
HPCの歩み50年記事一覧

スパコンリスト日本

記事寄稿について

DEEPの地震波イメージング
Tiffany Trader
エクサスケールは、以前の指数関数的なコンピューティング特性よりもはるかに大きな課題を提示するとともに、統合的、協調的アプローチがますます必要となっている。エクサスケール・コンピューティングのための協調的な資金調達活動は、多くが期待していたよりも少し遅れて来たが、欧州プロジェクトのDEEPを含め、現在進行中の幾つかの国際的な活動がある。
DEEPはDynamical ExaScale Entry Platformの略で、EUの第7次フレームワークプログラムによって資金供給される3つのエクサスケール有効化プロジェクトのひとつである。3年間のプロジェクトは、2011年12月に始まり、チューリッヒ総合研究機構のチューリッヒスーパーコンピューティングセンターによって提供される調整で8カ国から16のパートナーが含まれている。 DEEPは、脳研究、気候学や地震学に含まれる幅広いアプリケーションにおよぶ。
アプリケーション開発者のMarc Tchiboukdjianは、最近、DEEPシステムで彼のチームの経験に関連する記録を行ってきた。フランスを本拠とする地球物理サービス会社、CGGのITアーキテクト、Tchiboukdjianは、彼のチームは彼らの地震イメージングアプリケーションを実行するために最も適切なハードウェアを選択する責任があると言う。それから、彼らは、選択したハードウェア上でこれらのアプリケーションを最適化するために他のチームと内部的に協力している。DEEPプロジェクトでは、チームは現在、複雑な地質学地震波の伝播を理解するために使用するTTI-RTM(tilted transverse isotropic reverse time migration)モジュールがどのように分析しているか、DEEPアーキテクチャ上で実行している。
地震イメージングワークロードのためのエクサスケール・コンピューティングの必要性について尋ねられ、Tchiboukdjianは、地震データ処理とイメージングアルゴリズムが実際にコンピューティングの限界に挑戦しており、エクサスケールシステムへのアクセスが与えられた場合には、とても多くのことを行うことができると応じた。彼は加えて、将来の処理要求は、2つの主なドライバーを持っている:「フィールドにおける改善されたデータ取得技術が、周波数コンテンツの増加等のより多くの情報を持つ数百万のトレースで生成されるより巨大なデータセットになります。さらに、地震アルゴリズムもまた改善し、速度モデルを改善するためのモデリングエンジンとFull-Waveform Inversionでの波動伝播のためのより正確な物理学が含まれます。」
Intel PhiのようなコプロセッサやGPUのようなアクセラレータを介する異種コンピューティングは、「エクサスケール」コンピューティングを可能にするモノのひとつとして見られている。CGGでの現在のプロダクションシステムは、GPUクラスタに基づいており、Tchiboukdjianは、GPUアクセラレータノードはGDDRメモリの高いバンド幅があるため、RTM(Reverse Time Migration)に非常に適していると話した。さらに言うとTchiboukdjianは、Intel Xeon Phiは高いメモリバンド幅を持っているため、同様に良好な候補である可能性があることを確信している。
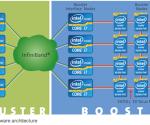
DEEPプロジェクトは、その「クラスターブースターアーキテクチャ」としてのPhiチップの可能性を模索している。最終的なDEEPプロトタイプシステムは、128ノードのEurotech AuroraクラスタとIntel Xeon Phiコプロセッサ(ブースターノード)で構成する512ノードブースターで構成され、EXTOLL高性能3Dトーラス•ネットワークによって接続される。
Tchiboukdjianは、そのアプローチの利点の幾つかを話す。「DEEPクラスタは、革新的で効率的な冷却戦略のおかげで高密度に提供します。」と彼は話す。 「それはまた、古典的なGPUアクセラレーションノードに比べてより柔軟性があります。クラスタノードとブースターノードを一緒に結ぶ高速ネットワークのおかげで、各アプリケーションのニーズに応じてホスト処理およびコプロセッシングの割合を動的に調整することができます。」
Tchiboukdjianはまた、DEEPプロジェクトのために採用された新しいソフトウェアスタックについてもコメントする。これは、ユーザーがXeon Phi上のコードの最もスケーラブルかつ計算負荷の高い部分を選択し、実行することを可能にする革新的なアプローチ(OmpSsの修正版に基づいて)を使用している。
Tchiboukdjianによると、今後のDEEPの次の反復は、CGGのアプリケーションニーズのためのより良い動作するはずのアップグレードが含まれる。来たる第二世代のIntel Xeon Phiは、より多くのメモリを持ち、そしてブースターノードは不揮発性メモリを使用するので、RTMをスムーズに実行するために十分なローカルのスクラッチバンド幅があるだろう、と彼は付け加えた。
特別イベント

寄稿者
![]() 西克也
西克也
西克也はフェアチャイルド社、クレイ・リサーチ社、ベストシステムズ社など、30年以上に渡ってHPCに関する仕事に従事している。Hpcwire Japanの編集長として記事の作成と翻訳を行っている。
![]() 島田佳代子
島田佳代子
1999年~2007年まで英国在住。2001年よりスポーツ、旅、ビジネス、映画など幅広いジャンルで執筆活動を開始し、Hpcwire Japanでは主に日本のHPC業界が世界に誇る研究者、開発者の方々のインタビューを担当。
![]() 小柳義夫
小柳義夫
小柳義夫氏は40年以上に亘ってHPCに携わってきた研究者であり、日本のHPC業界における生き字引として有名。現在 高度情報科学技術研究機構に所属し、産業界のHPC推進にあたっている。
![]() 小西史一
小西史一
小西史一は、理化学研究所、東京工業大学においてHPCおよびバイオインフォマティクスに関する研究と教育に携わってきた研究者。2012年からフォトグラファーとしての活動を開始し、現在はIT技術・セキュリティのコンサルティング業務に携わっている。