
HPCの歩み50年記事一覧

スパコンリスト日本

記事寄稿について

MLPerf、HPCトレーニングベンチマークを発表
John Russell

AIベンチマーク組織MLPerf.orgは昨年、最初のHPCトレーニング実行であるMLPerf HPC Training v0.7の結果を発表し、HPC中心の水域に足を踏み入れた。CosmoFlowとDeepCAMモデルを含むこの新しいスイートは、大規模な高性能コンピューティングシステム上での機械学習のパフォーマンスを測定することを目的としている。
第一回目のエントリー数は少なかったが、過去2回のTop500リストでトップの成績を収めた富岳(理化学研究所)、Piz Daint(CSCS)、Cori(ローレンスバークレー国立研究所)、Frontera(テキサス先端計算センター)、AI Bridging Cloud Infrastructure(ABCI、富士通)、HAL cluster(米国立スーパーコンピュータ応用研究所)など、印象的なHPCシステムを代表するシステムが揃っていた。
MLPerfの「標準」トレーニングベンチマークから、HPC演習のためのいくつかの重要なルール変更があった。解答までの時間は依然としてメリットの指標だが、MLPerfは(主に)プロセッサ性能以外のボトルネックを含めるように努力している。参加しているHPCシステムの規模と複雑さから、適切な性能評価のためには結果の詳細を掘り下げる必要がある。とはいえ、今日の MLPerf の発表の中でも特に興味深いのは、参加者が MLPerf の作業について述べていることだ(以下を参照)。例えば、バッチサイズがどのような要因であったかは興味深いものである。
NERSCのエンジニアであり、HPCベンチマークの開発を主導するMLPerfチームのメンバーであるSteven Farrellは、「HPCのルールはMLPerfのトレーニングとは少し異なります。例えば、一般的な並列ファイルシステムからローカルストレージやI/Oアクセラレータタイプのシステムへの前処理の一部としてのデータ移動は、ベンチマークの報告時間に含まれなければなりません。そして実際には、このステージングプロセスに費やされた時間をキャプチャしました。」
「結局のところ、MLPerf HPC の結果の表示方法では、1 位、2 位、3 位といった厳密なランキングは表示されません。判断するためには、使用されているシステムの規模をある程度理解した上で結果を解析する必要があります」とFarrellは述べている。MLPerfは、スライスとダイシングのためのデータへの簡単なアクセスを提供する。
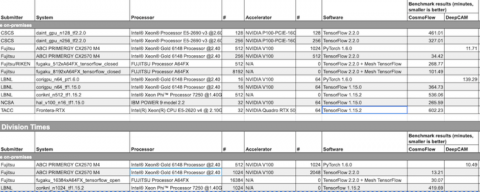
クローズド部門のCosmoFlowのトップはABCIで34.2分、最下位は富岳で101.49分だった。オープン部門ではABCIが13.21分でトップだった。クローズド部門は規制が厳しく、オープン部門はより柔軟にベンチマークを走らせることができるのだ。
MLPerfのエグゼクティブディレクターであるDavid Kanterは、「HPCトレーニングは、スーパーコンピュータとサイト固有のベンチマークと考えています。一方、MLPerfのトレーニングは、よりベンダーに特化したものになる傾向があります。HPCのトレーニングでは相互接続が非常に重要であることを示す多くの分析結果があり、その側面がベンチマークに反映されることを心から願っています。」
 |
MLPerfの長期的な希望により、HPCトレーニングスイートは実世界のアプリケーションを使用している。最初の2つのベンチマークでは、気候分析や宇宙論に関連するタスクにおいて、新しい科学的機械学習モデルを標準的な品質目標まで訓練するのにかかる時間を測定する。どちらのベンチマークも、トレーニングデータを生成するために大規模な科学的シミュレーションを利用している。
- CosmoFlow: 4つの宇宙パラメータターゲットを予測するために、N-body宇宙シミュレーションデータ上で訓練された3D畳み込みアーキテクチャ。
- DeepCAM: CAM5+TECA気候シミュレーションデータを用いて、大気河川や熱帯低気圧などの異常気象を識別するための畳み込みエンコーダー/デコーダーセグメンテーションアーキテクチャ。
