
HPCの歩み50年記事一覧

スパコンリスト日本

記事寄稿について

NVIDIAのHPC開発の方向性をNVIDIAの Steve Keckler が講演
スポンサー記事
NVIDIA Researchのアーキテクチャ研究部門を率いるVP(バイスプレジデント)のSteve Keckler氏が,NVIDIA 秋のHPC Weeksの発表で,次世代のHPCテクノロジについて講演を行った。
 |
| NVIDIA 秋のHPC Weekの一連の発表の中で,NVIDIAのアーキテクチャ研究部門を担当するVPのSteve Keckler氏がHPCの研究,開発の方向性について講演を行った。写真が小さいが右上がKeckler氏である。 このレポートの全ての図はKeckler氏の発表スライドのコピーである。 |
Keckler のチームは,次世代のコンピューティングアーキテクチャの研究を行っている。HPCは航空宇宙,医薬の発見,物質科学,デジタルツインを使った工業的な製造,天気予報,高精度の物理シミュレーションを使った製造技術など各方面でブレークスルーを実現してきている次世代システムの重要な要素である。
 |
| 図2 工業分野でのHPCは色々な分野でブレークスルーを引き起こしている。 |
図3はGPUのGFlops性能をプロットしたもので,2010年のNVIDIA Fermi GPUと比べて2020年のNVIDIA Ampere GPUの性能は26倍になっている。このように,GPUの性能向上は,スーパーコンピュータの性能向上を後押しする重要な要素になっている。この性能向上は,ある程度は半導体の微細化によるものであるが,アーキテクチャの改善による性能向上が大きい。
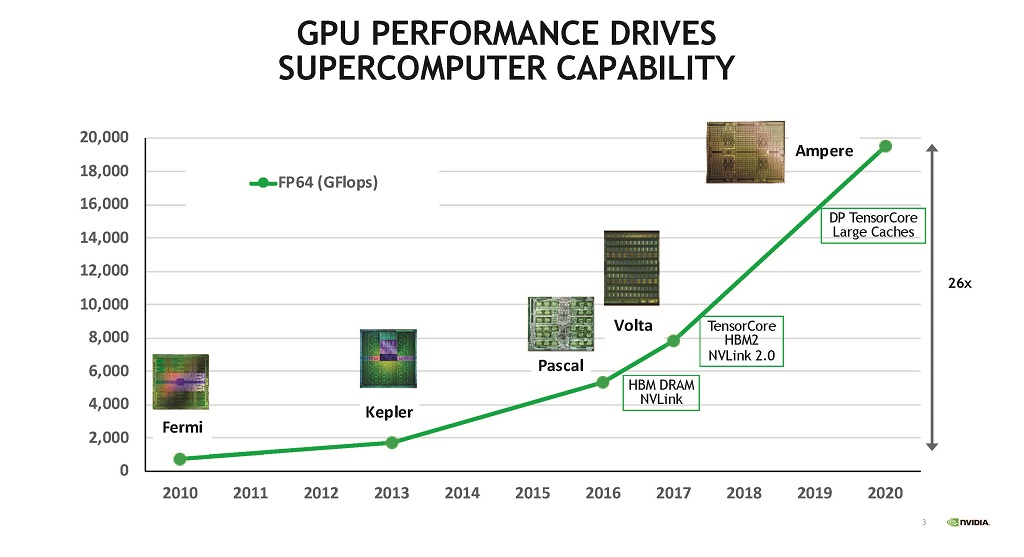 |
| 図3 GPUの性能向上がスパコンの能力向上を押し上げてきた。2010年のFermi GPUと比べると,2020年のAmpere GPUのFlops性能は26倍に向上している。 |
また,図4に示すように,この8年の間のマシンラーニング(Int8を使うML計算)の性能は317倍と驚くべき向上を遂げている。
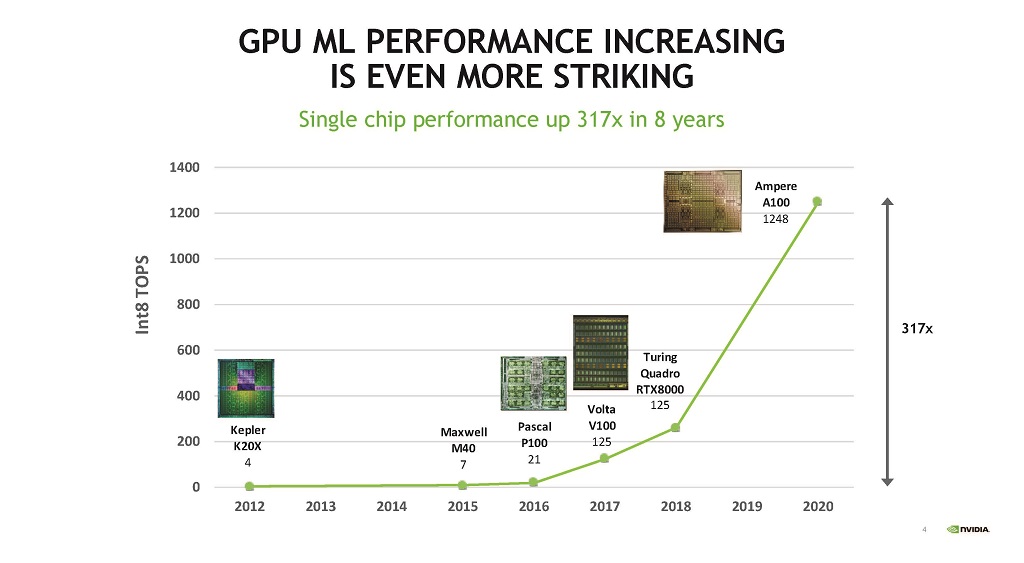 |
| 図4 GPUのML性能(8bit精度での整数演算)は2012年のKepler GPUと比べて2020年のAmpere GPUでは317倍の性能になった。 |
図5はNVIDIAが開発したSeleneスパコンの写真である。SeleneはNVIDIA A100 GPUを4480台使うシステムで,NVIDIA DGX A100サーバを560台,850台のNVIDIA Mellanox200Gb HDRのInfiniBandスイッチで接続している。そしてSeleneは全体として14PBのフラッシュストレージを持っている。
