
HPCの歩み50年記事一覧

スパコンリスト日本

記事寄稿について

Nvidia、「1エクサフロップス」の新AIスパコンを発表、Grace-Hopperは「フル生産」
Tiffany Trader オリジナル記事

私たちHPC関係者は、「AIスーパーコンピュータ」という言葉に目を丸くすることがあるが、Nvidiaの新システムは、この呼び名にふさわしいかもしれない:DGX GH200 AIスーパーコンピュータ。台北で開催されたComputexで発表された、Nvidiaの急成長するポートフォリオに加わったこの最新システムは、256個のGrace-Hopper Superchipを36個のNVLinkスイッチで接続し、FP8 AIパフォーマンスで1エクサフロップス以上(FP64パフォーマンスで約9ペタフロップス)を実現している。さらに、144TBのユニファイドメモリ、900GB/秒のGPU間バンド幅、128TB/秒のバイセクショナルバンド幅を売りにしている。Nvidiaは、この製品を年末の運用開始に向けて準備している。
 |
|
| Nvidiaのジェンセン・フアンCEOがComputexのライブ配信でGrace Hopper Superchipを披露(5月29日、台北) | |
「我々は今、これを作り上げています」と、Nvidia CEOのジェンセン・フアン氏は、ライブ配信されたComputexの基調講演の中で語った。
Nvidia のハイパースケール・HPC担当VP兼ジェネラルマネージャーのイアン・バック氏は、先に行われたプレスブリーフィングで「我々はDGX GH200を、次世代の生成AIモデルや機能の開発のための新しいツールとして(設計)しました」と述べた。
ハイパースケーラのGoogle、Meta、Microsoftは、驚くことではないが、すでに列をなして、道端のタイヤを蹴るために並んでいる。AWSはその早期アクセスリストには入っていない。
「これらのハイパースケーラは、DGX GH200に最初にアクセスし、Grace Hopperの新機能と、すべてのGPUを1つにまとめて動作させるマルチノードNVLinkを理解するでしょう」とバックは言う。
このシステムの最大の特長は、Hopper GPUのHBMメモリと、ネットワーク上のすべてのGrace CPUのLPDDR5Xメモリを組み合わせた、144TBのアドレス可能メモリだ。
 |
|
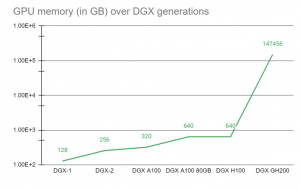
| 図は世代を超えたDGXのメモリを示している。DGX GH200には、Arm「Neoverse V2」CPUが480GBのLPDDR5Xメモリで、GPUはH100で、このバリエーションには96GBのHBM3メモリがそれぞれ搭載されている。ソース:Nvidia | |
DGX社長のチャーリー・ボイル氏は、このメモリの飛躍の意義を強調する(右図参照)。「アプリケーションによっては、”GPUアクセラレーションは素晴らしいが、アプリケーションの作業領域がGPUメモリに収まらなければならない”ということが、私たち(顧客)の歴史的な問題の1つでした。私たちには、Nvidia DGX H100(2つのIntel CPUと8つのH100 GPUを搭載)が提供する640ギガバイトのメモリよりはるかに大きい、加速する必要のある巨大なアプリケーションを持つ顧客がいます。」
「DGX GH200の基盤は、NVLink Switchシステムによるハードウェアと、CUDAプリミティブや通信ライブラリによるソフトウェアの両方で接続できることです、そうすることで、256個のディスクリート・コンピュータがあり、256個のオペレーティング・システムが動作していますが、我々のソフトウェアはそれらすべてと連携し、GPUの能力をすべて使ってメモリ空間全体で単一のジョブを起動することができ、以前はできなかった仕事を実現したり、(できた仕事を)非常に高速化したりできるのです。」とボイル氏は述べた。
Nvidiaは、高速化の可能性を示すために、以下の内部ベンチマーク予測を公開した。2.2倍(1T GPT3)から6.3倍(40TB Distributed Join)までの改善が見られる。
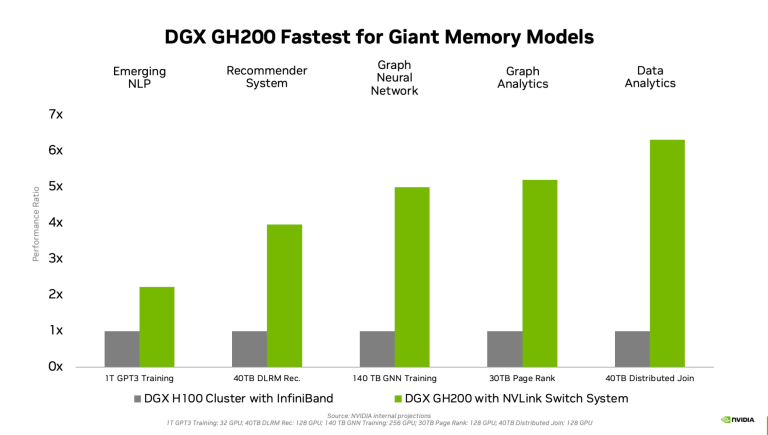 |
| InfiniBand を使用した DGX H100 クラスタから、完全に NVLink された DGX GH200 システムへのパフォーマンス比較。各ワークロードにおいて、GPUの数はグレーとグリーンの列で同じである。出典:Nvidia |
ボイル氏は、完全にNVLinkで接続されたDGX GH200の導入を、2016年のNVLinkの登場と比較した。「PascalでデビューしたNVLinkについては、これ以降のすべてのシステムにこの技術が搭載され、将来のNvidiaのシステム、将来のDGXシステムもこの外部NVLink機能を持つことになるでしょう」と述べた。
