed; IID)の性質を持つデータを対象に扱っている事が原因となっている。
したがって、いま使われている深層学習では、外挿問題を解くことは基本的に難しい問題設定となる。例えば、訓練用の学習データが大量にあり、且つ、バラエティーがある状態の汎化性能は、似たデータがサンプルされた場合には高い性能値を達成するが、訓練データから、外れるような、分布の外側にあるようなデータのケースは上手くいかない。
人間は、このような分布から外れた場合でも解く能力を持つ為、機械学習の実用化の観点では、機械学習が、うまくいかないと感じる一番の理由となってしまう。この事の簡単な例としては、晴れの日の写真だけで、画像認識用の学習データとして利用すると、雨の日では使えないパラメータが学習されてしまうなど、数多くの上手くいかない事例があげられる。これは対象問題にとって何が不変なのか、また、何が特殊なのかを、機械やシステムが識別できないからで、人間ではあり得ないような過学習が行われてしまうことが主な原因となっているそうだ。
もしシミュレーションを使って、これらの深層学習が成功する条件を満たす、つまり機械学習にとって望ましい状況をつくる事ができれば、学習の適応範囲を今よりも劇的に増やす事ができると考えているとの事であった。
「シミュレーションと深層学習は相互に助ける」
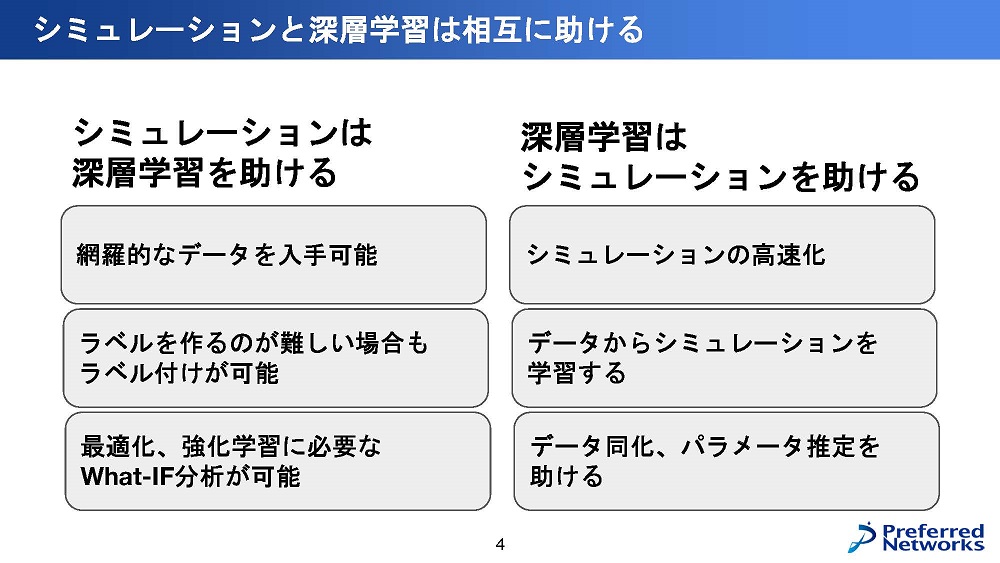 |
「シミュレーションは、深層学習を助ける」
シミュレーションと深層学習は、相互に助ける事ができる関係にある。その理由の1つ目は、シミュレーションにより生成される網羅的なデータを使って、通常では準備する事ができない分布のデータを対象にした深層学習ができる点にある。
例えば、自動運転の危険な状況の学習用に、高速道路の中で人が走っているような動画を使いたい場合や、まだ世の中に存在していない材料を使った場合の反応などでは、既存のデータセットで学習している場合には、とうてい取得の難しいデータとなってくる。
そして、希少な病気の病変が発生した場合には、個人差や再現性が難しいなどの理由で、実際には取得できない。このように現実の世界では、稀にしか発生しないが、重要で価値のあるデータの収集に対して、シミュレーションを使う事は、網羅的で且つ再現性にある形でデータセットとして簡便に取得する事が出来る好例だといえる。
そして2つ目は、深層学習の教師有り学習において不可欠なラベル付けを、シミュレーションの実行中に自動的に付けてくれる事ができる点である。これまでシミュレーションを使って学習する事自体は、機械学習の黎明期から議論されてきた事だが、シミュレーションとリアルとの間には、いまだに大きなギャップが有り、簡単にはリアルの代わりとして使う事が難しいとされてきた。
もちろん今でも、多くの場面で難しいとされているが、最近では、一部の分野で進化してきており、シミュレーションの結果を学習データとして使って、現実の世界でも正しく動く事例も登場してきている。例えば室内のシミュレーションであれば、ML-HyperSim[M.Robers ICCV 2021]など、優れた物が出てきている。このようなデータセットでは、セグメンテーション等の密なラベルが付いてきており、これらのデータを使って、深層学習が可能なレベルになっている。