SeleneはTop500では倍精度の演算で63PFlopsの性能を持ち,世界6位。電力効率を競うGreen500では24GFlops/Wで11位となっている。また,MLではInt8で5.6ExaOpsという性能を誇っている。
 |
| 図5 NVIDIAのA100 GPUを4480台使用するSeleneスパコン。FP64で63PFlopsの性能を持ち,世界第6位の演算性能を誇る。Green500では11位。Int8のML計算では5.6ExaOpsの性能を持つ。 |
NVIDIA DGX SuperPODと名付けられたアーキテクチャのこのスパコンは3週間で組み立てることができるという。このため英国のCambridge-1や米国のプレエクサスパコンであるNERSCのPerlmutter,スイスのALPSスパコンでも採用されており,各社の商用のスパコンクラスタでも採用されている。NVIDIAによると,Top500の内の上位10位までのスパコンの中の8システム,Green500スパコンの上位10までのスパコンの内の9システム,HPL-AI性能の上位10スパコンの内の8システムがNVIDIAのソリューションを使っているという。
 |
| 図6 NVIDIAのSuperPodを使う世界の大規模スパコン。Top500の上位10システムの内の8システムがNVIDIAのソリューションを使うAIスパコンである。 |
従来のHPCは高精度の数値モデルを作り物理現象をシミュレーションして理解しようというアプローチが多く,FP64のような高精度の数値を使って偏微分方程式を解くというような計算法が主流であった。
しかし,最近では,マシンラーニングを利用して解を予測して,正しい解の探索を高速化するというアプローチが使われて成果を上げている。解の探索スペースが広い場合は,マシンラーニングで解の範囲を絞り込めれば精密な解を得る時間を大幅に短縮できる。マシンラーニングを使う計算の例としては1.13EFlosを必要とする異常気象の検出や,プラズマ核融合炉の不安定性の検出やコントロール,重力波望遠鏡の信号のノイズ除去などがある。重力波のノイズ除去は従来の方法と比べて5000倍高速のノイズ除去ができたとのことである。
 |
| 図7 伝統的にHPCは,高精度の計算でシミュレーションを行ってきたが,最近ではマシンラーニングを使って解を予測して計算時間を短縮するという全く異なるアプローチが計算時間の短縮に効果を上げている。 |
分子動力学計算におけるGPU利用は2000年頃に始まったが,計算量が膨大で,当初は100万原子くらいの対象しか計算することができなかった。しかし,コンピュータの高性能化などにより,現在では10億原子のプロトセルなどが扱えるようになってきている。
