
HPCの歩み50年記事一覧

スパコンリスト日本

記事寄稿について

光インターコネクトの可能性を示すGoogleのAIスーパーコンピュータ
Agam Shah オリジナル記事

銅線ではコンピュータ間のデータ移動速度に限界があり、光への移行が最終的にAIとハイパフォーマンス・コンピューティングを前進させることになるだろう。エネルギー効率の良い方法でゼタスケール・コンピューティングに到達するためには、光インターコネクトが必要になることは、主要なチップメーカー各社が一致しており、先月、AMDのリサ・スーCEOもこの意見を共有している。
Googleは、自社のデータセンターでサーバーとチップ間の光インターコネクトを実験・導入している。先週発表されたarXiv論文では、その実装の詳細と、性能と電力効率の向上が紹介されている。
Googleは、同社のTensor Processing Unit(TPU)を4,096個搭載したスーパーコンピュータ「TPU v4」について語った。GoogleはTPUチップ上でAIアプリケーションを稼働させており、その中には同社のAIを搭載した検索エンジンの初期イテレーションであるBardも含まれている。同社は、Google Cloudに数十台のTPU v4スーパーコンピューターを導入している。
Googleがスーパーコンピューティング・インフラについて論文を発表したのは、MicrosoftがChatGPTを動かすNvidia GPUを搭載したAzureスーパーコンピュータについてノイズを出した後だ。それに比べ、GoogleはWebアプリケーションへのAIの導入に保守的だったが、Bing検索エンジンにOpenAIのGPT-4大規模言語モデルを導入したMicrosoftに追いつこうとしているところである。
光接続は、何十年も前から通信ネットワーク上の長距離通信に使用されてきたが、現在では、データセンターでの短距離通信に使用するための準備が整ったと考えられている。BroadcomやAyar Labsといった企業が、光インターコネクトのための製品を作っている。
Googleのスーパーコンピュータ「TPU v4」は2020年に配備され、この論文は、長年にわたる性能向上を測定する回顧的な作品として書かれたものだ。
このスーパーコンピュータは、「回路スイッチ型の光インターコネクトを備えた最初のもの」だと、Googleの研究者はHPCwireに電子メールで語っている。4,096個のTPUをホストする合計64個のラックと、システム全体で全ラックを接続する48個の光回路スイッチを備えていた。Googleの計算では、光コンポーネントはシステムコストの5%未満、システムで消費される電力の2%未満を占めるという。
TPU v4チップはTPU v3チップを2.1倍上回り、ワットあたりの性能を2.7倍向上させたと、Googleの研究者は述べている。「TPU v4スーパーコンピュータは、4096チップで4倍大きいため、全体として~10倍速く、OCSの柔軟性とともに大規模な言語モデルに役立ちます」と研究者は論文で述べている。
Googleは、アプリケーションに応じてシステムを展開し、その場でトポロジーを適応させる際の光学の柔軟性を強調した。光インターコネクトとその高い帯域幅により、各ラックを独立して展開することができ、生産が完了すると各ラックをプラグインすることができた。
「インクリメンタルな展開により、TPU v4スーパーコンピュータの生産利用までの時間、ひいては費用対効果が大幅に改善されました 」と研究者は述べている。
1,024個のTPUチップを搭載した前身のスーパーコンピュータ「TPU v3」では、まったく別の話であった。「TPU v3システムは、1,024個のチップとケーブルがすべて取り付けられ、テストされるまでは使用できませんでした。いかなる部品も納期が遅れれば、スーパーコンピュータ全体が動かなくなってしまうのです」と、研究者たちは書いている。
Googleは、電子回路をベースとするNvidiaのNVSwitchと比較して、光回路スイッチングを次世代インターコネクトと説明している。光スイッチは、「ミラーで接続されたファイバーであり、ファイバーを走るあらゆる帯域幅を、今日4,096個のチップにまたがるOCSによって入力ファイバーと出力ファイバーの間で切り替えることができます」と Googleの研究者は述べている。
このインターコネクトは、より多くのTPUコアに拡張可能で、1秒間に複数テラビットのリンクを確立することができる。
研究論文では、TPU v4チップを、同じく2020年に採用され、7nmプロセスで作られたNvidiaのA100チップと比較している。Nvidiaの最近のHopper H100は、今年の初めまでクラウドで利用できなかったため、Googleは次世代TPU v5をH100と比較する選択肢を残している。
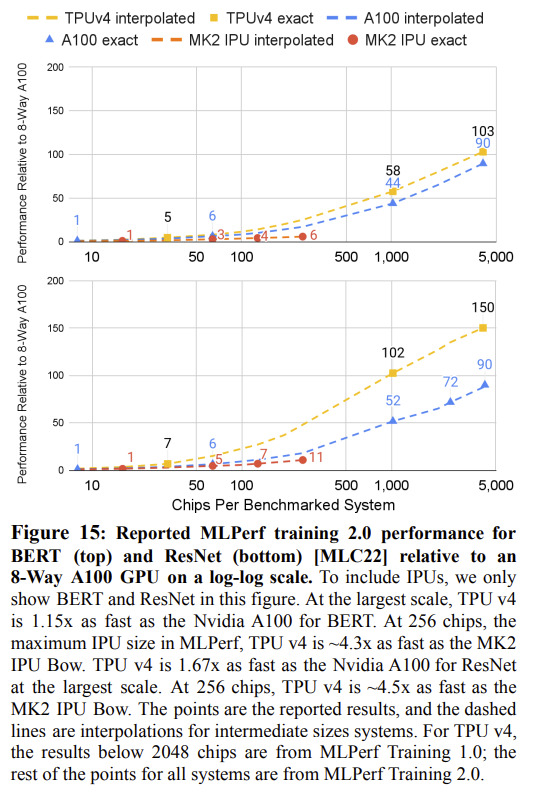 |
|
| TPUシステム対A100システムのMLPerf比較。画像は研究者の提供 | |
Googleは自社のチップがA100とGraphcore社のAIチップを凌駕できると主張したが、研究者はMLPerfのようなAIベンチマーク(学習と推論のピーク性能を測定する)についても見解を述べている。Googleの研究者は、そのTPU v4チップは、実世界のシナリオにおいて、コンピューティングリソースをより良く、より適切に使用すると主張している。
「HPCコミュニティは、Linpackの性能と実際のアプリケーションで発揮される性能とのギャップに精通しており、ACM Gordon Bell賞はそれを認識しています。直近の受賞者は、複数のHPCスーパーコンピュータでLinpackのflops/秒の5%~10%を達成しています。論文でも触れられているように、AIのピーク性能とデリバリー性能は必ずしも相関関係があるわけではありません。大規模な言語モデルが、50日間にわたりTPU v4のピークハードウェア性能の平均58%でトレーニングしたことを誇りに思います」と、Googleの研究者はHPCwireの質問に対して述べている。
TPU v4スーパーコンピュータは、SparseCoresを搭載している。SparseCoresは、AI演算処理の多くが行われる広帯域メモリに近い中間的なチップである。SparseCoresのコンセプトは、AMD、Intel、Qualcommなどが研究している新しいコンピューティングアーキテクチャをサポートするもので、データにより近いコンピューティングと、メモリへのデータの出し入れのオーケストレーションに依存している。
この論文では、TPU v4スーパーコンピュータとNvidiaのA100を性能とエネルギー効率の指標で比較するために多くのページを割いている。しかし、Googleは通常、TPUで処理するためにアプリケーションを最適化しているため、この比較は単純なものではあり得ない。
Googleは光回路スイッチを他の用途にも使用しており、昨年論文で詳述しているが、大規模な光インターコネクトを実現したのは今回が初めてである。
特別イベント