3つ目としては、これまでの学習といえば、受動的に与えられたデータを元に獲得する方法であったが、新たに能動的に環境や状況に変化させた際に起きるデータ分布の変化に対応できるWhat-IF分析など想定したシミュレーション環境を整える動きもある。そのような環境下では、最適化や強化学習が可能となる。例えば、エージェントが行動を変えた場合の環境の変化や、そのタイミングでの入力情報や結果の変化なども、シミュレーターであれば調べる事が可能となる。
「深層学習はシミュレーションを助ける」
次に、逆の深層学習がシミュレーションを助けるという関係について、まず1つ目は、シミュレーションの高速化についてあげられる。現在では、かなり成功している事例となっているが、シミュレーターが、多様な結果を出力できる物であれば、入力からシミュレーションの結果を大量に生成し、その結果を学習データとして、内挿問題として学習し、本来のシミュレーションの結果を高速に近似する例となる。
例えば、流体シミュレーションの場合では、低い解像度で小さいサイズで実行したシミュレーション結果を学習目標として与え、大きく高い解像度でのシミュレーション結果を得る事で、実に100倍近くの高速化を達成する事が出来る。
このような学習をさせる場合に重要な事は、ニューラルネットワークモデルには、何らかの物理的な普遍性や対称性、制約を入れておく事が重要で、この流体問題の場合でも、既存のシミュレーションの方程式の中の補間と補正項について学習するなど、モデルの中の一部分をニューラルネットワークに置き換える手法をとる事で汎化性能を上げている。
そして、2つ目は、データからシミュレーション自体を学習する例で、CG等を使って学習する場合に、そのシミュレーションで使われる多様な車や、標識などのアセットを、実際に走行して取得した映像から、深層学習により抽出し獲得していくという例がある。例えば、GeoSim[Y. Chen, CVPR 2021]と呼ばれる自動運転用のシミュレーターの例では、元々多数のアセットを使っていたにも関わらず、多様性が十分ではなく性能がでなかったことから、実際に走行した際の車載カメラの映像データから、車や標識など、環境の様々なアセットを学習して、さらに取り込む事で、Sim2real gapを大幅に減らす事ができたとされている。
さらに最新の話として、ADOP[Rückert,arXiv,2021]では、100枚程度の写真から、3次元復元して任意の視点からのビューを生成する例がある。特にこの例では、写実的な表現をリアルタイムに生成する事ができる事から、ARの分野での応用が期待されているし、大量に空間データを作る場面において役に立つ例といえる。
そして、最後の3つ目は、シミュレーションを特定のデータやパラメータに合わせる必要があるなどの、データ同化やパラメータ推定を助けるのに利用できることだ。