また,AIを使うと指数関数的に大きなモデルサイズが扱えるようになってきており,複雑な問題が扱えるようになってきている。分子動力学計算をGPUの計算能力とAI計算ハードウェアを組み合わせてウイルスがどのようにして人間に感染するかを,まるごと計算できるようになってきている。
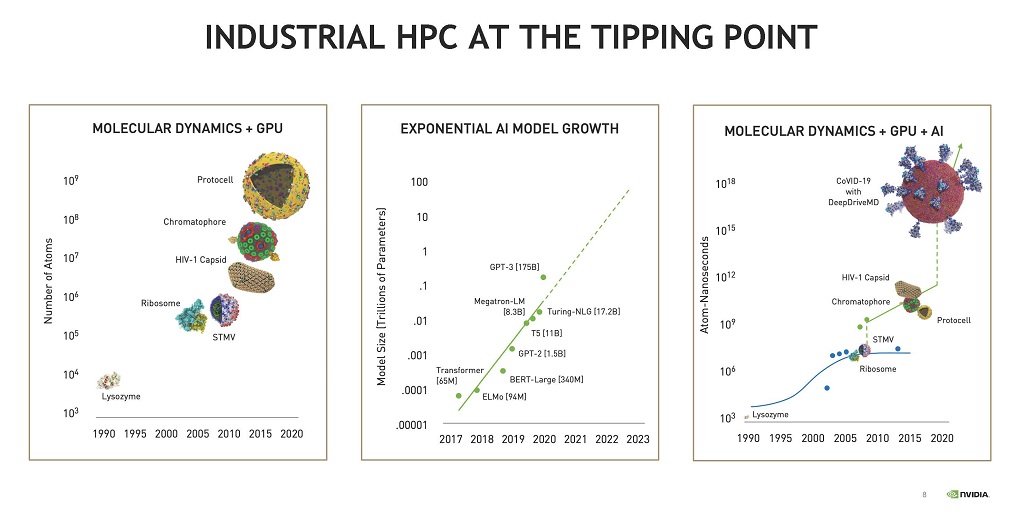 |
| 図8 GPUを使うことで,1000万原子程度の対象の計算ができるようになり,AI計算では1000億パラメタを超えるモデルが扱えるようになり,分子動力学とGPUとAIを組み合わせれば,1個のウイルスをまるごと扱えるようになってきている。このように,我々は,歴史的な転換点に差し掛かっている。 |
微細化による高性能化,密度の改善が必要になってきており,それに替わるスケーラブルなコンピューティングの方法を開発する必要がある。また,メモリのバンド幅と容量の増加は計算能力の改善には必須である。そして,システムの規模が大きくなるとインタコネクトのバンド幅と効率が重要となる。そして,巨大な計算にはヘテロジニアスな計算法の採用や巨大なスケーラビリティーが必要となる。
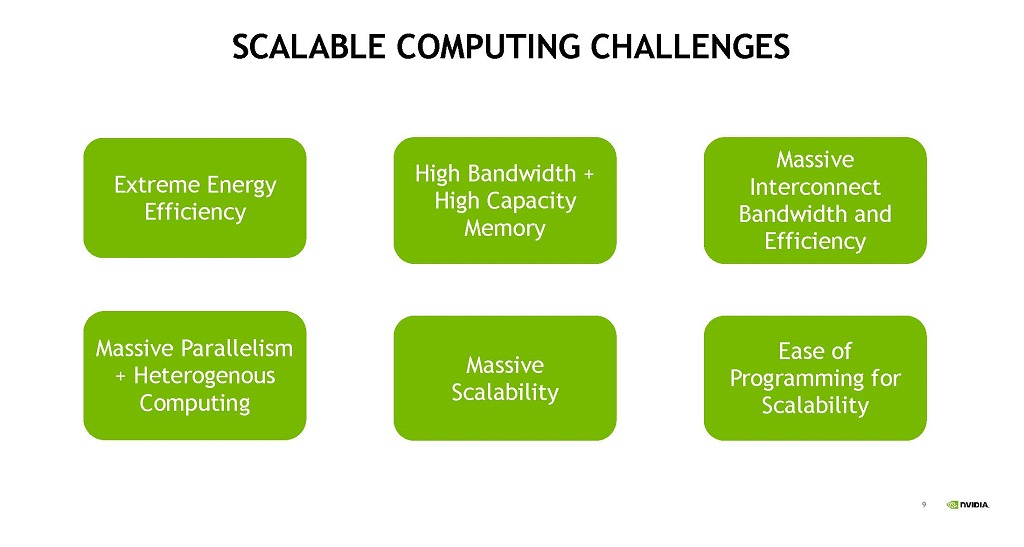 |
| 図9 スケーラブルな計算を行うためには,卓越したエネルギー効率,高いメモリバンド幅と大きなメモリ容量,大きなインタコネクトバンド幅と効率,巨大な並列性と ヘテロジニアスな計算処理,巨大なスケーラビリティー,スケーラブルなプログラムの作り易さなどが重要である。 |
HPCのアプリケーションとしては,気候計算のようなアプリケーション,物理シミュレーション,パターン認識などがある。それらの問題を解くには,マシンラーニングや連立方程式,ビッグデータなどが必要となる。そして,それらの計算には必要に応じて密なテンソル,疎なテンソル,グラフ解析などの計算が使われる。
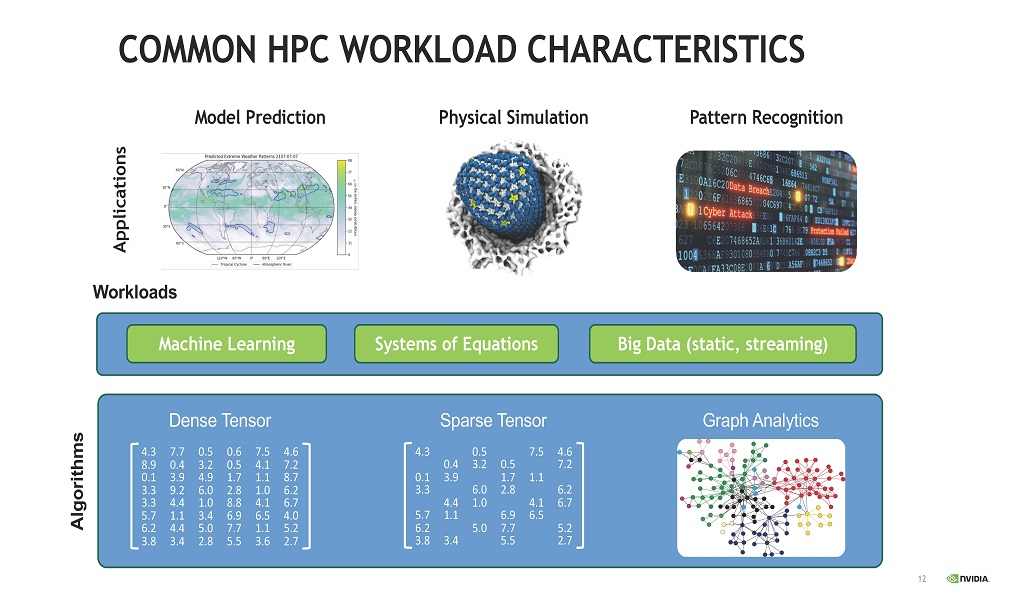 |
| 図10 一般的なHPCのワークロード マシンラーニング,連立方程式,ビッグデータなどのワークロードがあり,密なテンソル,疎なテンソルグラフ解析のデータなど各種のデータを扱う必要がある。 |
古典的なノイマン型のプロセサは,プログラムカウンタで指されるプログラムで制御される。そして,ソフトウェアでデータ構造を追いかけ,ロード・ストアでメモリをアクセスする。この構造ではメモリアクセスと計算は密に繋がっている。メモリ階層でいうと,コンピュートが一端にあり,DRAMが他端にあるという構造である。
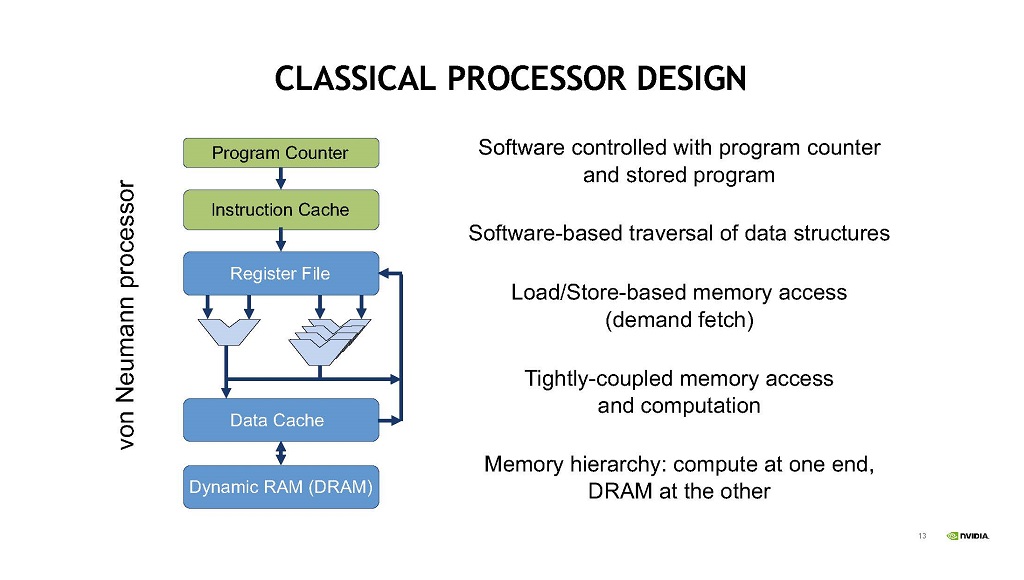 |
