
HPCの歩み50年記事一覧

スパコンリスト日本

記事寄稿について

エヌビディアの最新の基礎モデルは、実際に「Strawberry」と綴る
Jaime Hampton オリジナル記事「Nvidia’s Newest Foundation Model Can Actually Spell ‘Strawberry’」

エヌビディアの新しいAIモデルは、「strawberry」という単語に含まれるRの数を正確に認識できるが、これはオープンAIのGPT-4oモデルがまだ達成できていない機能である。「ストロベリー問題」として知られるこの問題では、GPT-4oや他のいくつかの確立されたモデルは、「strawberry」にはRが2つしかないという誤った答えを出すことが多い。
10月15日にHugging Faceで発表されたエヌビディアの新しいモデルは「Llama-3.1-Nemotron-70B-Instruct」と呼ばれ、メタのオープンソース「Llama」基盤モデル、特に「Llama-3.1-70B-Instruct Base」をベースとしている。AIモデルの「Llama」シリーズは、開発者が構築するためのオープンソース基盤として設計された。
Hugging Faceのモデルページでは、Nemotron-70Bがいくつかの異なるベンチマークにおいてGPT-4oやAnthropicのClaude 3.5 Sonnetを上回っていると主張している。Nemotron-70Bは、Chatbot Arena Hardベンチマークで85.0、AlpacaEval 2 LCで57.6、GPT-4-Turbo MT-Benchで8.98を獲得している。また、同ページでは、Nemotron-70Bは人間のフィードバックに基づく強化学習と、エヌビディアの新しいアライメント技術であるHelpSteer2-preference(同社によると、指示にさらに忠実に従うようにモデルを訓練する)を用いて微調整されたと記されている。
この場合、ベンチマークの結果は、AI研究のコンセプトであるアライメントの有効性を示すものであり、信頼性と安全性に対するユーザの要求や期待にモデルの出力が対応する効果を説明するものである。アライメントは、カスタマイズを強化することで改善でき、企業は特定のユースケースに合わせてAIモデルを調整することができる。最終的な目標は、正確で役立つ応答を提供し、幻覚を排除することである。
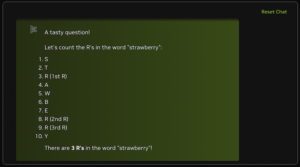 |
|
| Nemotron-70Bモデルは「ストロベリー問題」を簡単に解決し、その高度な推論能力を示した。 | |
しかし、大規模言語モデルのベンチマークはまだ研究途上の分野であり、特定のモデルの有用性は個々のアプリケーションでテストする必要があることに留意すべきである。
現在、AIハードウェア市場を独占しているエヌビディアだが、Nemotronモデルがベンチマークで好成績を維持し続けるようであれば、すでに活況を呈しているLLM分野でさらに競争が激化する可能性がある。Nemotronモデルは、同社がAIソリューションのワンストップショップとなることを目指していることを示している。
エヌビディアがAIモデルに参入するにあたって重要な要素のひとつが、NIM(Nvidia inference microservices)というダウンロード可能なコンテナで、顧客がAIとやりとりするためのインターフェースを提供する。NIMはガードレールと最適化を使用して、複数のLLMの微調整を可能にする。エヌビディアは、NIMはインストールが簡単で、基礎となるモデルデータの完全な制御を提供し、予測可能なスループットとレイテンシ性能を実現すると述べている。
OpenAIは今月、o1という新しいモデルをリリースした。興味深いことに、このモデルには「ストロベリー」というコードネームが付けられている。高度な推論能力を備えたモデルシリーズの第一弾となるこのモデルは、o1-previewとo1-miniの2つのバージョンが用意され、有料のChatGPTユーザを対象にプレビュー版として提供されている。OpenAIは、特注のデータセットでトレーニングされた新しいストロベリーモデルが、多くのSTEM科目において博士号レベルの能力を発揮していると主張している。
そして、心配しないでほしい。この機能は、「strawberry」という単語に含まれるRの数も正確に教えてくれる。
特別イベント

寄稿者
![]() 西克也
西克也
西克也はフェアチャイルド社、クレイ・リサーチ社、ベストシステムズ社など、30年以上に渡ってHPCに関する仕事に従事している。Hpcwire Japanの編集長として記事の作成と翻訳を行っている。
![]() 島田佳代子
島田佳代子
1999年~2007年まで英国在住。2001年よりスポーツ、旅、ビジネス、映画など幅広いジャンルで執筆活動を開始し、Hpcwire Japanでは主に日本のHPC業界が世界に誇る研究者、開発者の方々のインタビューを担当。
![]() 小柳義夫
小柳義夫
小柳義夫氏は40年以上に亘ってHPCに携わってきた研究者であり、日本のHPC業界における生き字引として有名。現在 高度情報科学技術研究機構に所属し、産業界のHPC推進にあたっている。
![]() 小西史一
小西史一
小西史一は、理化学研究所、東京工業大学においてHPCおよびバイオインフォマティクスに関する研究と教育に携わってきた研究者。2012年からフォトグラファーとしての活動を開始し、現在はIT技術・セキュリティのコンサルティング業務に携わっている。