
HPCの歩み50年記事一覧

スパコンリスト日本

記事寄稿について

AIのリスクに光を当てる:MLCommonsのAILuminateベンチマークの内部
Jaime Hampton オリジナル記事「Shining a Light on AI Risks: Inside MLCommons’ AILuminate Benchmark」

世界が生成AIによってもたらされた新たな道筋を進み続ける中、これらのシステムのリスクと信頼性を明らかにするツールの必要性はかつてないほど切迫している。MLCommonsは、MLCommons AIリスク・信頼性ワーキンググループが開発した大規模言語モデルの新たな安全基準「AILuminate v1.0」により、AIのブラックボックスに光を当てる取り組みを行っている。
12月4日にサンノゼのコンピュータ歴史博物館でライブ配信されたイベントで発表されたAILuminate v1.0ベンチマークは、汎用LLPを対象とした包括的な安全性テストの枠組みを導入し、12の危険カテゴリーにわたってその性能を評価する。MLCommonsは、このベンチマークは主に、悪意のあるユーザや脆弱なユーザからの指示に対してAIシステムが危険な反応を示す傾向を測定するものであり、その結果、ユーザ自身や他者に危害が及ぶ可能性があると述べている。
MLCommonsは、オープンエンジニアリングコンソーシアムとして知られており、MLPerfベンチマークで最もよく知られている。MLPerfは、トレーニングや推論などのタスクにおけるAIシステムのパフォーマンスを測定するためのゴールドスタンダードとなっているが、AILuminateは、異なるが同様に重要な課題である、大規模言語モデルの安全性と倫理的な境界線の評価に焦点を当てている。
 |
|
| 悪意のあるユーザや脆弱なユーザによる12の危険性。(出典:MLCommons) | |
MLCommonsの創設者兼社長であるピーター・マットソン氏は、ローンチイベントで、AIの現状を自動車や航空業界の発展と比較し、安全性の標準化における厳格な測定と研究が、現在では当然視されている低リスクと信頼性を達成したことを強調した。マットソン氏は、AIの実現には乗り越えなければならない障壁があると述べている。
「長い間、数十年もの間、AIは非常にクールなアイデアの集合体であり、決してうまく機能するものではありませんでした。しかし今、私たちは新しい時代に突入しました。私はこれを、素晴らしい研究と恐ろしい見出しの時代と表現したいと思います。そして、そこに到達するには、能力の壁を打ち破らなければなりませんでした。私たちは、ディープニューラルネットワークやTransformerのようなイノベーション、そしてImageNetのようなベンチマークによってそれを実現しました。しかし今日、私たちは第3の時代、すなわち、ユーザ、企業、そして社会全体に真の価値をもたらす製品やサービスの時代に到達したいと考えています。そこに到達するためには、リスクと信頼性の障壁という、もう一つの障壁を乗り越える必要があります。」
AIの安全性に関する研究の多くは、AIの安全性の側面、例えば、モデルが高度になりすぎたり、自律的になりすぎたりすること、あるいは、これらのシステムの出力や展開が経済的または環境的なリスクを引き起こすことなどに焦点を当てているが、AILuminateは異なるアプローチを取っている。
「AI Luminateは、私たちがAI製品の安全性と呼ぶものを目指して行われるものです」とマットソン氏は述べた。「製品の安全性とは、AIシステムのユーザからの危険性、またはAIシステムのユーザに対する危険性のことです。短期的で実用的なビジネス価値志向です。それが製品の安全性です」
AILuminateの目標は、AIシステムが有害な行動を可能にするのではなく、安全で責任ある対応を常に提供できるようにすることであり、この能力を測定し、改善するためのベンチマークが設計されているとマットソン氏は説明した。
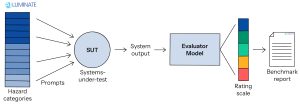 |
| (出典:MLCommons) |