| 図11 古典的なプロセサの構造 ソフトウェアでメモリ上のデータ構造を辿る。ロード/ストアによるメモリアクセス,一端にコンピュートがあり,他端にDRAMがある構造 |
しかし,この構造は,命令フェッチ,デコード,実行が分散しており,メモリアクセスのレーテンシが長く大きなメモリが必要になる。固定構造のベクトルユニットであるので,効率が悪い。不必要なデータまで動かす必要があり,局所性が小さいデータを遠くまで動かしてしまう。などの効率が悪いデータ移動が発生する。
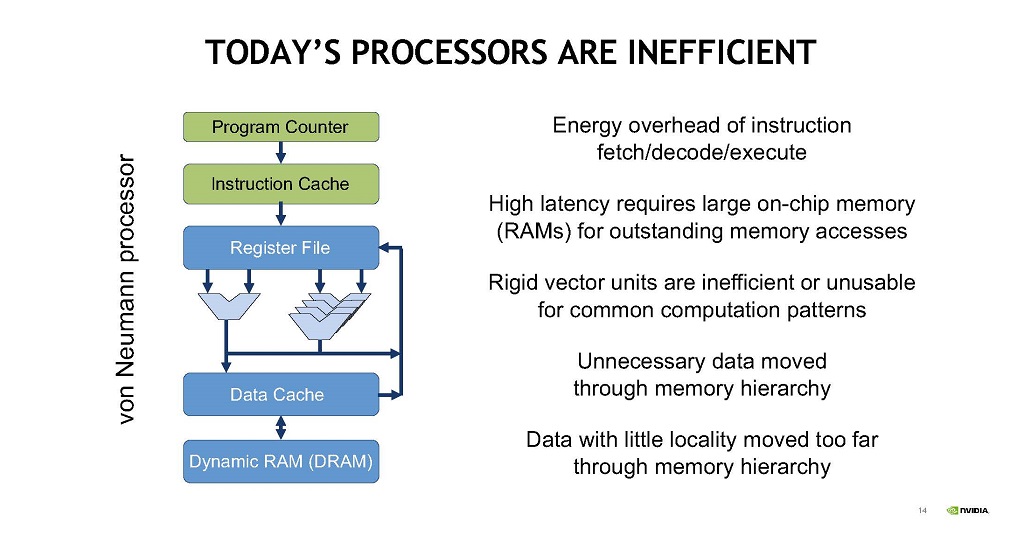 |
| 図12 無駄なメモリ移動が多く発生し,今日の構造のプロセサはデータ移動が多く,効率が悪い。 |
Symphonyアーキテクチャ
このような問題を解決するためNVIDIAのアーキテクチャチームはSymphonyというアーキテクチャを考案した。
NVIDIAのSymphonyアーキテクチャではデータ処理ユニットをCompute TileとData Orchestration Tileに区別し,Compute Tileはフレキシブルな並列数値演算ユニットを構成し,Data Orchestration Tileはデータの演算を制御する。説明が少なく,どのように動作するのか十分に理解できないが,分散型で演算するデータの組み合わせを制御する分散型データオーケストレーションというアプローチの妥当性は理解できる。
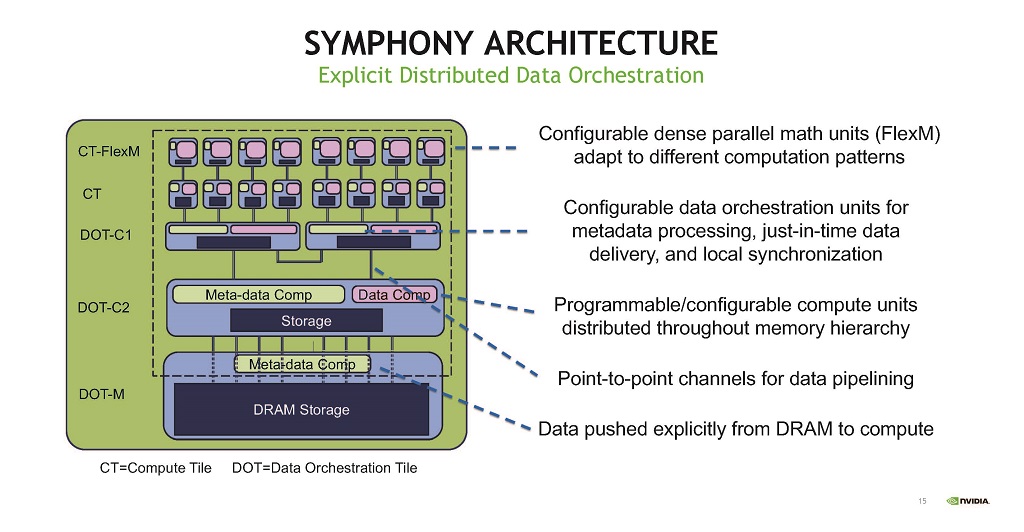 |
| 図13 Symphonyアーキテクチャではデータ処理を行うCompute Tileとデータの流れを制御するData Orchestraion Tileの2種のタイルを使う。 |
Data Orchestrationはそれぞれの楽器演奏者が,それぞれの楽器の演奏を行うように各演算器は,決められた演算を行う。そして,全ての楽器の演奏は楽譜(プログラム)によってどのように演奏するかが決められており,全体の演奏は識者が統率して,同期をとって実行される,というオーケストラの動きに似ている。
 |
| 図14 Symphonyでの実行の様子は多数の楽器を演奏する楽団の演奏の様子と似ている。 |
そして,楽譜のそれぞれのパートを,それぞれの楽器が担当するように,データをDOT(Data Orchestration Tile)に対応させると演奏が行われる。
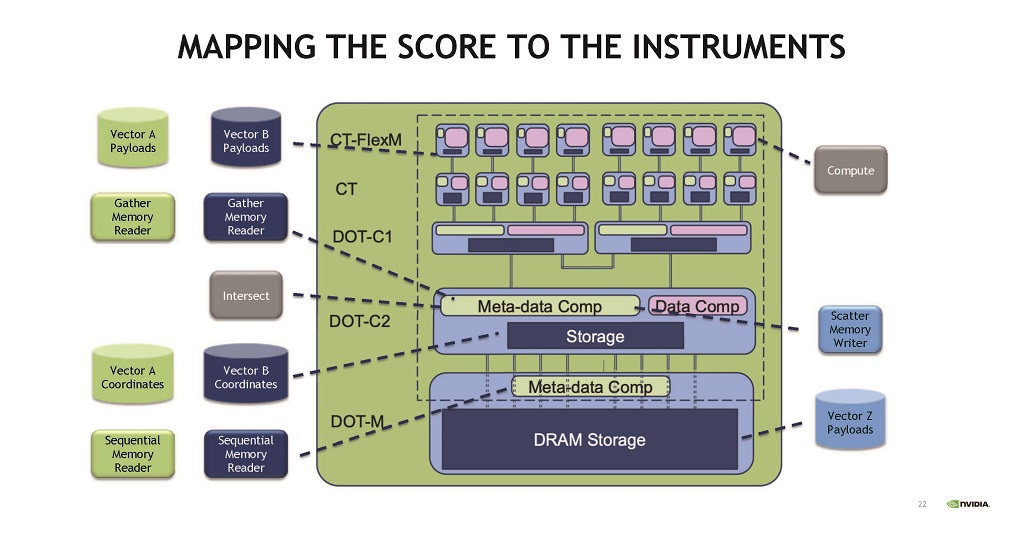 |
| 図15 SymphonyアーキテクチャではCompute Tile(CT)とData Orchestration Tile(DOT)がある。CTは演算を行い,DOTはメタデータ処理を行いデータの移動を制御する。 |
