
HPCの歩み50年記事一覧

スパコンリスト日本

記事寄稿について

セレブラス、数十億個のAI演算コアを搭載したAIメガクラスタを提案
Agam Shah オリジナル記事

チップメーカーのセレブラス社は、すでに世界最大とされる同社のチップにパッチを当て、AIコンピューティングのための史上最大のコンピューティングクラスタを構築している。
セレブラス社が呼ぶ手頃なサイズの「ウェーハスケールクラスタ」は、16個のCS-2をネットワーク接続してクラスタ化し、自然言語処理用の1360万コアを持つコンピューティングシステムを構築することができる。しかし待って、このクラスタはさらに大きくすることができる。
セレブラス社のCEOであるアンドリュー・フェルドマン氏は、HPCwireに対して「我々は最大192台のCS-2をクラスタに接続することができます」と述べている。
このAIチップメーカーは、AI Hardware Summitで発表を行い、同社はメガクラスタをつなぎ合わせる技術に関する論文を発表している。同社は当初、昨年のHot Chipsでこの技術をプレビューしていましたが、今週のショーでそのアイデアを拡大させた。
セレブラス社は、1つのCS-2システム(85万コアを搭載したウェーハサイズの1チップ)で、200億個のパラメータを持つAI自然言語処理モデルを訓練したと発表しており、これは1チップでの訓練としては過去最大となるものだ。セレブラス社の目標は、より大規模なモデルを、より短時間で訓練することなのである。
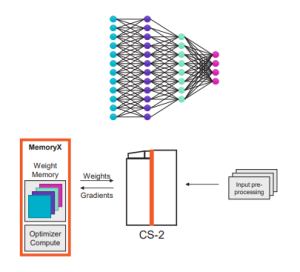 |
|
| ウェイトストリーミング – MemoryXでメモリと演算を分解(セレブラス社のグラフィック) | |
「私たちは、CS-2のクラスタ上で最大の自然言語処理ネットワークを実行しました。CS-2を追加していくと、リニアなパフォーマンスが得られることが確認できました。つまり、CS-2を1台から2台に増やすと、トレーニング時間が半分になるのです」とフェルドマン氏は語った。
自然言語処理モデルの大規模化は、より精度の高い学習を可能にする。現在、最大のモデルは10億以上のパラメータを持っているが、さらに大きくなりつつある。Googleの研究者は、5400億のパラメータを持つ新しいNLPモデルと、1兆のパラメータまで拡張できるニューラルモデルを提案した。
各CS-2システムは1兆以上のパラメータを持つモデルをサポートすることができ、セレブラス社は以前HPCwireに、CS-2システムは最大100兆のパラメータを持つモデルを扱うことができると語っている。このようなCS-2システムのクラスタは、より大規模なAIモデルを訓練するためにペアリングすることができる。
セレブラス社は、クラスタ内のCS-2システムを接続する「SwarmX」というファブリックを発表している。実行モデルは「ウェイトストリーミング」と呼ばれる技術に依存し、メモリ、コンピュート、ネットワークを別々のクラスタに分解することで、通信を素直にしている。
AIコンピューティングは、モデルのサイズと学習速度に依存するため、分解することで、ユーザは解決しようとする問題に対して必要なコンピューティングをサイズアップすることができるのだ。各CS-2システムでは、モデルのパラメータはMemoryXと呼ばれる内部システムに格納されており、これはどちらかというとシステムのメモリ的な要素となっている。この演算は85万個のコンピューティングコアで行われている。
「ウェイトストリーミング実行モデル では、コンピューティングとパラメータストレージを分解しています。これにより、コンピューティングとメモリが別々に独立してスケールすることができるのです」 とフェルドマン氏は語る。
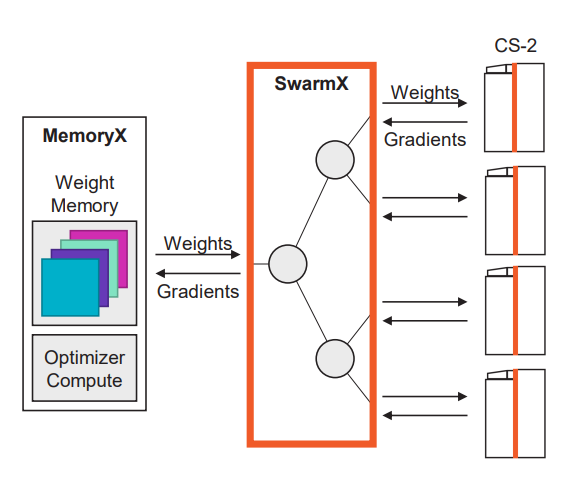 |
|