最近多くなってきた例としては、シミュレーターと対象データがある場合に、シミュレーターのパラメータに対して、対象データを生成するような値を推定する問題だ。このシミュレーターは多くは巨大なプログラムとなっており、多数の各パラメータを適切に合わせる事が難しいとされる問題となっている事が多い。最近は、このシミュレーターの全て、もしくは、一部に、微分可能な代理関数を使う事で、観測データからシミュレーションを支配している潜在変数や、パラメータの勾配を計算できるようにして、観測に対する事後確率分布を効率良く推定する事ができるようになってきている。これらの3つが深層学習におけるシミュレーションを助ける例となる。
PFNでの事例紹介
PFNでは、深層学習とシミュレーションを使った事例として以下のようなものがある。
- 画像認識:CGからの学習。現実世界の様々なオブジェクトを3Dスキャンし、これまで日用品を対象に数万オブジェクトの精細な微分可能レンダリングを使って、写実的に利用できるアセットデータを作成してきた。おそらく世の中で最大規模のデータセットとなっている。
- 創薬:医薬品の生成モデル・シミュレーション。京都薬科大との共同研究でCOVID-19の治療薬候補となる3CLプロテアーゼ(Mpro)阻害剤を探索。
- 音声認識:ロボット自身の雑音を抑圧し、ユーザーの音声を強調する技術。実世界の様々な部屋の形状、ユーザー、ロボットの位置を網羅し、音響シミュレーターを活用して実環境を模擬した学習データセットを作成。
- プラント最適化:シミュレーションデータと実運転データを組み合わせた自動最適化運転。
- 原子/分子シミュレーション:原子レベルシミュレーター。データと手法を工夫した独自のNNPを開発し、カバーする対象の大きさ、速度、精度で従来手法を大きく凌駕する原子レベルシミュレーター「Matlantis」。


Matlantis
触媒材料などの材料探索は、従来は実験結果を使って、新しい材料の性質を予想するアプローチが取られていたが、新しい触媒や、今まで試していない原子の組み合わせで調べてみたい場合には、シミュレーションをする必要がある。このシミュレーションにおいては、原子や分子の挙動において電子が重要な役割を果たし、電子の運動を支配する方程式は、古典力学ではなく量子力学で記述する。量子的粒子はシュレディンガー方程式に従うが、この方程式を解くためには、莫大な計算量を必要とする。DFTと呼ばれる手法により高速に計算する事が可能となったが、計算量は原子数の3乗程度、最新の研究でも2乗程度必要で、数千の原子を扱うのに数ヶ月必要だった。
このDFTの結果を近似するニューラルネットワークポテンシャル(NNP)は、同様に古くから研究されてきたが、大量の学習データをつくり、新しい独自のNNPを開発し、新しいアーキテクチャと、新しい学習手法で開発したシミュレーターを作り、「Matlantis」として製品化して提供している。
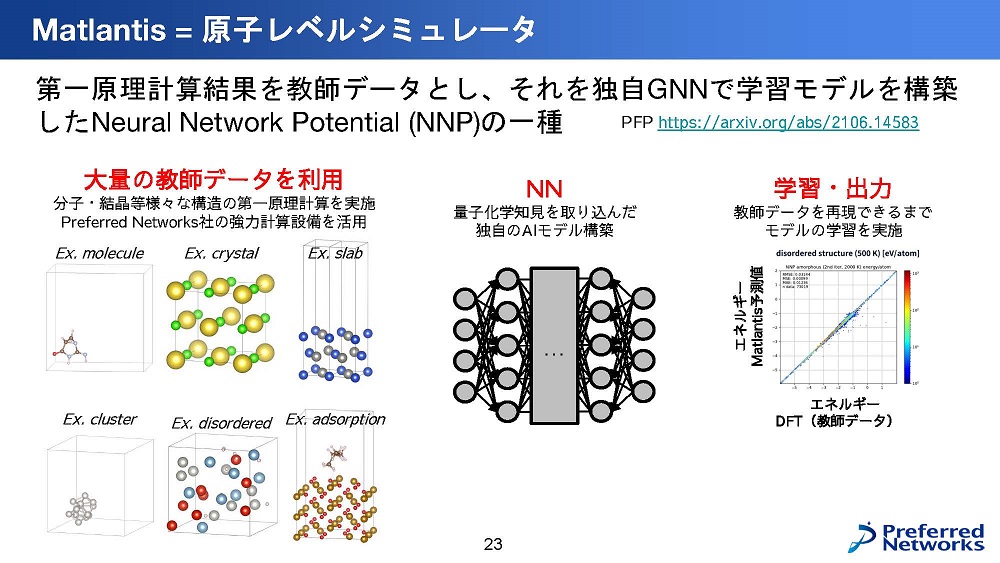 |
Matlantisという製品は、従来の同程度の精度で10万〜1000万倍の計算速度を達成している。数ヶ月かかっていたシミュレーションが数秒で得られる。さらに対応する元素も55元素の組み合わせをサポートしており、幅広い現象をサポートしている。よって、1つのシミュレーションで様々な現象・原子を含んだ計算をする事ができる。Matlantisの学習用データセットを作成するために、分子・結晶等の様々な網羅的な構造に対して、計算コストの高いDFT計算を実施した。その計算規模は、1台のGPUであれば、約273年も掛かる計算時間を費やして、PFNのスーパーコンピューターで作成している。この計算量はGPT3の概ね半分程度の計算量に相当する。