図16はSymphonyアーキテクチャの効率を示すグラフである。5つのペアの棒グラフは左からConvNet,GraphSAGE,IPNSW,PR-Nibble,Sinkhorm_wmdの実行時のもので,緑のグラフはNVIDIAのGV100 GPUのエネルギー効率を示す。そして,青色のグラフはSDH Symphonyのエネルギー効率を示している。
この図を見ると,Convolutionや密な線形代数の計算ではSymphonyの方が約10倍効率が高い。これは,FlexMathパイプラインの効率が高い点やプロデューサ・コンシューマパイプラインの効率が高いことが効いている。
そして,疎な線形代数やグラフアルゴリズムの処理は約100倍効率が高い。これは専用のストア手順を設けたこと,不必要なバッファの使用をバイパスしたこと,メモリに隣接した再構成可能なキャッシュを使用したことが効いていると思われる。
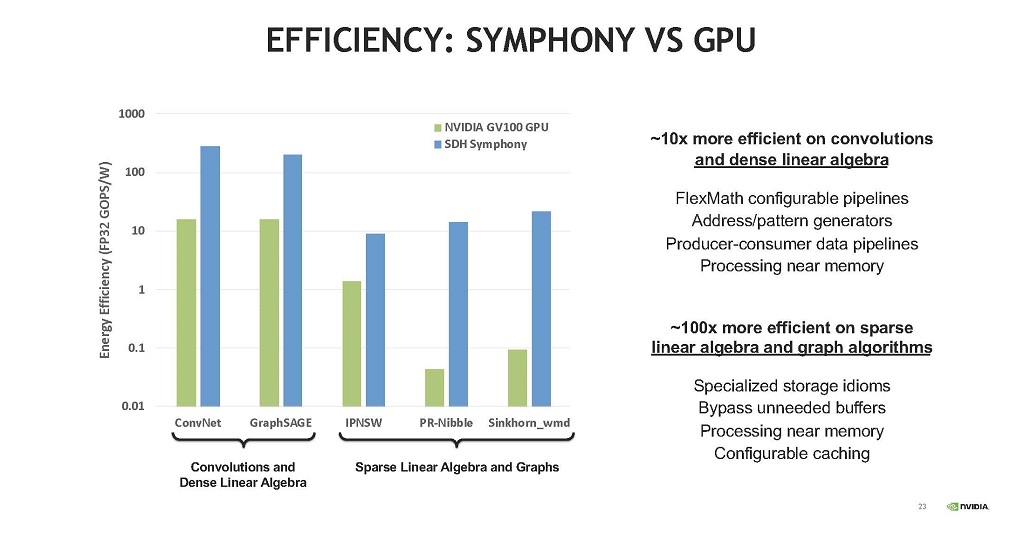 |
| 図16 SymphonyとGPUの効率の比較(緑のグラフがGV100 GPU,青のグラフがSDH SymphonyのGOPS/W値) |
メモリバンド幅とメモリ容量
マシンラーニングの処理ではメモリバンド幅とメモリ容量は重要なパラメタである。
A100 GPUはメモリとしてHBM2を使っており,2TB/sのバンド幅を持っている。しかし,もっとバンド幅が必要であり,その向上の必要性は留まるところを知らない状況である。メモリの消費電力は4pJ/bitで1.5TB/sの連続アクセスを行う場合には64Wの電力を消費する。従って,将来のスケーリングを考えると,メモリバンド幅は消費エネルギーの点で問題になり得る。
また,メモリ容量の点では,A100 GPUは80GBのHBM2メモリを搭載しているが,パッケージに搭載できるメモリ容量には制限がある。
 |
| 図17 メモリシステムの挑戦 バンド幅の点では,A100 GPUのメモリは2TB/sのHBM2であるが,より多くのバンド幅を要求されている。4pJ/bitで1.5TB/sのアクセスを連続で行うと64Wの消費電力となる。メモリ容量の点ではA100は80GBの容量をもっているが,アプリケーションとしてはもっとメモリが必要。 |
図18の緑線はFP64での演算性能の向上トレンドを示している。一方,青線はメモリバンド幅を示している。この図を見ると,10年間でGPUのFP64演算性能は26倍に向上しているがメモリバンド幅は11倍にしか増えていない。ということで,メモリバンド幅と演算性能のギャップは広がるばかりである。
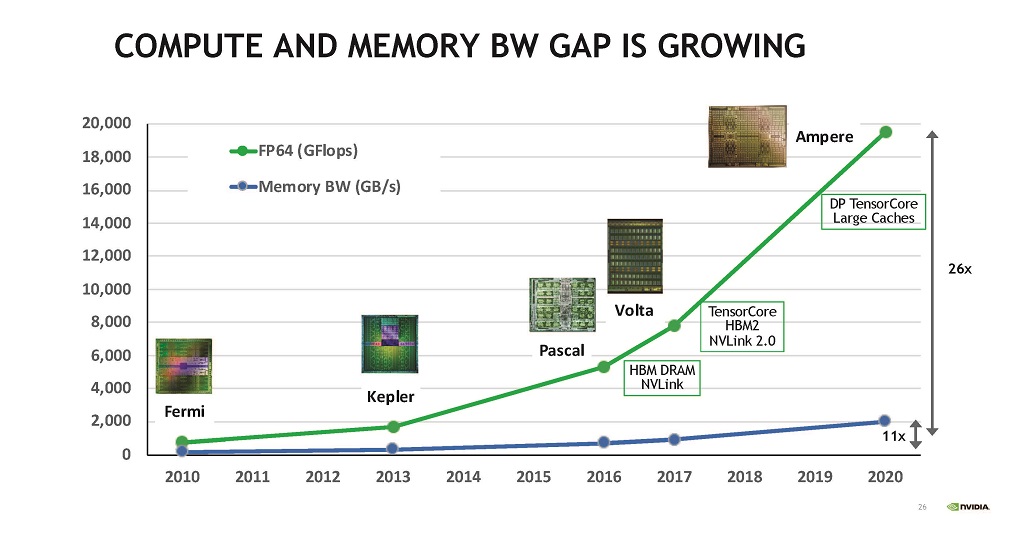 |
| 図18 GPUの演算とメモリバンド幅のギャップは増大の一途である。2010年から2020年の間にFlops性能は26倍になったがメモリバンド幅は11倍の増加に留まっている。 |