HPCスイートで使用されているモデルとデータは、従来のMLPerfトレーニングベンチマークとは大きく異なる。例えば、CosmoFlowは、一般的に画像分類器の訓練に用いられる2Dデータではなく、体積(3D)データを用いて訓練されている。
同様に、DeepCAMは768 x 1152ピクセルと16チャンネルの画像で訓練され、ImageNetのような標準的なビジョンデータセットよりも大幅に大きい。どちらのベンチマークも大規模なデータセットを持っており、DeepCAMの場合は8.8TB、CosmoFlowの場合は5.1TBとなっており、ストレージとインターコネクトのパフォーマンスを明らかにする重要なI/Oの課題をもたらす。
より一般的には、MLPerf HPC v0.7 は MLPerf Training v0.7 のルールに従っている。前述したように、1つの例外として、HPCシステムにおける大規模なデータ移動の複雑さを把握するための努力がある。並列ファイルシステムから加速および/またはオンノードストレージシステムへのすべてのデータステージングは、測定されたランタイムに含まれなければならない。
注目すべきは、DeepCAMベンチマークの結果を提出した参加者は2名のみであり、今回の第1回MLPerf HPCトレーニングの参加者は少なかったものの、「数千から数万のプロセッサ上でデータ並列、モデル並列のトレーニング技術を利用して、大規模な科学的問題をトレーニングするためのスーパーコンピュータの最先端の能力を披露しました」とFarrellは述べている。
Nvidiaのスーパーコンピュータ「Selene」が参加しなかったのは興味深い。Kanterによると、COVID関連の研究のために非常に多くのHPCシステムが稼働を余儀なくされているため、COVID-19のパンデミックは参加を抑える上で問題になっている可能性が高いという。MLPerfは新しいHPC指標に大きな期待を寄せているが、それを確立するには時間がかかるかもしれないと認識している。計画では、モデルを追加し、おそらく年2回のペース(ISCとSCの前後)に従うことを求めているが、それは不確実である。
Kanterは、次のように述べた。「これはある種の需要に基づいています。HPCトレーニングが登場する前に、私たちは入札の適格性と承認のためにMLPerfトレーニングを使用することに興味を持っているいくつかのスーパーコンピューティングセンターから話を持ちかけられました。この時点で、10億ドル以上の入札でMLPerfのコンポーネントが入札プロセスで使用されていると思います。今後はもっと増えていくことを期待しています。」
「率直に言って、私たちが業界に提供できる価値の一つは、営業、マーケティング、エンジニアリングの連携を図り、人々が正しい測定基準を使用しているかどうかを確認することです。」
CSCS
スイス国立スーパーコンピューティングセンター(CSCS)は、科学分野におけるMLワークフローをサポートする将来のシステムのニーズを特定するためのベンチマークイニシアチブの一環として、第1回MLPerf HPCトレーニングラウンドに参加した。我々は、Piz Daint上のCosmoFlowを用いた2つのデータ並列送信に焦点を当て、128と256のGPUを用いて、各ノードに1つのGPUを搭載した。Docker対応コンテナにネイティブに近い性能を持つコンテナエンジンであるSarusを使用することで、100〜1000ノードの範囲でほぼ最適な弱スケーリングを実現するために、HorovodとNCCLを用いた分散訓練のための微粒通信のテストとチューニングを迅速に行うことができた。
不思議なことに、エポックあたりの実行時間は、128 GPUから256 GPUへと理想よりも12%速くなった。このスケーリングは、256 GPUではRAMにデータセットをキャッシュできるのに対し、128 GPUでは並列ファイルシステムI/Oがオーバーヘッドになる。このオーバーヘッドは、ニアコンピュートストレージを使用することで軽減することができる。アルゴリズム的には、閉分割ルールの下でのCosmoFlowのデータ並列スケーラビリティの限界を実証している。具体的には、システムが128GPUから256GPUにスケールアップすると、収束するエポック数は約1.6倍にスケールアップするが、32GPUから128GPUにスケールアップすると、エポック数は約1.3倍にしか増加しない。さらに、標準偏差は7倍に増加し、モデルの学習が困難になる。以上のように,我々はHPCシステム上でのMLの最適化の鍵となるのは、きめ細かな通信とニアコンピュートストレージの追加であることを確認した。