ISC 2026
6月 22 - 6月 26
International Conference for High Performance Computing, Networking, Storage & Analysis (SC26)
11月 15 - 11月 20
寄稿者
![]() 西克也
西克也
西克也はフェアチャイルド社、クレイ・リサーチ社、ベストシステムズ社など、30年以上に渡ってHPCに関する仕事に従事している。Hpcwire Japanの編集長として記事の作成と翻訳を行っている。
![]() 島田佳代子
島田佳代子
1999年~2007年まで英国在住。2001年よりスポーツ、旅、ビジネス、映画など幅広いジャンルで執筆活動を開始し、Hpcwire Japanでは主に日本のHPC業界が世界に誇る研究者、開発者の方々のインタビューを担当。
![]() 小柳義夫
小柳義夫
小柳義夫氏は40年以上に亘ってHPCに携わってきた研究者であり、日本のHPC業界における生き字引として有名。現在 高度情報科学技術研究機構に所属し、産業界のHPC推進にあたっている。
![]() 小西史一
小西史一
小西史一は、理化学研究所、東京工業大学においてHPCおよびバイオインフォマティクスに関する研究と教育に携わってきた研究者。2012年からフォトグラファーとしての活動を開始し、現在はIT技術・セキュリティのコンサルティング業務に携わっている。