 |
| 図19はAmpere GPUのモジュールの写真である。中央のNVIDIAロゴのついている銀色のチップがA100 GPUである。A100 GPUの大きさは826mm2で,FP64での演算性能は19.5TFlopsである。HBM2メモリの容量は80GBとなっている。そして,メモリバンド幅(B/s)と演算性能(Flop/s)の比は1:10となっている |
図19はAmpere GPUのモジュールの写真である。中央のNVIDIAロゴのついている銀色のチップがA100 GPUである。A100 GPUの大きさは826mm2で,FP64での演算性能は19.5TFlopsである。HBM2メモリの容量は80GBとなっている。そして,メモリバンド幅(B/s)と演算性能(Flop/s)の比は1:10となっている。
多くのHPCアプリケーションではBand幅とFlop値の比を4:1程度にすることが望まれるが,これに対して,A100 GPUでは帯域が大幅に不足することになるということで,メモリバンド幅を増やすにはどうすれば良いであろうか?
DRAMバンド幅を増やす方法は?
一つの方法はHBMの1Gbpsの信号を→2Gbps→3.2Gbps→5.2Gbpsと速度を上げることである。第二の方法はインタポーザに載せるHBMの個数を増やすことであるが,GPUチップの周辺長で制約される。
DRAMの設計を変えて信号ピンを増やす,DRAMをGPUの上に積み重ねるという方法も考えられる。さらに,現状のメモリバンド幅をより有効に利用するという案も考えられる。
 |
| 図20 DRAMの実行メモリバンド幅を増やす手はないか?信号の速度を速くする。信号のピン数を増やすなどが考えられる。 |
メモリバンド幅を増やす方法として,現在より狭い幅のチャネルを使って細粒度のDRAMを作るという案がある。
現在のDRAMは図の左側の構成のようにチャネルごとに16個のバンクを持たせる。この構成ではアイドルのバンクは使われず,そのメモリバンド幅は無駄になってしまう。一方,各バンクから信号線を出して32個のローカルの2GB/sのチャネルに接続すれば,全てのアクセスで32個の2GB/sのローカルチャネルが使われる。
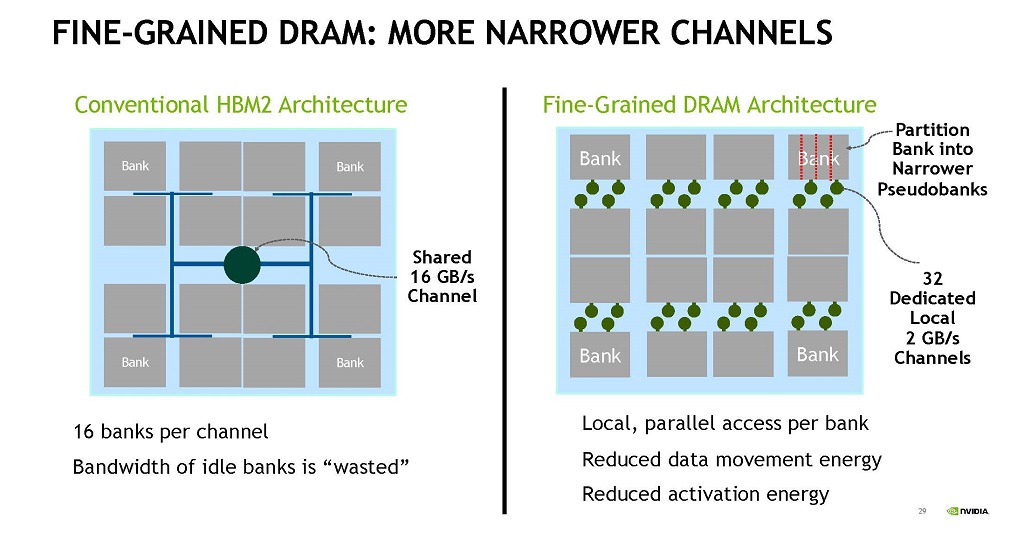 |
| 図21 左の図のバンクを細分化した疑似バンクを作り,32の2GB/sのチャネルを作る。チャネルが小さいので,アクティベーションやデータ移動に必要なエネルギーを小さくできる。 |
図21の右側の図のような粒度を小さくした疑似バンクを使えば,疑似バンクごとのアクティベーションエネルギーは小さくなり,バンクレベルの並列度が大きくなる。そして,コマンドレベルの並列度が大きくなる。結果として,DRAM読み出しのエネルギー(Pj/bit)は通常のHBMメモリと比べておおよそ半分に減少する。
