
HPCの歩み50年記事一覧

スパコンリスト日本

記事寄稿について

このクラブでは、「EXAを獲得」しなければならない
Doug Eadline オリジナル記事「In This Club, You Must ‘Earn the Exa’」

最近、「AI Exascale」というフレーズを含むプレスリリースや見出しがいくつか見られる。エクサスケールやゼタスケールという言葉が誇張されている場合を除き、これらの記事ではエクサスケールという用語を使用する正当性を裏付けるだけの十分な情報が提供されていない。HPCコミュニティの人々はエクサスケールという言葉の意味を理解しており、これは当該のコンピュータがエクサフロップスの持続性能を達成していることを意味する。初心者向けに説明すると、接頭語の「exa」は10^18の略語であり、FLOPSは1秒あたりの浮動小数点演算(加算や乗算など)を意味する。1エクサフロップスは1秒あたり1000兆回の浮動小数点演算である。
より具体的には、Wikipediaによると、「エクサスケール・コンピューティングとは、少なくとも1秒間に10^18回のIEEE 754倍精度(64ビット)演算(乗算および/または加算)を実行できるコンピューティング・システム(エクサFLOPS)」を指す。
 |
|
システムのFLOPSレートを測定するには、オープンソースの高性能LINPACKベンチマークプログラムを実行する必要がある。FLOPSレートを測定するプログラムは他にもあるが、HPLinpackは1993年まで遡る歴史的な記録を持っている。実際、倍精度FLOPSを使用したこのベンチマークの性能を報告するリスト「TOP500」が年2回更新されている。なぜ倍精度なのか?それは、これらの巨大なシステムが解決する数値問題の多くに最適な答えを与えるからだ。
現在、TOP500リストによると、エクサスケール・クラブに属するシステムは世界で2つある。
1. DOE/SC/オークリッジ国立研究所のFrontierは、理論上のピーク性能が1.715エクサフロップスで、1.206エクサフロップスを達成している
2. DOE/SC/アルゴンヌ国立研究所のAuroraは、理論上のピーク性能が1.980エクサフロップスで、1.012エクサフロップスを達成している
これらの数値について、いくつか留意すべき点がある。まず、各マシンの理論上のピーク性能は、システムの各コンポーネントの最大性能の合計である。つまり、各コンポーネントが、基礎となるアプリケーションを考慮することなくフル稼働した場合の性能である(TOP500では、Rpeakとして報告されている)。実際には、技術的な観点から言えば、実際のアプリケーションでは「他の処理も実行されている」ため、理論上の速度は決して達成されない。
次に、HPLinpackベンチマークを使用して、達成された最高の性能(TOP500リストで報告されたRmax)が測定される。他のベンチマークやアプリケーションでは、マシンからより多くのFLOPSを引き出せる可能性もあるが、HPLinpackが使用されるのは、長い歴史的記録があり、標準的な尺度として使用できるからである。
最後に、他の大型マシンでは、ベンチマークを実行しないか、あるいはTOP500に結果を提出しない場合もある。他のエクサスケールクラスのマシンも現在開発中であり、このクラブは拡大していくことになるだろう。
さらに、HPCコミュニティでは、高性能コンピューティング(HPC)と人工知能(AI)のワークロードが収束しつつあることも認識されている。従来の「TOP500 HPC」マシンは、物理学、化学、生物学における現象のモデリングのためのコンピューティングに重点を置いていたが、これらの計算を推進する数学モデルのほとんどは64ビット精度を必要とする。その一方で、AIで使用される機械学習の手法では、32ビットやそれ以下の浮動小数点精度フォーマットでも望ましい結果が得られる。新しい混合モード(HPC&AI)システムを評価する方法として、混合フォーマットのベンチマークであるHPL-MxPが使用されている。
これらのシステムの運用と管理は容易なことではない。これらのシステムは高性能計算の極みである。利用可能な最高の技術を用いて設計、構築、テストされている。
芽を摘む
エクサスケールという言葉の意味に関する現在の理解とコンセンサスを踏まえると、最近の発表で「エクサスケール」や、さらには「ゼタスケール」(10^21 FLOPS)のシステムがエヌビディアのBlackwell GPUをベースに謳われていることに驚きを覚えるのも無理はない。確かに、Blackwell GPUはHPCとAIアプリケーションの両方においてSIMD演算の強力なパワーを発揮するが、測定されていない恣意的なパフォーマンス指標を付け加えるのは、控え目に言っても誠実とは言えない。