富士通
AI Bridging Cloud Infrastructure(ABCI)は、独立行政法人産業技術総合研究所(AIST)が構築・運用する世界初の大規模オープンAIコンピューティングインフラストラクチャである[1]。ABCIシステムは、2,176台のIntel Xeonスケーラブルプロセッサ(Skylake-SP)、4,352台のNVIDIA Tesla V100 GPU、デュアルレールのInfiniband EDRインターコネクトを搭載している。富士通は産総研と富士通研究所と共同で、CosmoFlowおよびDeepCAMの結果を提出した。CosmoFlowでは128ノード(512 GPU)をクローズド分割、512ノード(2,048 GPU)をオープン分割に使用した。データセットをtar.xzファイルに再フォーマットし、データのステージング時間を短縮するとともに、以下の性能最適化を行い、トレーニングのスループットを向上させた。(1) NVIDIA Data Loading Library (DALI)を用いたデータローダのスループット向上、(2) 混合精度トレーニングの適用、(3) 検証バッチサイズの増加。また、オープン分割については、以下の精度向上技術を適用した。(1)線形学習率減衰スケジューラの使用、(2)データ拡張の適用、(3)ドロップアウト層の無効化。これらの技術により、バッチサイズを512から2,048に増加させることができ、実行時間を2.61倍に短縮することができた。
DeepCAMでは、256ノード(1,024GPU)がクローズドとオープン分割に使用された。データセットをtarファイルに再フォーマットしてデータのステージング時間を短縮し、ノード内マルチGPU間での分散データシャッフルを適用し、収束までのエポック数を減らすためのウォームアップステップを含むハイパーパラメータの調整を行った。オープン分割では、富士通研究所が開発したコンテンツアウェアコンピューティング(CAC)技術の一つであるGradient Skipping(GradSkip)技術を適用した。GradSkipは、学習中のデータの内容を自動解析し、精度に影響の少ない層を見つけることで、学習中の一部の層の重みの更新を回避するものである。
富士通+理化学研究所
理化学研究所と富士通は、2021年のフル稼働を目指して、幅広いアプリケーションソフトに対して高い有効性能を実現する世界最高水準のスーパーコンピュータ「富岳」を共同開発している。理化学研究所と富士通は富士通研究所と共同で、512ノードと8,192ノードを用いたクローズド分割と16,384ノードを用いたオープン分割のCosmoFlowの結果を提出した。データセットをtar.xzファイルに再フォーマットしてデータのステージング時間を短縮し、LLIO(Lightweight Layered IO Accelerator)を利用して一時的なローカルファイルシステムをプロセス内で活用した。A64FXの性能を最大限に引き出すために、最適化されたoneAPI Deep Neural Network Library (oneDNN)が開発された。
4,096を超えるバッチサイズでは精度が目標に到達できなかったため、データとモデルのハイブリッド並列を適用するモデル並列が導入された。TensorFlowのモデル並列は、Mesh TensorFlow(MTF)をベースに拡張し、データとモデルのマルチプロセス並列化を可能にした。Conv3d層では、2次元の空間分割によりモデル並列が適用された。ハイブリッド並列化により、クローズド分割で8,192、オープン分割で16,384(富岳の約1/10)までCPU数をスケーリングすることが可能となった。
LBNL