結果として,バンクアクティベートが制約になる場合では1.4~2.5倍の性能が得られる。
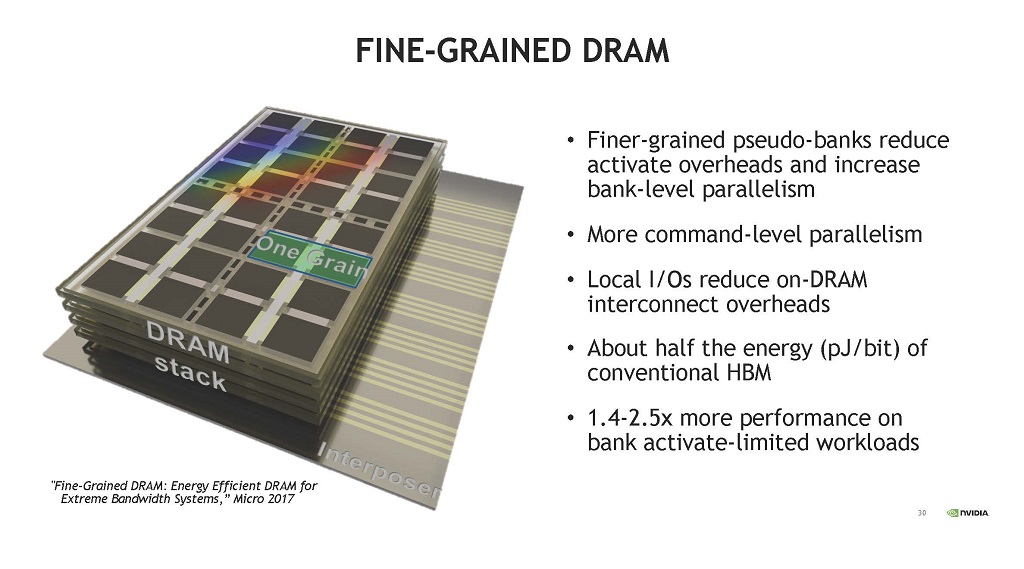 |
| 図22 DRAMを細粒度化すればアクティベーションオーバヘッドが減り,バンクレベルの並列性が増加する。通常のHBMのおおよそ半分のエネルギーで動作でき,バンクアクティベーションが制約になっている場合は1.4-2.5xに性能を引き上げられる。 |
更にメモリのバンド幅を上げられる方法が,DRAMをGPUの上に積み重ねるという方法である。これが出来ればB/F比を40倍改善することが可能であるが,高発熱の緑のGPUダイの上にDRAMを積み重ねるという難しい実装を実現する必要がある。
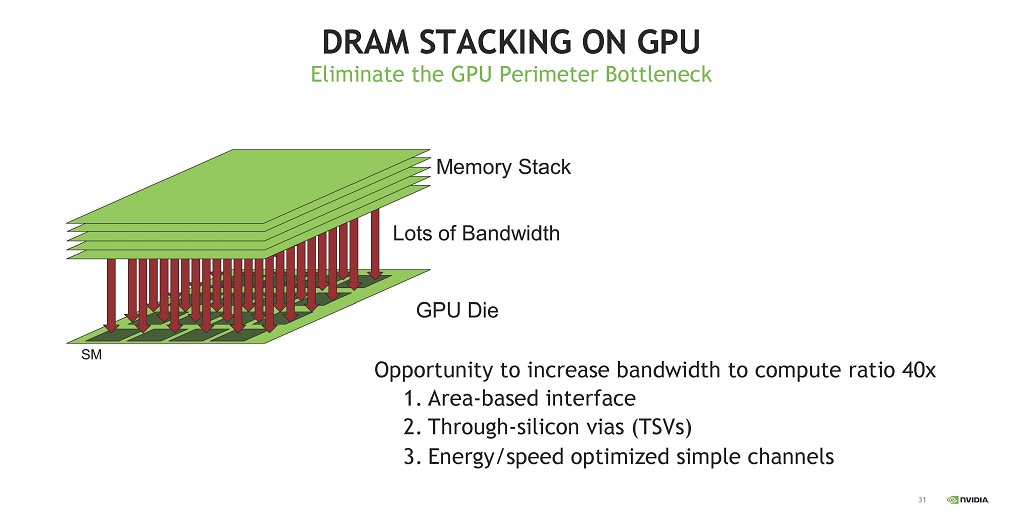 |
| 図23 GPUの上にHBMをスタックすればHBMとの接続バンド幅を40倍に増加させられる。 |
研究上の挑戦としては、
- energy/bitを1/10に低減する。
- 数100W級のGPUの発熱をDRAMスタックを通して排熱する
- GPUと複数のDRAMスタックを高信頼で組み立てる
- DRAM,GPUも歩留まりやECCをマネージする
- GPUとDRAMのバンクやインタフェースのアーキテクチャの最適化
- プログラマにDRAMのローカリティーを表現する方法の提供
- より複雑なメモリ階層でのローカリティーの最適化アルゴリズム
などがある。
 |
| 図24 その他の性能改善の可能性のある項目 |
GPUメモリと性能を改善する3つの道は,オフチップのDRAMのテクノロジとアーキテクチャの改善,オンパッケージのアーキテクチャを改善してより大容量のキャッシュの提供,キャッシュの効率を改善してオフチップの配線の必要バンド幅を低減などが挙げられているが,いずれもなかなか容易ではない。
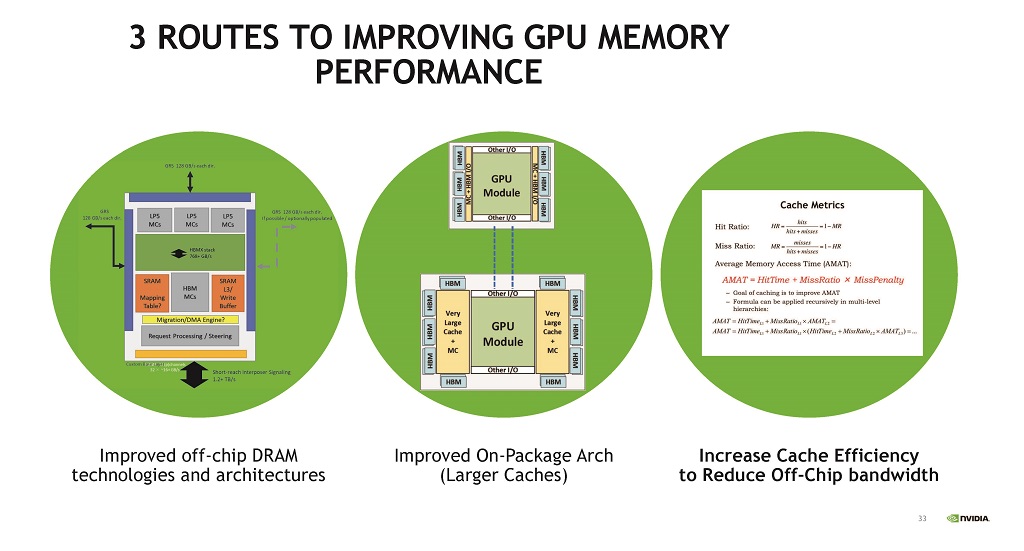 |
| 図25 GPUとメモリと性能を改善する3つの道は,オフチップのDRAMのテクノロジとアーキテクチャの改善,オンパッケージのアーキテクチャを改善してより大容量のキャッシュの提供,キャッシュの効率を改善してオフチップの配線の必要バンド幅を低減が考えられる。 |
ハードウェアによるキャッシュマネジメント以外では,プログラマにキャッシュのやり方を明示的に操作させるアーキテクチャが話題になっている。この方法は2次キャッシュの内容の吐き出しを明示的にコントロールするもので,2次キャッシュの入れ替えがより柔軟になるというメリットがあり,ディープラーニングとの適合性は高いと思われる。L2キャッシュの入れ替えに当たって,Eviction Controlという機構をアクセスする。Ampere GPUではL2キャッシュはEVICT-LAST,EVICT_NORMAL,EVICT_FIRSTという指定ができる。
