
HPCの歩み50年記事一覧

スパコンリスト日本

記事寄稿について

Arm、新NeoverseプラットフォームでHPCをターゲット
Tiffany Trader

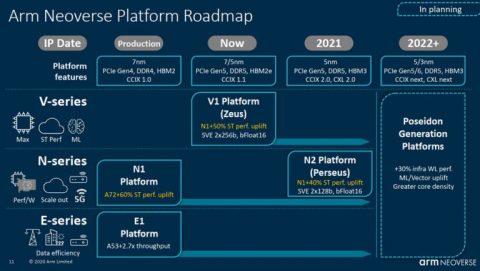
英国を拠点とする半導体設計会社Armは、Neoverseロードマップの詳細を明らかにし、Armの第2世代NシリーズプラットフォームであるV1(コードネームZeus)とN2(コードネームPerseus)を発表した。チップIPベンダーは、この新しいプラットフォームがNeoverse N1と比較して、それぞれのシングルスレッド性能が50%および40%向上すると述べている。
HPCウォッチャーにとっての大きなニュースは、Neoverse V1がScalable Vector Extensions (SVE)をサポートしたことだ。これは256ビット幅の2つのベクトルとして実装され、より広いベクトル単位でSIMD整数命令、bfloat16命令、浮動小数点命令の実行を可能にする。SVEはユニットの幅に依存しないように設計されているため、一つのプラットフォーム上でSVE用にコンパイルされたアプリケーションは、128ビットから2,048ビットの幅(128ビット刻み)を使用できる有効なSVE実装上で実行される。
「SVEを使用することで、効率的な実行とともにソフトウェアコードの移植性と長寿命化を実現しています」と、Armのインフラストラクチャ事業部門のシニアバイスプレジデント兼ジェネラルマネージャーであるChris Bergeyは述べている。
 |
|
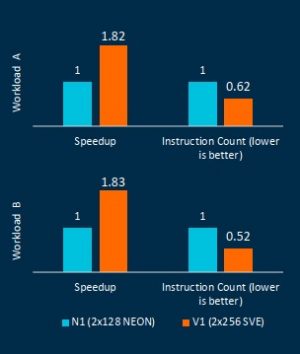
| 予測されるパフォーマンスの向上。幅の広いベクトルは、アプリケーションのパフォーマンスを向上させる。出典:Arm | |
V1 Neoverseコアの新しいSVE機能は、富士通のA64FXプラットフォームでのArmの経験を活かしたもので、SVE対応プロセッサは、世界トップランクで初のArmベースのスーパーコンピュータ「富岳」の心臓部となっている。
ArmのHPCビジネスリーダーであるBrentGordaによると、Arm社のパートナー企業の多くが、データ分析やハイパフォーマンスコンピューティングのワークロードを目的としたNeoverse V1ベースのソリューションを開発しているという。その一つがSiPearlで、ヨーロッパのエクサスケール計画を支える第一世代サーバプロセッサにZeusコアを採用している。
Gordaは、スーパーコンピューティング以外にも、メディア処理、暗号化/復号化、ネットワーク処理、エッジ環境でのSVEの応用を挙げている。
先週メディア向けに開催されたプレブリーフィングで、ArmはV1の初期エミュレーション結果を発表し、実装レベルではN1よりも高速化していることを示した(上の棒グラフ参照)。
Silicon partnersは、SVEの電圧と周波数の遷移を完全に制御できるようになる、とBergeyは述べた。これにより、富士通のA64FX CPUと同様に、SVEコードを実行しながらフル周波数で動作させることが可能になる。
Bergeyは、ArmはCCIXとCXLの両方に投資し、相互接続のロードマップを進めていると述べている。
CCIXは双方向コヒーレント通信に使用され、その使用方法には多くの柔軟性があるとBergeyは語る。
従来のケースはマルチソケットコンピューティングだが、チップレットのユースケースも出てきている。「ダイのサイズが小さくなり、歩留まりが上がり、コストが下がり、コア数とパフォーマンスを向上させ続けることができるという利点を聞いたことがあるでしょう」とBergeyは述べた。
また、Armは、緊密に結合されたヘテロジニアスコンピュートも探求している。「ムーアの法則のスケーリングが鈍化する中、ARMのCPU複合体と様々なアクセラレータやメモリとのチップ間結合に関心が集まっています」とBergeyは語っている。
 |
|
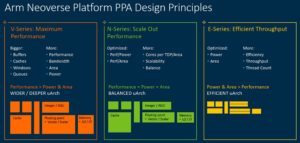
| Nシリーズ、Vシリーズ、Eシリーズの比較(出典:Arm) | |
同社は同様に、メモリコヒーレントアタッチメントを提供するCXLも計画しているという。Bergeyは、「最も期待されている[であろう]メモリプールと拡張」というユースケースを強調している。
これにより、「接続された一連のノード間でメモリの大規模なプールを共有することが可能になりますが、1つのノードに大量の新興メモリをアタッチすることを意味する場合もあります」と彼は述べ、機械学習のトレーニングや推論に役立つことを強調している。
V1が最も要求の厳しいワークロードに最適なパフォーマンスを重視しているのに対し、N2はスケールアウトのパフォーマンスに対応している。「V1のようなスレッドあたりのパフォーマンスはありませんが、一定のTDPでより多くのコアをサポートします」とBergeyは述べている。
彼は、CPUあたりのコア数にハードな制限はないが、顧客には最適化したいTDPがあり、それがコア数の目標と結びついていると付け加えた。
「私たちは、電力とエリアごとのパフォーマンスを中心に最適化しています。これにより、TDPあたりのコア数を増やすことができます。それが250ワットのクラウドSOCや、20ワットの5G基地局SOCであろうと」と彼は述べた。
Armは、V1 IPを7nmと5nmの両方のプロセスノードに実装し、顧客のタイムフレームに応じてこれら2つのノードのいずれかを利用することを期待している。
Bergeyは、V1とN2で予測している性能向上はIPCベースのものであり、結節点には関係ないと指摘している。
Armサーバチップの牽引が続いている。AWSは昨年、N1ベースのGraviton2プロセッサをデビューさせた。Ampereは今年末に128コアのN1プロセッサ(Altra Max)のサンプリングを行う予定である。冨岳は、カスタムArmプラットフォーム(富士通と理研が開発したA64FX)を活用して、複数のベンチマーク記録を設定し、COVID-19との戦いを支援した。Marvellは、Arm実装のThunderX(2018年に初のペタスケールArmシステムを主張し、他にもいくつかの大きな設計上の勝利を積み重ねた)で成功を収めていたが、最近セミカスタムへの移行を発表した。
この勢いは、チップとデータセンターの会社であるNvidiaの注目を集めている。すでにArmプラットフォームへのサポートを強化しているNvidiaは、同社自身を追求することにした。規制当局の承認待って、Nvidiaは親会社であるSoftbankのIPチップ部門を400億ドルで買収する予定だ。
 |
特別イベント