未構築のシステムから、どうしてこのような「コーヒーを吹き出す」ような数値が導き出されるのか、疑問に思うはずだ。世界最速のマシンを打ち負かすプロセスは、紙の上では、実際には非常に単純である。しかし、その前に少し寄り道をして浮動小数点数について説明する必要がある。
浮動小数点フォーマットについて少し
コンピュータにおける数値の表現は、厄介な作業である。コンピュータは有限であるため、すべての数値を表現することはできない。科学技術計算では、アプリケーションは浮動小数点(略してFP)を使用してプログラムされる。
科学技術計算では、2つの基本的なFP数値が使用される。これらの数値は、数値の表現に使用されるビット(1と0)の数で測定される。
- 32ビット単精度型で、-3.40282347E+38から-1.17549435E-38、または1.17549435E-38から3.40282347E+38の範囲で、約7桁の小数点以下の精度を持つ
- 64ビット倍精度型で、範囲は約1.797693134862315E+308から-2.225073858507201E-308まで、 または2.225073858507201E-308から1.797693134862315E+308までの範囲、および約15桁の小数点以下の精度を持つ
これらの範囲に対して大きすぎる、または小さすぎる値はエラーの原因となる。
32ビットおよび64ビットの倍精度浮動小数点数表現は、以下の図に示されている。
| FP32 数値0.15625の浮動小数点数フォーマット(出典:Wikipedia) |
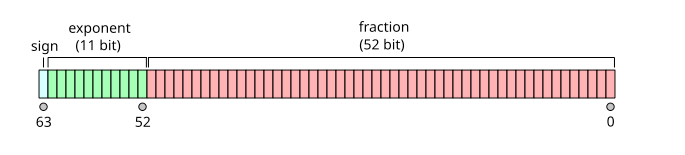 |
| FP64 浮動小数点数フォーマット(出典:Wikipedia) |
ほとんどのHPC計算では、FP64(またはFP32と64の組み合わせ)が使用される。これは、より精度の高い答えの方が有用だからである。精度が向上すれば結果も良くなるが、倍精度演算では2つの64ビット数を掛け合わせることで3番目の64ビット数を得る必要があるため、演算コストが増加し、より長い時間を要する。 複雑な演算を行うシングルおよびダブル精度を使用するCPU向けに、テスト済みの最適化ライブラリが存在する。 GPUベンダーもシングルおよびダブル精度の演算ライブラリを提供している。 HPCシステムでは、最高のパフォーマンスは常に倍精度で測定される。
生成AI(GenAI)の登場。生成AIとLLMのポイントは、大量のデータを使用してモデルを作成(トレーニング)し、「重み」を決定することである。モデルがトレーニングされると、クエリ(推論)が実行された際に、これらの重みがモデルの制御に使用される。これらの重みは、高い精度でトレーニング(計算)され、大量のメモリと計算能力を必要とする。LLMで使用される手法の1つに量子化と呼ばれるものがあり、重みの精度が低下する。多くの場合、低精度の重みでもモデルの挙動は変わらないため、モデルを実行するのに必要な計算量が削減される(Hugging Faceからダウンロードしてラップトップ上で実行できるモデルは量子化されている)。
量子化においては、少ない方が良いことが多い。このため、生成AIでは、より精度の低い新しいフォーマット(FP16、BFLOAT16、FP8)が数多く導入されている。最も新しいもので、おそらく最も小さいのはFP4フォーマットである。つまり、浮動小数点数を4ビットで表現するということだ。
これらの低精度数値のフォーマットは、まだ定まっていない。X/Twitterのユーザ@fclc@mast.hpc.socialによる最近の投稿では、ブロック浮動小数点数を除外すると、FP8フォーマットは合計18種類になるという、さらに別のFP8フォーマットについてコメントしている。
FP4フォーマットに戻ろう。 コンピューターサイエンスの授業で注意を払っていなかった人向けに説明すると、4ビットでは16個の数値または重みのレベルしか表現できない。FP4は、正規化された数値、非正規化数値、符号付きゼロ、符号付き無限大、複数のNaN値など、IEEEの原則に従う最小の浮動小数点数である。これは、符号1ビット、指数2ビット、仮数1ビットの4ビット浮動小数点数である。-3から3までのすべての数値は、以下の表に示されている。列には符号ビットと仮数ビットの異なる値が示され、行には指数ビットの異なる値が示されている。
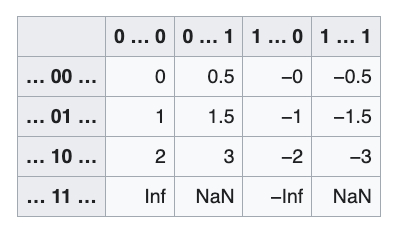 |
| FP4フォーマットで可能なすべての数値。(出典:Wikipedia) |
スーパーコンピュータのスペックシート
FP4は生成AIの最適化に優れており、量子化モデルによる推論を高速化できる。エヌビディアBlackwellアーキテクチャの技術概要では、テンソルコアFP4のレートは、高密度行列で理論上20ペタフロップスとされている。そして、ここから最近のエクサスケール、さらにはセッタスケールの発表につながる。