Nvidiaは、DGX GH200を256GPUのシステムとして提示しており、これはフルコンフィギュレーション版である。しかし、顧客は32ノード、64ノード、128ノードで購入することができ、途中のどの時点でもアップグレードが可能である。「32ノードで始めた人は、32ノードをもう1台買うことができます。すべてのスイッチングがすでにあるのですから」とボイル氏は言う。「ケーブル数本を接続すれば、64ノードになり、さらにアップグレードできるのです。」
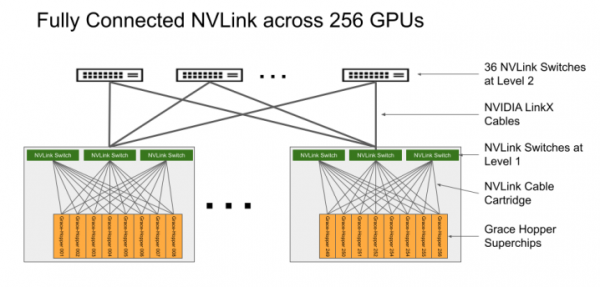 |
| フル構成(256GPU)のNvidia DGX GH200は、96個のL1 NVLink Switchesと36個のL2 NVLink Switchesを備えている。出典: Nvidia |
このDGX GH200は、Nvidia初のマルチラックDGXシステムである。各ラックには16台のGrace Hopper GH200ノードが搭載され、記事全文のヘッダー画像にあるように、256ノードで16ラックを埋め尽くす。InfiniBand を使用して複数の DGX GH200 を接続することで、より大規模なシステムも可能である。
実際、Nvidiaは、研究開発を進め、非常に大規模なAIモデルのトレーニングを強化するために、そのようなメガシステムの1つ、独自のDGX GH200ベースのAIスーパーコンピュータ「Helios」(この名前はHPCwireが予測したもの)を構築中だ。このシステムは、NvidiaのQuantum-2 InfiniBandネットワーキングを使用して、4つのDGX GH200システム(合計1024個のGrace Hopper Superchip)を接続する。Nvidiaは、このシステムを年内にオンライン化する予定だ。Heliosは、約4エクサフロップスのAI性能(FP8)を提供し、意図した使用例ではないが、従来のFP64性能で~34.8の理論ピークペタフロップスを提供することもできる。これは、Nvidiaが年2回のTop500リストに提出することを選択した場合、Top500リストの上位10位以内に入る候補となる。
新しいDGXのHGXバージョンはまだ発表されていないが、そのようなものが作られているようだ。NvidiaのDGX H100の基盤となるデザインで、Nvidiaがハイパースケーラーなどのシステムパートナーに提供して、仕様に合わせてカスタマイズしてもらう「HGX」と同様に、DGX GH200も同様に「HGX」形態で提供することを示したが、現時点では具体的に発表していないという。
この点についてバック氏は、「これらのハイパースケーラはすべて、独自のシステム設計とデータセンター設計を持っており、さらに最適化し、我々がDGXで構築したものを一般的な青写真として、独自のサーバーを構築し、データセンター・インフラにさらに最適化します」と述べ、「DGX内部のコンポーネントやビルディングブロック、断片は、ハイパースケーラに提供し、彼らがそれを手に入れ、カスタムデータセンターやサーバー設計のためにデザインを拡張できるようにしています」と付け加えた。その製品はHGXとして知られている。
とはいえ、Nvidiaはモジュールに特化したMGXサーバー仕様を発表している。MGXは「アクセラレイテッド・コンピューティングのためのオープンで柔軟、かつ前方互換性のあるシステム・リファレンス・アーキテクチャ」(バック氏)だという。
(非公式には、DGXの「D」はデータセンター、「H」はハイパースケール、「C」はクラウド、オムニバースをターゲットにした「OVX」があり、現在は「M」がモジュラーを意味するが、この使い方はNvidiaのPR部門が公式に認めているわけではない)。
モジュラーアーキテクチャーの設計は、Nvidiaやその他の製品(x86とArmの両方)のGPU、CPU、DPUを搭載することができるサーバーの設計(サーバーの機械、熱、電力の側面に関わる)を標準化するために作成された。「標準化することで、異なるコンポーネントは交換可能で、互換性があり、Nvidia製品やその他の製品に対応できるような将来性があります。新しいMGXリファレンス・アーキテクチャを使えば、わずか2ヶ月で、わずかなコストで新しい設計を行うことができる可能性があるのです」とバック氏は語り、現在のデザインプロセスでは1年半もかかってしまうことを挙げていた。
MGXは、以下のフォームファクターをサポートする:
- シャーシ:1U、2U、4U(空冷または液冷)
- GPU: 最新のH100、L40、L4を含むフルNvidia GPUポートフォリオ
- CPU Nvidia Grace CPU Superchip、GH200 Grace Hopper Superchip、x86 CPUs
- ネットワーキング Nvidia BlueField-3 DPU、ConnectX-7ネットワーク・アダプター