ISC 2026
6月 22 - 6月 26
International Conference for High Performance Computing, Networking, Storage & Analysis (SC26)
11月 15 - 11月 20
寄稿者
![]() 西克也
西克也
西克也はフェアチャイルド社、クレイ・リサーチ社、ベストシステムズ社など、30年以上に渡ってHPCに関する仕事に従事している。Hpcwire Japanの編集長として記事の作成と翻訳を行っている。
![]() 島田佳代子
島田佳代子
1999年~2007年まで英国在住。2001年よりスポーツ、旅、ビジネス、映画など幅広いジャンルで執筆活動を開始し、Hpcwire Japanでは主に日本のHPC業界が世界に誇る研究者、開発者の方々のインタビューを担当。
![]() 小柳義夫
小柳義夫
小柳義夫氏は40年以上に亘ってHPCに携わってきた研究者であり、日本のHPC業界における生き字引として有名。現在 高度情報科学技術研究機構に所属し、産業界のHPC推進にあたっている。
![]() 小西史一
小西史一
小西史一は、理化学研究所、東京工業大学においてHPCおよびバイオインフォマティクスに関する研究と教育に携わってきた研究者。2012年からフォトグラファーとしての活動を開始し、現在はIT技術・セキュリティのコンサルティング業務に携わっている。