この大量の教師データを、量子化学の知見を組み込んだ、独自のGNNモデルにより学習することで、DFTと同じ計算結果を出す事ができるまで、モデルを学習している。このMatlantisを使った事例として、再エネ合成燃料触媒探索では、20年かかる計算実験を、1週間で完了させる事ができた。また他の事例では、水素キャリア触媒や潤滑油添加剤でも、従来1年かかる計算を半日程度で解析を完了する高速化を実現した。
まとめ
シミュレーターと深層学習はお互い助け合っていて、これからも、お互いに助け合って進化していく。今後は、より多くの現象がAIと組み合わさる事で、シミュレーションは、より操作可能で、高速に、高忠実に進化していき、その結果をAIが取り込む事で、AI自体もさらに高度に進化していくと考えられている。
用語解説:
深層学習: 多層構造のニューラルネットワークを用いた機械学習の手法
GPT3: 約45TBの大規模なテキストデータのコーパスを約1750億個のパラメータを使用して学習する最新の言語モデル
クロール: ソフトウェアが自動的にインターネットを巡回し、情報を取得する方法
DX:DX(デジタルトランスフォーメーション/Digital Transformation) 「デジタル技術による(生活やビジネスの)変革」
独立同分布: それぞれの確率変数が他の確率変数と同じ確率分布を持ち、かつ、それぞれ互いに独立している場合
外挿:訓練データ(入力データおよび教師ラベル)の数値の範囲外で出力を求める
内挿:訓練データ(入力データおよび教師ラベル)の数値の範囲内で出力を求める
汎化性能: 未知のテストデータに対する識別能力
Sim2Real gap: シミュレーションでトレーニングされたモデルが実世界ではうまく機能しない場合の事
DFT:Density Functional Theory密度汎関数理論
GNN:Graph Neural Network
特別イベント

寄稿者
![]() 西克也
西克也
西克也はフェアチャイルド社、クレイ・リサーチ社、ベストシステムズ社など、30年以上に渡ってHPCに関する仕事に従事している。Hpcwire Japanの編集長として記事の作成と翻訳を行っている。
![]() 島田佳代子
島田佳代子
1999年~2007年まで英国在住。2001年よりスポーツ、旅、ビジネス、映画など幅広いジャンルで執筆活動を開始し、Hpcwire Japanでは主に日本のHPC業界が世界に誇る研究者、開発者の方々のインタビューを担当。
![]() 小柳義夫
小柳義夫
小柳義夫氏は40年以上に亘ってHPCに携わってきた研究者であり、日本のHPC業界における生き字引として有名。現在 高度情報科学技術研究機構に所属し、産業界のHPC推進にあたっている。
![]() 小西史一
小西史一
小西史一は、理化学研究所、東京工業大学においてHPCおよびバイオインフォマティクスに関する研究と教育に携わってきた研究者。2012年からフォトグラファーとしての活動を開始し、現在はIT技術・セキュリティのコンサルティング業務に携わっている。