MLPerf HPCは、ローレンスバークレー国立研究所のNational Energy Research and Scientific Computing (NERSC)センターにとって、今後数年間で増大する科学AIワークロードに備えるための重要な機会である。バークレー研究所は、現在のベンチマークのベースとなっているDeepCAMとCosmoFlowという公開された科学的アプリケーションを共同で主導した。今回の第1ラウンドでは、NERSCのスーパーコンピュータCoriで測定された結果を提出し、KNLとGPUパーティションの両方で、それぞれ最大1024ノードと64GPUまでのデータ並列トレーニング能力を実証した。MLPerf HPC v0.7への参加は、2021年にオンライン化されると発表された次のマシンであるPerlmutterに向けて、AIベンチマーク戦略を標準化するための重要な一歩となった。
NCSA
National Center for Supercomputing Applications (NCSA)のInnovative Systems Lab (ISL)の目標の一つは、AI研究コミュニティが関心を持つ新しいハードウェアおよびソフトウェアシステムを評価することである。MLPerf HPCは、このような評価を行うための優れたツールを提供する。今回のベンチマークでは、IBM POWER9 CPUとNVIDIA V100 GPUをベースにしたHardware-Accelerated Learning(HAL)クラスタで得られた結果を提出した。 このシステムは、オールフラッシュDDNストレージアレイとEDR InfiniBandインターコネクトに裏打ちされた16のIBM AC922ノードで構成されており、クラスタ全体で優れた分散学習能力を発揮している。 MLPerf HPC v0.7プロジェクトに参加している間、将来のシステム設計に役立つ重要な経験を積むことができた。
TACC
Texas Advanced Computing Center(TACC)は、世界で最もパワフルなコンピューティングリソースのいくつかを設計・運用しています。同センターの使命は、高度なコンピューティング技術を応用することで科学と社会を進歩させる発見を可能にすることにあります。CosmoFlow のような MLPerf HPC アプリケーションは、次世代の ML および DL アプリケーションの要件を理解する貴重な機会を提供している。TACCはMLPerf HPC v0.7に参加し、Frontera RTXパーティション上の64 GPUでのCosmoFlowアプリケーションの性能を提出した。学んだ教訓は、広大に成長するAIコミュニティの利益のために、将来のTACCシステムのアーキテクチャを導き出すために使用される。
MLPerfの結果へのリンク:https://mlperf.org/training-results-0-7
MLPerfの発表へのリンク:https://mlperf.org/press#mlperf-hpc-v0.7-results
特別イベント

ISC 2026
6月 22 - 6月 26
International Conference for High Performance Computing, Networking, Storage & Analysis (SC26)
11月 15 - 11月 20
寄稿者
![]() 西克也
西克也
西克也はフェアチャイルド社、クレイ・リサーチ社、ベストシステムズ社など、30年以上に渡ってHPCに関する仕事に従事している。Hpcwire Japanの編集長として記事の作成と翻訳を行っている。
![]() 島田佳代子
島田佳代子
1999年~2007年まで英国在住。2001年よりスポーツ、旅、ビジネス、映画など幅広いジャンルで執筆活動を開始し、Hpcwire Japanでは主に日本のHPC業界が世界に誇る研究者、開発者の方々のインタビューを担当。
![]() 小柳義夫
小柳義夫
小柳義夫氏は40年以上に亘ってHPCに携わってきた研究者であり、日本のHPC業界における生き字引として有名。現在 高度情報科学技術研究機構に所属し、産業界のHPC推進にあたっている。
![]() 小西史一
小西史一
小西史一は、理化学研究所、東京工業大学においてHPCおよびバイオインフォマティクスに関する研究と教育に携わってきた研究者。2012年からフォトグラファーとしての活動を開始し、現在はIT技術・セキュリティのコンサルティング業務に携わっている。