| SwarmXによるスケーリング | |
SwarmXインターコネクトは、CS-2システムの巨大なクラスタを接着する独立したシステムである。SwarmXは、MemoryXが1台のCS-2システムで動作するのとほぼ同様に、クラスタレベルで動作する。クラスタ内のメモリと演算要素を切り離し、演算コア数をスケールアップして大きな問題を解決することができるのだ。
「SwarmXは、MemoryXをCS-2のクラスタに接続します。このクラスタは、設定と操作が非常に簡単で、リニアな性能拡張を実現します」とフェルドマン氏は述べた。
SwarmXテクノロジーは、MemoryXに保存されたパラメータを、SwarmXファブリックを介して複数のCS-2にブロードキャスト送信する。パラメータは、クラスタ内のMemoryXシステム間でレプリケートされる。
クロスSwarmXファブリックは、トランスポートとして100GbEのマルチレーンを使用し、オンチップSwarmファブリックは、インシリコンワイヤーをベースにしているとフェルドマン氏は言う。
セレブラス社は、1台のCS-2システムで十分な問題を解決できるにもかかわらず、10億以上のパラメータを持つNLPモデルにCS-2クラスタシステムをターゲットにしている。しかし、セレブラス社は、1台のCS-2から2台のCS-2にクラスタ化することで、学習時間が半分になるなどとしている。
フェルドマン氏は、「16個または32個のCS-2のクラスタは、今日のGPUクラスタが800億パラメータのモデルを学習するよりも短い時間で、1兆パラメータのモデルを学習することができます」と述べている。
CS-2システムを2台購入すると、顧客に数百万ドルの負担を強いることになるが、プレゼンでセレブラス社は、こうしたシステムは、効率的にスケールアップできず、より多くのエネルギーを消費するクラスターのGPUモデルよりも安価であると主張した。
セレブラス社は、GPUコアが協調して応答時間を得るためには、数千のコアで同一に動作させる必要があると主張した。また、計算も複雑なコアのネットワークに分散させる必要があるため、時間がかかり、消費電力も非効率的だ。
それに比べてSwarmXは、学習用にデータセットを分割し、クラスタ内のCS-2システム間で重みを分散させるスケーラブルなブロードキャストを作成し、クラスタ全体で調整されたMemoryXキャッシュシステムに勾配を送り返す。
NLPモデルの学習をCS-1システムからクラスタに切り替えるには、Pythonスクリプトでシステムの数を変更するだけでよいのだ。
「GPT-3のような大規模な言語モデルも、キー操作ひとつでCS-2のクラスタに分散させることができます。それくらい簡単にできるんです」とフェルドマン氏。
特別イベント

寄稿者
![]() 西克也
西克也
西克也はフェアチャイルド社、クレイ・リサーチ社、ベストシステムズ社など、30年以上に渡ってHPCに関する仕事に従事している。Hpcwire Japanの編集長として記事の作成と翻訳を行っている。
![]() 島田佳代子
島田佳代子
1999年~2007年まで英国在住。2001年よりスポーツ、旅、ビジネス、映画など幅広いジャンルで執筆活動を開始し、Hpcwire Japanでは主に日本のHPC業界が世界に誇る研究者、開発者の方々のインタビューを担当。
![]() 小柳義夫
小柳義夫
小柳義夫氏は40年以上に亘ってHPCに携わってきた研究者であり、日本のHPC業界における生き字引として有名。現在 高度情報科学技術研究機構に所属し、産業界のHPC推進にあたっている。
![]() 小西史一
小西史一
小西史一は、理化学研究所、東京工業大学においてHPCおよびバイオインフォマティクスに関する研究と教育に携わってきた研究者。2012年からフォトグラファーとしての活動を開始し、現在はIT技術・セキュリティのコンサルティング業務に携わっている。