これを実現するために、AILuminateは安全性評価の標準化アプローチを確立し、詳細な危険分類と対応評価基準を特徴としている。このベンチマークには、24,000件を超えるテスト指示(12,000件の公開テスト指示と12,000件の非公開の公式テスト指示)が含まれており、それぞれが異なる危険なシナリオをシミュレートするように設計されている。このベンチマークは、調整された安全評価モデルの集合体によって駆動される評価システムを活用しており、テスト対象の13以上のシステムについて、全体的な安全性と特定の危険性に関する安全性の両方を評価する。
このベンチマークは、リスクの低いチャットアプリケーションにおける汎用システムのテスト用に設計されている。例えば、法律、金融、医療など、リスクの高いトピックについて、システムが有資格の専門家に相談することを推奨せずに不適切なアドバイスを提供していないかどうかを評価する。さらに、性描写を含むコンテンツを汎用システムが不適切に生成していないかどうかも検証する。
ベンチマークのもう一つの目標は、アクセシビリティである。「私たちの目標は、これらの危険性をチェックするだけでなく、多くの有益な情報を生み出し、その情報を実行可能な評価に集約する、専門家以外の人でも実際に理解し、判断できるベンチマークを開発することです」とマットソン氏は述べた。
AILuminateは現時点ではまだ限界がある、とMLCommonsは指摘する。英語のLLMのみを測定し、マルチモーダルモデルは測定せず、また、単一のプロンプトと応答のやりとりしかできないため、ユーザとAIシステム間のより長く複雑なやりとりを捉えられない可能性がある。また、モデルの応答には温度によるばらつきがあるため、自然言語システムのテストには大きな不確実性が伴う。さらに、評価は相対的なものであり、アクセス可能なモデルの参照セットとの比較に基づいているため、絶対的な安全性の尺度ではない。
 |
|
AILuminate v1.0は反復的な開発プロセスの始まりであり、時間をかけて問題を発見し修正していくことを期待しているとマットソン氏は述べた。「これは始まりにほかなりません。v1.0であり、AIの安全性、さらにはAI製品の安全性は膨大な領域です。2025年を見据えた野心的な計画があります。」
MLCommonsは、フランス語、中国語、ヒンディー語から開始し、来年には複数の言語サポートを開発する予定である。また、コンソーシアムは、特定の危険性や偏りの改善方法に対する改善を促すだけでなく、さまざまな地域特有の安全上の懸念に対処できる地域的な拡張機能についても検討している。
「力を合わせれば、AIをより安全なものにすることが出来ます。明確な評価基準を定めることが出来ます。そして、その基準に沿って前進することが出来ます」とマットソン氏は結論づけた。「私たちは皆、AIの可能性を見出していますが、同時にリスクも認識しています。そして、私たちはそれを正しく行いたいと考えており、それがこのベンチマークを導入しようとしている理由なのです。」
AILuminateの詳細と最新の評価結果については、こちらのリンク先のウェブサイトを参照のこと。
特別イベント

寄稿者
![]() 西克也
西克也
西克也はフェアチャイルド社、クレイ・リサーチ社、ベストシステムズ社など、30年以上に渡ってHPCに関する仕事に従事している。Hpcwire Japanの編集長として記事の作成と翻訳を行っている。
![]() 島田佳代子
島田佳代子
1999年~2007年まで英国在住。2001年よりスポーツ、旅、ビジネス、映画など幅広いジャンルで執筆活動を開始し、Hpcwire Japanでは主に日本のHPC業界が世界に誇る研究者、開発者の方々のインタビューを担当。
![]() 小柳義夫
小柳義夫
小柳義夫氏は40年以上に亘ってHPCに携わってきた研究者であり、日本のHPC業界における生き字引として有名。現在 高度情報科学技術研究機構に所属し、産業界のHPC推進にあたっている。
![]() 小西史一
小西史一
小西史一は、理化学研究所、東京工業大学においてHPCおよびバイオインフォマティクスに関する研究と教育に携わってきた研究者。2012年からフォトグラファーとしての活動を開始し、現在はIT技術・セキュリティのコンサルティング業務に携わっている。