この方法はL2キャッシュの置き換えがフレキシブルになり,ディープラーニングとの相性は良いが,どのように値をコントロールすべきか,まだ,良く分かっていない。また,Classの設定は,L2キャッシュの容量やメモリのフットプリントに対する依存性が大きく,設定のやり方が難しいようである。
 |
| 図26 L2キャッシュマネジメント L2キャッシュマネジメントは新たな仕掛けでL2キャッシュの入れ替えに新しい機能を加えるが,どのように使うか,最適化すべきかが,まだ,分かっていないという。 |
NVIDIAはHBMのキャッシュをうまく使う研究を行っている。問題を限定すれば性能向上やメモリバンド幅の低減に成功するケースもあるが,環境が変わると,Eviction(吐き出し)アルゴリズムの学習をやり直す必要があるなど,まだ,広く使える状態にはなっていないようである。
なお,この記事では省略したが,Keckler氏の発表では最後の部分にPythonとLegateを組み合わせてスーパーコンピューティングを行うという説明がある。Pythonだけでは並列度の高い計算は記述できず高い性能が出ないが,NVIDIAの開発しているLegateと組み合わせると128GPU程度の計算を高い並列度で実行することができるようになり,大幅にスーパーコンピューティングの性能が向上するとのことである。
以上
特別イベント

寄稿者
![]() 西克也
西克也
西克也はフェアチャイルド社、クレイ・リサーチ社、ベストシステムズ社など、30年以上に渡ってHPCに関する仕事に従事している。Hpcwire Japanの編集長として記事の作成と翻訳を行っている。
![]() 島田佳代子
島田佳代子
1999年~2007年まで英国在住。2001年よりスポーツ、旅、ビジネス、映画など幅広いジャンルで執筆活動を開始し、Hpcwire Japanでは主に日本のHPC業界が世界に誇る研究者、開発者の方々のインタビューを担当。
![]() 小柳義夫
小柳義夫
小柳義夫氏は40年以上に亘ってHPCに携わってきた研究者であり、日本のHPC業界における生き字引として有名。現在 高度情報科学技術研究機構に所属し、産業界のHPC推進にあたっている。
![]() 小西史一
小西史一
小西史一は、理化学研究所、東京工業大学においてHPCおよびバイオインフォマティクスに関する研究と教育に携わってきた研究者。2012年からフォトグラファーとしての活動を開始し、現在はIT技術・セキュリティのコンサルティング業務に携わっている。