 |
| MGXサーバーの3つのデザイン 出典:Nvidia |
MGXがHGXとどう違うのか気になるところだが、Nvidiaはこのような説明をしている: 「MGXがNvidia HGXと異なる点は、Nvidia製品との柔軟で多世代にわたる互換性を提供し、システム構築者が既存の設計を再利用し、高価な再設計なしに次世代製品を容易に採用できるようにする点です。一方、HGXは、究極のAIおよびHPCシステムを構築するためにスケールアップするように調整されたNVLink接続のマルチGPUベースボードをベースにしています。」
つまり、HGXは「単なるベースボード」であり、MGXは「フルリファレンスアーキテクチャ」なのである。
MGXは、Open Compute ProjectおよびElectronic Industries Allianceのサーバーラックに対応しており、Nvidia AI Enterpriseを含むNvidiaのフルソフトウェアスタックがサポートされている。
ASRock Rack、ASUS、GIGABYTE、Pegatron、QCTおよびSupermicroは、MGXを製品設計プロセスに導入し始めた。そんな中、8月に発売予定の2つの製品が発表された: QCTのS74G-2UシステムはNvidia GH200 Grace Hopper Superchipを採用し、SupermicroのARS-221GL-NRシステムはNvidia Grace CPU Superchipを採用した。
もう1つのローンチパートナーであるソフトバンクは、日本各地のハイパースケール・データセンターに配備されるカスタムサーバーの製作にMGXを利用している。ソフトバンクが設計図を使って作成したデザインは、例えば、生成AIと5Gワークロードの両方をサポートするために、マルチユース設定でGPUリソースを動的に割り当てるのに役立つという。
また、NvidiaはGH200 Grace Hopper Superchipをフル生産していることを宣言した。Nvidiaは、Nvidia Grace、Nvidia Hopper、Nvidia Ada Lovelaceを含む最新のCPUおよびGPUアーキテクチャをベースに、生成的AIの需要をターゲットにした合計400以上のシステム構成を現在持っているという。これらのシステムはすべて、Nvidia AI Enterprise、Omnivere、RTXプラットフォームなど、Nvidiaのソフトウェアスタックと連携している。
DGX GH200の外部システムの勝利はまだ発表されていないが、同じGH200 Superchipを使用したGrace Hopper Superchipシステムが以前に複数発表されている。スイスのCSCSの新しいスーパーコンピューティングインフラであるAlpsは、Arm-GPUのハイブリッドアーキテクチャをデビューさせる予定であり、米国ではロスアラモス国立研究所に最初のGrace Hopperシステム「Venado」の到着に向けて準備中である。Grace Hopper Superchipsは、KAUSTの新しいスーパーコンピュータ「Shaheen III」にも搭載される。この3つのスーパーコンピュータはすべてHPEによって構築され、来年には完全に稼働して研究者に提供される予定である。
Nvidia は、DGX GH200 システムの消費電力に関する質問への回答を拒否し、同様に価格情報も提供しなかったが、すべての DGX 製品は、最終的な顧客価格の設定に役立つパートナーを通じて販売されていると指摘した。TDPについては、DGX H100を代理として、最大消費電力の10.2kWを32倍(256GPUにする)すると、326.4kWとなる。実際の消費電力スペックが公開されたら更新する。
特別イベント

寄稿者
![]() 西克也
西克也
西克也はフェアチャイルド社、クレイ・リサーチ社、ベストシステムズ社など、30年以上に渡ってHPCに関する仕事に従事している。Hpcwire Japanの編集長として記事の作成と翻訳を行っている。
![]() 島田佳代子
島田佳代子
1999年~2007年まで英国在住。2001年よりスポーツ、旅、ビジネス、映画など幅広いジャンルで執筆活動を開始し、Hpcwire Japanでは主に日本のHPC業界が世界に誇る研究者、開発者の方々のインタビューを担当。
![]() 小柳義夫
小柳義夫
小柳義夫氏は40年以上に亘ってHPCに携わってきた研究者であり、日本のHPC業界における生き字引として有名。現在 高度情報科学技術研究機構に所属し、産業界のHPC推進にあたっている。
![]() 小西史一
小西史一
小西史一は、理化学研究所、東京工業大学においてHPCおよびバイオインフォマティクスに関する研究と教育に携わってきた研究者。2012年からフォトグラファーとしての活動を開始し、現在はIT技術・セキュリティのコンサルティング業務に携わっている。