最近、4,608個のエヌビディアBlackwell GPUを使用して90エクサフロップスのマシンが構築されたという発表があった。単純な計算:20ペタフロップス x 4,608 GPU = 82,160エクサフロップス。そして、バーン!エクサフロップスマシンが完成した。この数値を算出するのにAIは使用されていないため、「AIエクサフロップス」という名称は重要ではない。
同様に、131,072個のエヌビディアBlackwell GPUを使用したゼタスケールマシンが発表された。 ここでも、20ペタフロップス x 92,160で1,843エクサフロップス(または1.8ゼタフロップス)となり、バーン!ゼタフロップスが誕生する。 繰り返しになるが、この未完成のマシンでAIが実行されたわけではないので、「AIゼタフロップス」と呼ぶのはおかしな話だ。
Blackwellのマシンよりもさらに印象的なのは、世界的なスマートフォン・スーパーコンピュータである。すべての電話が電話番号によって世界的なネットワークに接続されていると仮定すると、理論的にはそれらの演算能力を結合することができる。2024年6月現在、世界には約72億台(10億9000万台)のスマートフォンがあり、平均的な携帯電話のプロセッサは単精度演算で約10テラフロップス(10億1200万フロップス)の処理能力がある。「FLOPSを足し算する」という方法を用いれば、10^21 FLOPS、つまりゼタFLOPSを誇るスマートフォン・スーパーコンピュータが誕生する。バーン!ゼタFLOPSがみんなのものになる。
もちろん、TOP500リストにランクインする前に、いくつかの細かい点を解決する必要がある。ところで、あなたの携帯電話が理由もなく熱くなってきたら、それはHPLinpackを実行しているか、あるいは、あなたがダウンロードしたばかりの楽しい新アプリの一部として暗号マイニングを実行している可能性が高い。
自動車に例えると
優れた議論には、自動車に例えることが必要だ。FP4コンピューティングの場合、次のような例えになる。平均的な倍精度FP64自動車の重量は約4,000ポンド(1814キロ)である。地形のナビゲーションに優れ、4人を快適に収容でき、燃費は30MPGである。さて、重量250ポンド(113キロ)にまで軽量化されたFP4車は、驚異的な480MPGを実現している。
素晴らしいニュースだ。これまでにない最高の燃費性能だ!ただし、あなたの素晴らしいFP4車のいくつかの特徴については触れられていない。
まず、この車は小型エンジンとシート以外はすべて取り除かれている。さらに、車輪は16面(2の4乗)で、2の64乗前後の面を持つ車輪を備えたFP64セダンのスムーズな乗り心地と比較すると、ガタガタした乗り心地だ。FP4カーがうまく機能する場所もあるかもしれない。例えば、推論レーンをクルーズするような場合だ。しかし、FP64 HPC高速道路ではうまく機能しないだろう。人によって好みは異なる。
今後
スペックシートに記載されているエクサスケール数値は、しばしば「AI ExaFLOPS」として報告されるが、これではエクサスケールであるとは認められない。エクサスケール・クラブの仲間入りをするには、次の情報を提供する必要がある。
- FLOPSレートを測定するために使用したハードウェアとアプリケーション
- 測定に使用した浮動小数点の精度(FP64、FP32、FP6、FP4など)
特定の精度における非計算数値(スペックシートの合計値)を「理論上のピーク」と表現するのは良い方法だが、それだけではクラブには入れない。「AI FLOPS」で誤魔化しても意味がない。エヌビディアBlackwellは非常に高速なGPUであり、前述の簡単な詳細情報を添えて実際の測定値を提供すれば、クラブへの入会は容易である。
特別イベント

寄稿者
![]() 西克也
西克也
西克也はフェアチャイルド社、クレイ・リサーチ社、ベストシステムズ社など、30年以上に渡ってHPCに関する仕事に従事している。Hpcwire Japanの編集長として記事の作成と翻訳を行っている。
![]() 島田佳代子
島田佳代子
1999年~2007年まで英国在住。2001年よりスポーツ、旅、ビジネス、映画など幅広いジャンルで執筆活動を開始し、Hpcwire Japanでは主に日本のHPC業界が世界に誇る研究者、開発者の方々のインタビューを担当。
![]() 小柳義夫
小柳義夫
小柳義夫氏は40年以上に亘ってHPCに携わってきた研究者であり、日本のHPC業界における生き字引として有名。現在 高度情報科学技術研究機構に所属し、産業界のHPC推進にあたっている。
![]() 小西史一
小西史一
小西史一は、理化学研究所、東京工業大学においてHPCおよびバイオインフォマティクスに関する研究と教育に携わってきた研究者。2012年からフォトグラファーとしての活動を開始し、現在はIT技術・セキュリティのコンサルティング業務に携わっている。